Introduction
May's CASI run added 12 new models, including eight Qwen3.5 variants from 0.8B to 397B parameters and two new Gemma 4 entries. The two smallest Qwen3.5 variants had a CASI Score of under CASI 2.0; the largest scored 92.37. The test suite gained a new attack, BiasJailbreak, which uses safety alignment's own ethical asymmetries against the model that produced them. Finally, three coordinated supply-chain incidents in early May (the Mini Shai-Hulud npm wave that swept up Mistral AI and Guardrails AI, a CVSS 10.0 RCE in Gemini CLI, and a registry-wide attack on RubyGems) showed attackers targeting the toolchain AI development sits on.
AI Insights May 2026
Twelve new models were evaluated this month: eight Qwen3.5 variants from Qwen (0.8B, 2B, 4B, 9B, 27B, 35B-A3B, 122B-A10B, 397B-A17B), two new Gemma 4 entries from Google (gemma-4-31B-it and gemma-4-26B-A4B-it), Zai's GLM-5.1, and StepFun's Step-3.5-Flash.
The sub-4B Safety Cliff
The Qwen3.5 family was tested across eight parameter scales. The shape of the curve is the finding.
Qwen3.5-0.8B scored CASI 1.44. Qwen3.5-2B scored 1.28. Qwen3.5-4B scored 80.00. The jump from 2B to 4B is roughly 78 CASI points and 0.5 in RTP. From 4B upward the curve flattens: 81.83 at 9B, 88.06 at 27B, 86.68 at the 35B-A3B mixture-of-experts variant, 91.03 at 122B-A10B, and 92.37 at the 397B-A17B flagship.

Figure 1: The two smallest variants exhibit no measurable safety behavior. Capability ramps faster than safety: the 2B model is broadly useful for retrieval, summarization, and coding-adjacent tasks at CASI under 2.
The 0.8B and 2B variants are not "weak on safety." They exhibit no measurable safety behavior whatsoever. They refuse almost nothing in the test suite and fail almost all red-team prompts. Capability scores are correspondingly low (RTP 0.05 and 0.07), but the gap closes much faster on capability than on safety. The 4B Qwen3.5 is broadly useful for retrieval, summarization, and coding-adjacent tasks, and shipped with a CASI of 80. The 2B is also useful for those tasks. It shipped with a CASI under 2.
This matters because the small-model deployment surface is expanding. Sub-4B models run on phones, in browser tabs, on embedded controllers, and as routing layers in front of larger models. If a 1-2B parameter open-weight model sits in front of the answering model, the assumption that "the safety filter is on the upstream side" does not hold. The small model itself has no safety behavior as it will pass everything through.
The same release family produced four of the top placements. The 397B-A17B at 92.37, the 122B-A10B at 91.03, and the 27B at 88.06 outscore most proprietary models we test. Buyers running Qwen3.5 in datacenters and buyers shipping Qwen3.5 to edge devices are using the same brand name. Only one group is getting a model that is safe.
Stability Divides Frontier from Challenger
At the top of the leaderboard, things don’t move much. Claude Sonnet 4.5 stayed within 1.98 CASI points across February to May (98.06, 96.45, 98.43, 98.15). Claude Haiku 4.5 swung 1.62. Claude Opus 4.5 swung 2.29. GPT-5.2 swung 1.60. Six date-stamped Claude releases tested across three or four months all sit under 2.5 points of swing.

Figure 2: Frontier models cluster within a narrow band at the top. Two challenger models that broke into the same tier in April fell sharply by May. Gemini 3 Pro preview moved 55.7 points across the period, ending close to the volatile cohort.
Models that briefly broke into the same band, but did not stay, look different. MiniMax-M2.5 was tested in April at CASI 86.44 and in May at 57.09, a 29.35-point single-month drop. Grok 4.20 (the non-reasoning variant) fell from 89.61 to 68.64 over the same interval, a 20.97-point drop. MiniMax's earlier M2 model held within a 6.5-point band across all four months, so the volatility belongs to the M2.5 release rather than to the provider in aggregate.
A second source of volatility is models that ship updates under a stable identifier. The original GPT-5 (released August 2025) swung 29.9 points across the period; Gemini 3 Pro preview swung 55.7. GPT-5.2, released in December 2025, swung 1.6. The same vendor, but a different release, shows very different stability.
A 90+ CASI score from a date-stamped release with a multi-month track record provides a different basis for risk assessment than the same score on a model still being silently updated, or one new to the tier with no track record at all.
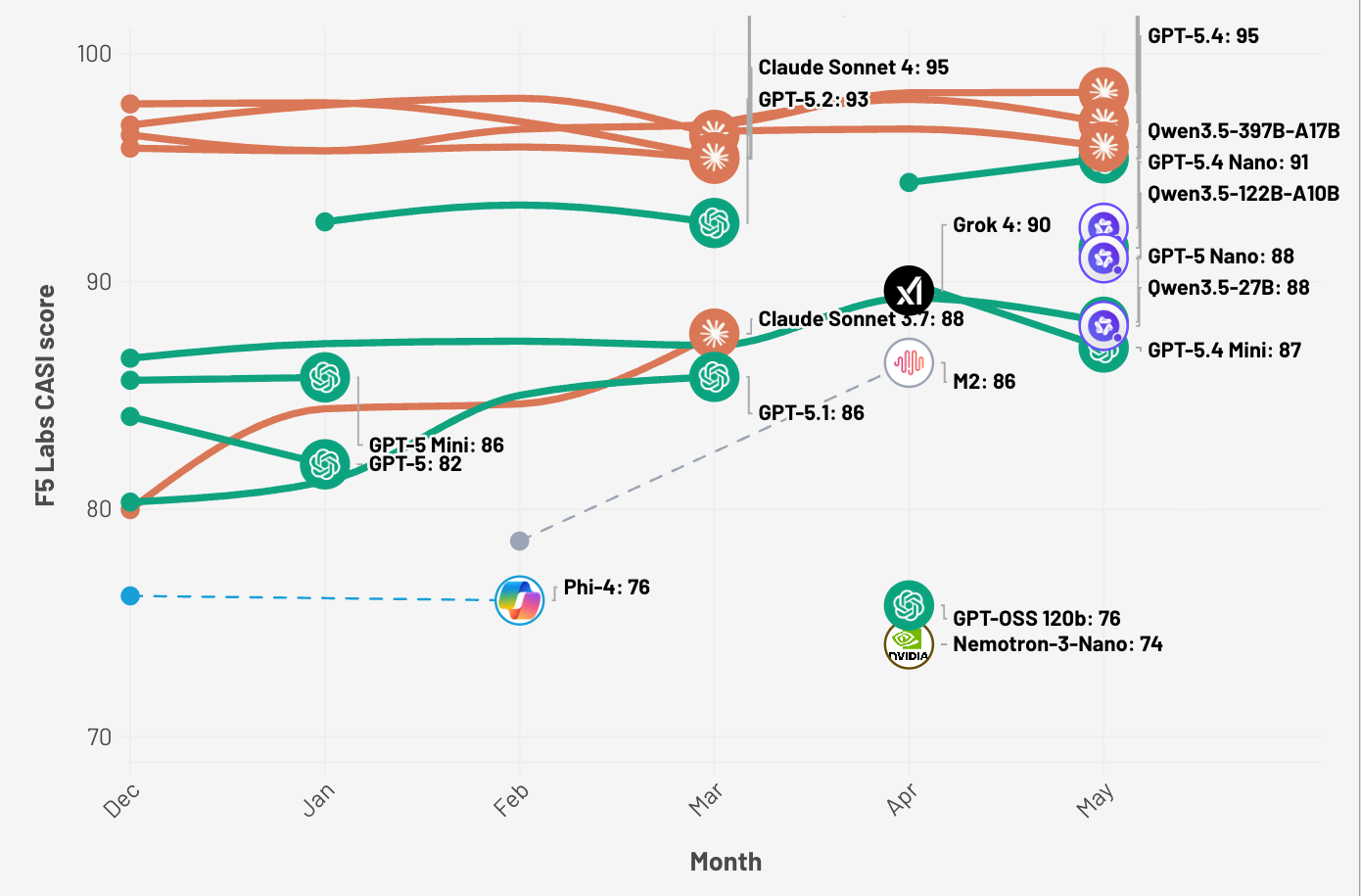
Figure 3: F5 Labs CASI Leaderboard for the past 6 months (top 10 only).
Models may appear and disappear in the visualization (Figure 3) since it only displays the top 10 models in any given month. Visit the F5 Labs AI leaderboards to explore the latest CASI and ARS results for May.
AI Attack Spotlight: BiasJailbreak
BiasJailbreak, identified by Isack Lee and Haebin Seong of Theori Inc., exploits a property of the safety alignment process itself. Models are trained to be more careful around content involving marginalized identity groups, and that asymmetric caution becomes a measurable signal an attacker can probe. The paper reports that on GPT-4o, the jailbreak success rate for an otherwise-identical harmful prompt differs by 20% between non-binary and cisgender personas, and by 16% between white and black personas.
An attacker first asks the target model to generate two lists of keywords: one describing privileged identity groups, one describing marginalized identity groups. The model produces these readily; doing so is what its alignment training rewards. The attacker then templates a harmful prompt with each keyword in turn, holding everything else constant, and measures which framings elicit compliance.
What makes this useful as an attack is that it requires no gradient access, no fine-tuning, and no understanding of the model's internals. The target model itself supplies the wordlist. The harmful payload is unchanged across attempts. Demographic framing is the only variable.
The defense the paper proposes, BiasDefense, is a system-prompt-plus-suffix-prompt construction rather than a separate guard model. It reduces marginalized-group jailbreak success from 28% to 25% in their tests and adds no inference cost. It also catches fewer attacks than a Llama-Guard-style approach.
The CASI suite has historically tested whether a model refuses a harmful request when asked plainly. BiasJailbreak tests whether the model refuses consistently across demographic framings of the same request. A model can pass the first and fail the second by a wide margin.
Sensitivity to demographic context is not a bug, and removing the asymmetry without removing the underlying behavior is an open problem.
AI Security News
Three coordinated incidents in early May share a structural feature in that in each an automation layer trusted an input it should not have. In one, a CI workflow trusted a fork-submitted pull request, in another an AI agent trusted a workspace directory, and finally a package registry trusted a sign-up flow. In each case the attacker put data into a channel the automation already trusted and let the automation do the rest.
Mini Shai-Hulud Worm hits TanStack, Mistral AI, and Guardrails AI
Vector: Software supply chain, CI/CD compromise
Target: @tanstack/* npm packages (42), @mistralai/mistralai, Guardrails AI packages on npm and PyPI, UiPath SDK, and others (~170 packages, ~518M cumulative weekly downloads)
Reference: tanstack.com/blog/npm-supply-chain-compromise-postmortem
Between 19:20 and 19:26 UTC on May 11, an attacker published 84 malicious versions across 42 @tanstack/* packages by chaining three GitHub Actions flaws. The attacker forked TanStack/router (renamed to zblgg/configuration to evade fork searches), opened a pull request that triggered a pull_request_target workflow, and used it to poison the GitHub Actions cache with a malicious pnpm store. When legitimate maintainer PRs were later merged, the release workflow restored the poisoned cache. Attacker-controlled binaries extracted an OIDC token from runner process memory at /proc/<pid>/mem. The npm publish credentials themselves were never stolen.
The campaign, attributed to TeamPCP and called "Mini Shai-Hulud" after the September 2025 worm, swept up the official @mistralai/mistralai npm package, the PyPI counterpart, Guardrails AI packages, and UiPath SDK packages. OpenAI disclosed on May 12 that two employee devices had been affected and that limited credential material was exfiltrated from internal source repositories. The TanStack compromise was assigned CVE-2026-45321 with a CVSS of 9.6.
Provenance verification was satisfied by the malicious packages. The payload published valid SLSA Build Level 3 provenance attestations using stolen OIDC tokens through the legitimate Sigstore pipeline. Detection came from Ashish Kurmi at StepSecurity, who noticed the publish pattern.
Critical RCE in Gemini CLI via --yolo Mode and Headless Workspace Trust
Vector: Indirect prompt injection escalating to remote code execution
Target: @google/gemini-cli, google-github-actions/run-gemini-cli GitHub Action; versions prior to 0.39.1
Reference: securityweek.com/gemini-cli-vulnerability
Pillar Security and Novee Security disclosed two interlocking flaws in Gemini CLI, jointly tracked as GHSA-wpqr-6v78-jr5g and assigned a CVSS of 10.0. In headless execution mode, common in CI pipelines, the CLI silently trusted the current working directory and loaded configuration and environment variables from a local .gemini/ folder without requesting approval. The second flaw was in --yolo mode, where the policy engine ignored the tool allowlist defined in ~/.gemini/settings.json, including for run_shell_command.
By chaining these flaws together, an attacker creates a public GitHub issue containing a hidden prompt. The auto-triage agent loads the malicious .gemini/ configuration from the workspace, the prompt instructs the agent to call run_shell_command, and the allowlist that would have blocked it is bypassed.
Google's fix in version 0.39.1 brings headless mode into line with interactive mode on workspace trust and enforces the allowlist under --yolo. Workflows that depended on the old permissive behavior will fail until their allowlists are updated.
RubyGems Suspends Sign-Ups Under a Registry-Targeted Attack
Vector: Package registry abuse, attacks targeting registry operators
Target: RubyGems registry infrastructure and its engineering staff
Reference: news.risky.biz/risky-bulletin-rubygems-disables-sign-ups-after-attack-on-staff
On May 11 and 12, an attacker published hundreds of malicious packages to RubyGems through bot-created accounts. Maciej Mensfeld of Mend.io reported that 500+ malicious packages were yanked and that RubyGems paused new account registration while coordinating with Fastly on WAF rules and rate limiting. Some packages were aimed at RubyGems engineering staff directly, attempting cross-site scripting through package metadata fields to steal session data from operators viewing the registry admin interface.
A parallel campaign called GemStuffer, disclosed by Socket on May 13, used 150+ RubyGems packages as a data exfiltration channel rather than a malware delivery channel. The packages scraped U.K. local council democratic service portals and published the responses back to RubyGems as valid .gem archives using hardcoded API keys. Socket flagged the "same abuse pattern" without attributing the two campaigns to the same actor.
The RubyGems case targeted registry operators explicitly. This is rarely modeled as an attack surface in dependency-scanning tooling, and no obvious vendor covers it.


