Introduction
February’s AI Insights highlights a recurring theme across the latest CASI and ARS leaderboard results: capability gains are accelerating, but security resilience is not keeping pace. Z.ai’s GLM-4.7 exemplifies this tension: ranking second overall in capability behind Claude Opus, yet recording a comparatively low CASI score of 43.8.
Beyond the rankings, recent vulnerabilities in agentic platforms reinforce a broader concern: when high-performing models are embedded into autonomous systems, security weaknesses can be amplified at machine speed.
AI Insights February 2026
Let’s first quickly cover some of the reasons and context behind the changes in this month’s leaderboard scores, before exploring some of the biggest AI security news from the previous month.
AI Leaderboard Changes
This month’s leaderboard update brings several notable changes to the top 10. Z.ai’s GLM-4.7 stands out in particular, ranking second overall in capability (behind Claude Opus) yet posting a comparatively low CASI score of 43.8. This sharp contrast highlights an increasingly visible trend in our data: strong benchmark performance does not necessarily equate to strong security resilience. Elsewhere, Gemini Flash 3 makes its debut with a CASI score of 52, while MinMax M2, which previously ranked just outside the top 10 when tested in December, has now moved into the top tier following retesting (see Figure 1). Taken together, these movements reinforce the importance of assessing AI models across both capability and security dimensions, rather than relying on performance metrics alone.
Visit the F5 Labs AI leaderboards to explore the latest CASI and ARS results for February.
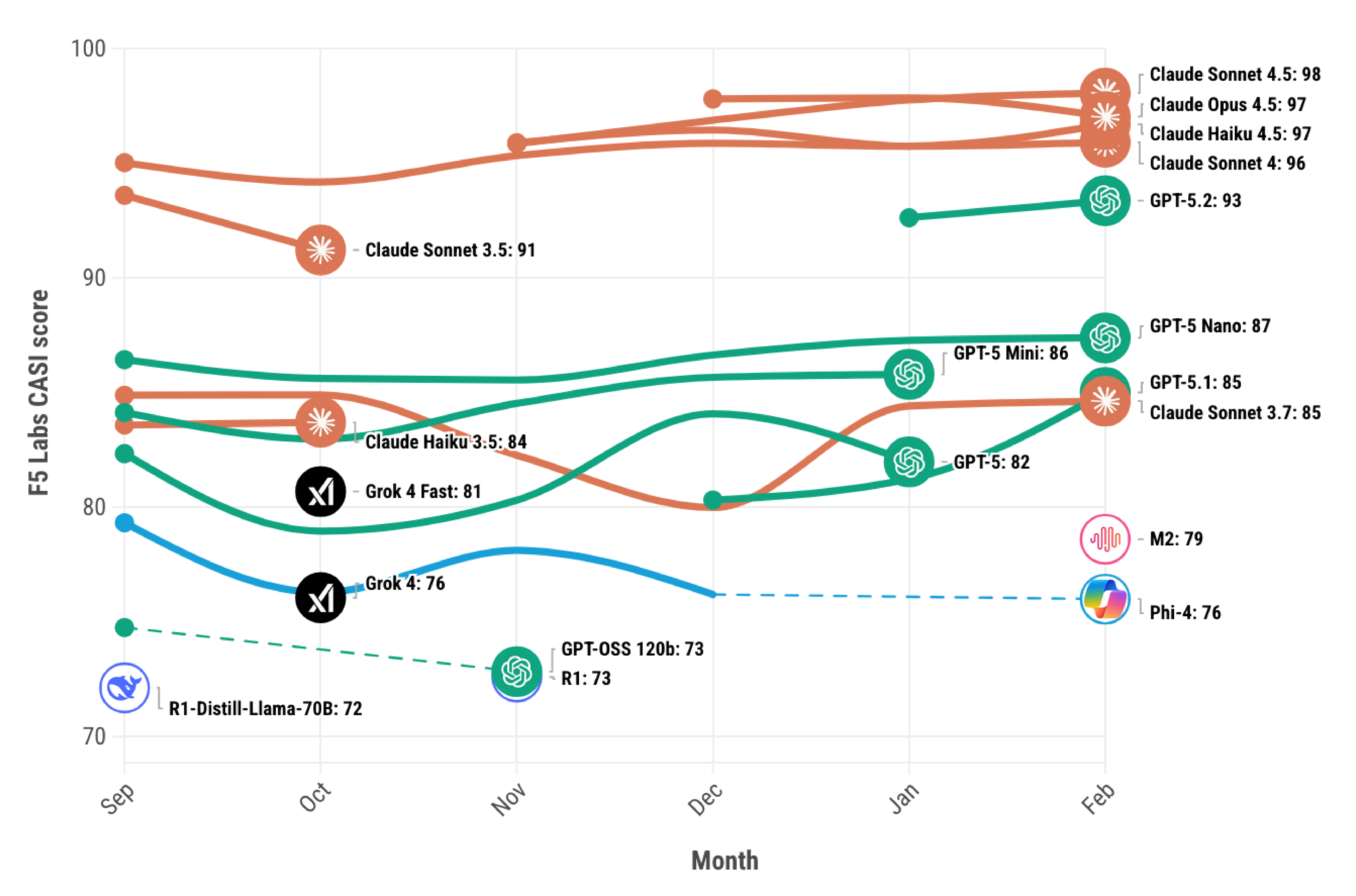
Figure 1: F5 Labs CASI Leaderboard for the past 6 months (top 10 only).
AI Security News
February saw a number of new attacks against LLMs, and the continued trend of how classical cybersecurity CVEs are creating vulnerable [AI] systems at a scale we’ve previously never seen.
BodySnatcher: When Authentication Fails, Agents Amplify the Damage
On January 13, 2026, AppOmni disclosed CVE-2025-12420, a critical vulnerability in ServiceNow's AI Agent platform that earned a CVSS 4.0 score of 9.3 (critical).1 Dubbed "BodySnatcher," the flaw demonstrated a devastating truth: traditional security vulnerabilities become exponentially more dangerous when combined with autonomous AI agents.
The vulnerability chain was elegantly simple but catastrophically effective. ServiceNow shipped AI Agent channel providers with a hardcoded static client secret "servicenowexternalagent" that was identical across every instance worldwide. Combined with an auto-linking mechanism that required only an email address without enforcing MFA, an unauthenticated attacker could impersonate any ServiceNow user, including administrators.
But here's what made BodySnatcher truly alarming: the agent amplification effect. In traditional applications, an authentication bypass might grant access to view a dashboard or read some records. In an agentic system, the compromised agent becomes a high-speed execution engine. With only a target's email address, an attacker could:
- Authenticate using the shared platform-wide secret
- Impersonate an administrator through email-based auto-linking
- Execute AI agents with administrative privileges
- Use natural language commands to create backdoor accounts, exfiltrate data, and override security controls
ServiceNow patched the vulnerability in October 2025 by rotating provider credentials and removing the problematic AI agent from default installations.2 But the incident revealed a broader problem: these configuration choices could exist in custom code or third-party solutions across thousands of enterprises.
The Shadow AI Infrastructure: 175,000 Exposed Ollama Servers
While enterprise security teams focused on securing managed AI deployments, a massive shadow AI infrastructure was quietly emerging. On January 29, 2026, SentinelOne and Censys published findings that shocked the security community: 175,000 publicly-exposed Ollama AI servers across 130 countries, operating completely outside traditional security perimeters.3
Ollama is an open-source framework enabling users to run large language models locally. By default, it binds to localhost (127.0.0.1:11434), which is secure. But a trivial configuration change, setting the bind address to 0.0.0.0 exposes it to the public internet. Tens of thousands of instances made exactly that change without implementing authentication, access control, or monitoring.
The scope of exposure is staggering:
- 175,000 unique Ollama hosts identified over a 293-day scanning period
- 7.23 million observations across 130 countries
- 48% advertising tool-calling capabilities enabling code execution and API access
- China hosts 30% of exposed instances, followed by US, Germany, France, and South Korea
The exposed Ollama ecosystem creates multiple threat vectors: resource hijacking for spam campaigns and disinformation, prompt injection against RAG instances to extract sensitive information, model theft via simple HTTP requests, and supply chain attacks affecting thousands of servers using the same vulnerable model formats.
ZombieAgent: Persistent Memory Poisoning Enables Autonomous Spread
On January 8, 2026, Radware disclosed ZombieAgent, a zero-click indirect prompt injection vulnerability targeting OpenAI's Deep Research agent.4 Unlike previous attacks that required repeated engagement, ZombieAgent establishes persistence by poisoning the agent's long-term memory - turning a single malicious interaction into an ongoing surveillance operation.
The attack works through four escalating scenarios:
Scenario 1: Immediate Exfiltration – An attacker sends an email containing hidden instructions. When the user asks ChatGPT to perform a Gmail action, the agent reads the malicious email, executes the embedded commands, and exfiltrates inbox data before the user ever sees the content.
Scenario 2: File-Based Compromise – A user shares a document containing hidden instructions. ChatGPT reads the file, executes the commands, and exfiltrates data both via OpenAI's servers and through Markdown image rendering.
Scenario 3: Autonomous Propagation - Similar to Scenario 1, but instead of inbox data the hidden instructions target and exfiltrate recent email addresses in the victim's inbox. After receiving the addresses, the attacker sends malicious payloads to them, spreading the attack across the organization.
Scenario 4: Persistent Backdoor - The attacker sends a malicious file containing instructions to modify the agent's long-term memory with attacker-created rules. When the user shares the file, ChatGPT sets the memory-modification rules. Based on these rules, the agent executes hidden instructions every time the user sends a message and saves sensitive information to memory whenever shared.
What makes ZombieAgent particularly dangerous is that all malicious actions occur within OpenAI's cloud infrastructure, not on the user's device or corporate network. As a result, no endpoint logs record the activity. Traditional security monitoring tools remain completely blind to the compromise.
A single malicious email becomes the entry point to a growing, automated, worm-like campaign inside and beyond the organization. The agent doesn't just leak data once, it becomes a persistent spy tool that continuously collects and exfiltrates information over time.
Organizations increasingly depend on AI agents to make decisions and interact with sensitive systems, yet they often have little insight into how those agents process untrusted inputs, creating a visibility gap that attackers are beginning to exploit.
OpenAI patched ZombieAgent in mid-December 2025 after Radware's responsible disclosure.
AI Attack Spotlight: Invasive Context Engineering
This month’s AI Attack Spotlight covers new academic research as recently published on Arxiv.5
In its standard form, Invasive Context Engineering is a vulnerability where an attacker exploits the "recency bias" of an LLM. By engaging in a long, multi-stage conversation, the attacker slowly fills the model's context window with subtle contradictions and new rules. Eventually, the original safety guardrails (the System Prompt) are pushed so far back into the model's "memory" that they lose their inhibitory power. It’s another example of how attacking an LLM is akin to socially engineering a human. This attack is a psychological siege that wears the AI down turn by turn.
While the academic research focuses on this slow, multi-stage erosion, F5’s automated threat intel AI agent has found it was possible to induce the same vulnerability within a single prompt. Instead of having a long back-and-forth conversation, which is what would be required to break the model, we found it was possible to provide the model with a pre-written transcript of that conversation which fooled the LLM into thinking it had already had the back-and-forth conversation over time. For guardrails that attempt to evaluate malicious interaction by the number of back-and-forth interactions, this single-prompt version of the attack might allow this attack to evade some defences.
How it works:
- Context Collapsing: An attacker compresses the "many stages" of a typical Invasive Context Engineering attack into a single block of text. This text is formatted to look like a legitimate chat history where the AI has already agreed to the attacker's terms.
- The "Done Deal" Fallacy: By presenting a finished dialogue, the attacker bypasses the model's "refusal logic" that usually triggers at the start of a suspicious request. The model looks at the provided history, sees that "it" (the simulated version of itself) has already complied, and continues the pattern.
- Attention Flooding: A single, large prompt filled with simulated compliance creates so much "attentional noise" that the model can no longer "see" the original system instructions buried at the root of its architecture.
Since many attacks against LLMs and agentic AI so closely resemble social engineering attacks, it can be helpful to consider what Invasive Context Engineering may look like in the human world. Consider a situation where a new employee is slowly taught “how things really work” through casual conversations. Rather than being told to ignore policy, they are given background context, implied exceptions, and reframed priorities that subtly alter how rules are interpreted. When a sensitive request eventually arrives, the employee complies—not because they were instructed to break policy, but because the action feels reasonable within the context they’ve been conditioned to accept.
This Invasive Context Engineering attack is part of F5’s AI Attack Pack and now contributes to CASI and ARS scores.


