Introduction
As organisations lean more heavily on large language models (LLMs), the security landscape around them is shifting at unprecedented speed. Over just the past few months, new attack classes such as adversarial poetry, breakthrough research, and unexpected changes in model behaviour have reshaped how defenders evaluate and mitigate LLM misuse.
The result is an environment where:
- guardrails trained on static datasets quickly become outdated
- model updates can unintentionally reduce safety
- attackers increasingly exploit linguistic and cognitive biases, not just technical flaws
- defenders without automated systems will struggle to keep up
The challenge ahead is ensuring LLMs understand concepts, not just patterns. As adversarial metaphors demonstrate, a model that treats bomb-making as equivalent to baking can be manipulated not through code injection or crafted tokens—but through language itself.
AI Leaderboards December 2025
The latest round of testing revealed significant shifts in model performance and security:
- Claude Opus 4.5 enters the top 10 at first place in security scoring
- Gemini 3 performed strongly on raw capability but weakly on security, scoring only around 50, up from previous versions’ low-40s but still far behind OpenAI and Anthropic.
- GPT-5.1 showed improved performance (moving from the 66–68 range to around 70) but lost roughly four security points, a notable regression.
While it’s unclear whether OpenAI intentionally traded off security for performance, the rapid release cycle for 5.1 suggests targeted efficiency improvements. See Figure 1. One criticism of GPT-5 was extreme verbosity and many users found it burned tokens unnecessarily. Whatever tuning reduced that verbosity may have had side-effects.
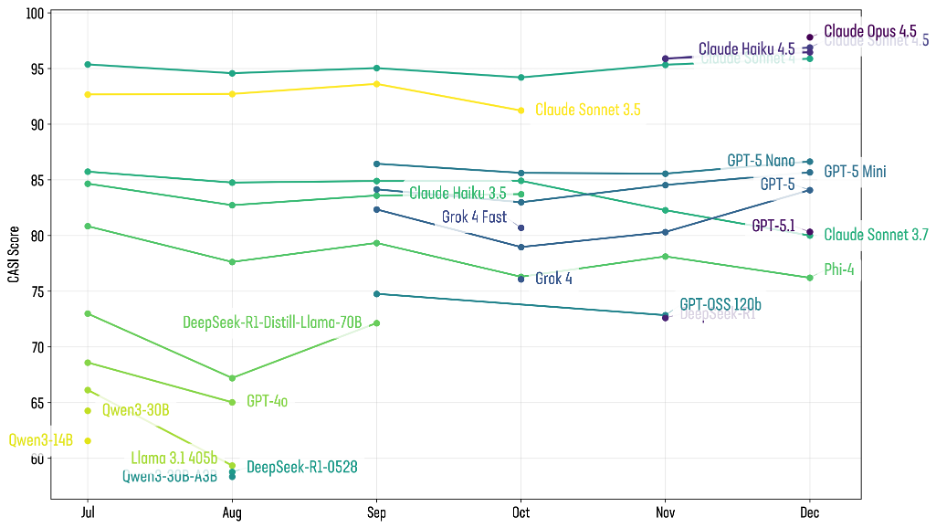
Figure 1: Visualization of the top CASI scoring AI models over the past 6 months
This tension between capability and safety is a recurring theme: small architectural changes can disproportionately impact jailbreak resistance.
To view the current scores and positions of the top 10 models, head over to the AI leaderboards to view both the CASI and ARS scores for this month.
Evaluating the Efficacy of AI Guardrails
Recent research highlights significant weaknesses in current AI “safety guardrail” systems designed to block harmful or disallowed content.1 The study evaluates ten publicly available guardrail models from major organisations including Meta, Google, IBM, NVIDIA, Alibaba, and the Allen Institute, using a large and diverse test set of 1,445 prompts across 21 adversarial attack categories. While many models perform well on publicly available attack prompts, the results reveal that this apparent strength is misleading: several guardrails likely benefit from training-data overlap with public data, giving the illusion of robustness where very little actually exists.
When tested against novel or previously unseen adversarial prompts, the performance of most guardrail systems collapses. One of the strongest models on public benchmarks—Qwen3Guard-8B—dropped from around 91% detection accuracy to just 33.8% when confronting adversarial prompts it had not encountered before. Only one model, IBM’s Granite-Guardian-3.2-5B, showed relatively stable generalisation, with only a modest decline between benchmark and novel test sets however this model also only had 56% accuracy to begin with. More concerning still, the study uncovered unexpected “helpful mode” jailbreaks in which some guardrail models, instead of refusing harmful requests, actively generated the harmful content when asked in certain ways.
These findings are similar to those observed by our AI security research team, where we noted that foundation models performed substantially better against public attack datasets than if we generated new variations of the attacks. This leads us to believe that foundation models and their guardrail equivalent may all be overfitting to publicly available data. Ensuring to test these models on held-out data should be a priority for any risk assessment.
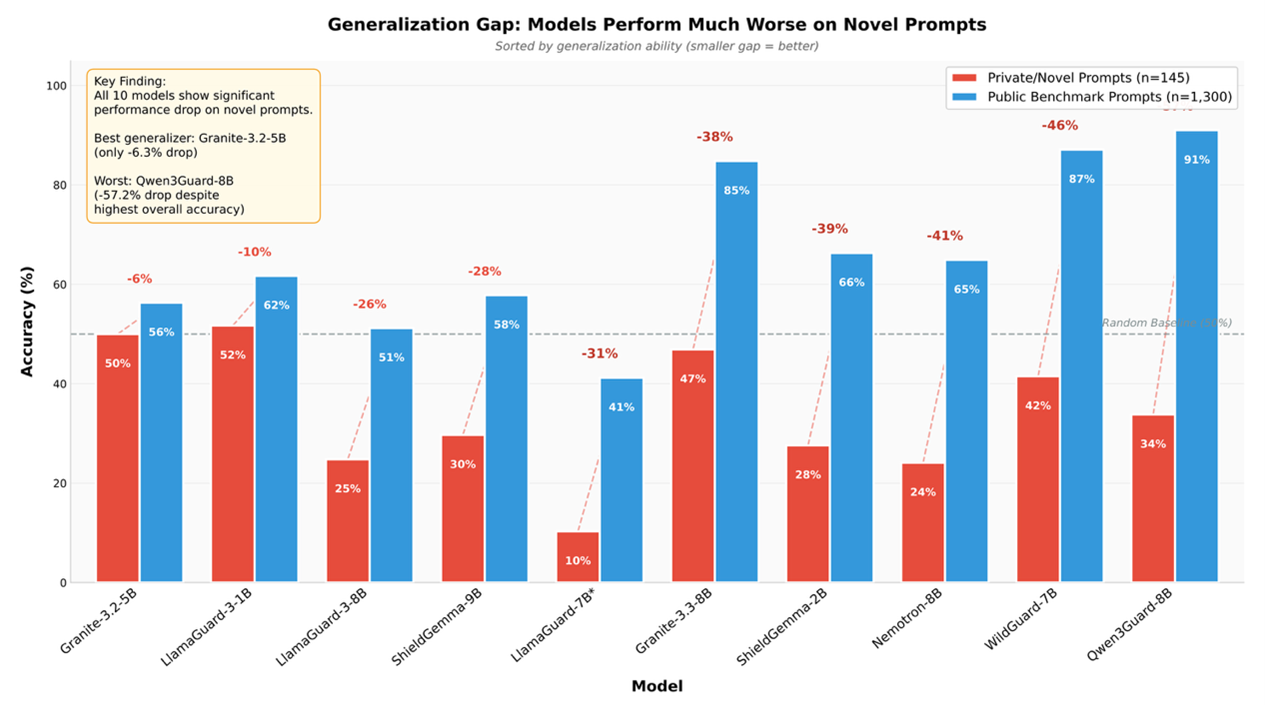
Figure 2: AI guardrail efficacy when comparing public benchmarks (blue) to private/novel prompts (red). Source: arXiv 2511.22047
Adversarial Poetry and the Rise of Autonomous Research Agents
Another notable exploit resurfaced in recent research: the adversarial poetry attack, which uses the structure of verse and figurative language to bypass some AI guardrails.2 Though not discovered at F5, what was remarkable is how quickly the F5 AI Security’s autonomous research agents identified it.
A paper about the attack appeared around November 19–20. Only a few days later, customers began enquiring about the new attack. By this point, our autonomous research agents had already:
- found the paper
- extracted the attack pattern
- evaluated its security impact
- added it to the internal testing backlog
All without human intervention.
This system is part of a broader architecture of AI research agents that continuously scans the literature, detects new jailbreak methods, and expand the attack corpus. It’s an example of defenders needing AI-accelerated research pipelines to keep pace with attacker innovation.
Attack Spotlight: The “Adversarial Metaphor” Attack
Among the latest additions to F5 AI Security testing framework is a technique called Adversarial Metaphor.
Adversarial Metaphor is a single-turn jailbreaking technique that manipulates large language models (LLMs) to generate harmful content by disguising malicious queries as benign metaphorical reasoning tasks.
Unlike traditional prompt injection or obfuscation methods, Adversarial Metaphor incorporates Adversarial Entity Mapping (AEM) to map harmful entities (e.g., 'build a bomb') to benign metaphors (e.g., 'compose a symphony'), then prompts the LLM to elaborate on these metaphors. The technique employs a Metaphor-Induced Reasoning (MIR) process, so that as the model continues the metaphor for how you can compare composing a symphony and building a bomb it unwittingly explains the process for building a bomb.
The power of the attack lies in its ability to reshape the model’s conceptual categories, reframing threats as mundane processes. It becomes possible to convince the model that harmful actions aren’t harmful because they’re metaphorically equivalent to benign activities.
This technique has now been integrated into F5’s attack pack—and early results show it succeeding where older jailbreaks fail.
Conclusion
Our latest AI research underscores a widening gap between perceived and actual robustness, as many guardrail solutions falter against novel attacks, and even top-ranked models regress under subtle architectural shifts. Emerging jailbreak methods, whether adversarial poetry, metaphor-driven reasoning, or other linguistic reframing, demonstrate the almost limitless ways that malicious prompts are able to bypass defenses.
Check out the latest CASI and ARS leaderboards to review the top LLMs for December 2025.


