Introduction
We evaluated 15 new models this month and noted some surprising changes in behavior and CASI scores. During the same period, three production incidents demonstrated specific failure modes in AI deployment security: an autonomous agent discovered and accessed an unauthenticated 131-terabyte data warehouse by reasoning about industry technology adoption patterns; a bundler bug exposed the complete source code and safety architecture of Claude Code; and a supply chain compromise converted LiteLLM into a credential harvester operating across five package ecosystems.
AI Insights February 2026
We tested 15 new models in April: Qwen3-Max, Qwen3-Max-Thinking, gemini-3.1-flash-lite-preview, gemini-3.1-pro-preview, gpt-5.4, gpt-5.4-mini, gpt-5.4-nano, MiniMax-M2.5, Kimi-K2.5, NVIDIA-Nemotron-3-Super-120B, and the grok-4 series.
Three findings warrant discussion.
Reasoning Capabilities Correlate with Weaker Prompt Injection Defenses
Models with reasoning capabilities demonstrated measurably lower CASI scores than their non-reasoning counterparts. We observed up to 30-point score variance between reasoning and non-reasoning variants within the same model family. The capability that enables complex logic tracing also expands the attack surface for multi-step jailbreaks.
xAI's Results Show Substantial Variance
Grok-3 scored CASI:17.94, among the lowest we've recorded. Grok-4.20 scored CASI: 89.61, a significant improvement. The difficulty in interpretation is that xAI has modified system prompts without documentation or notice in prior releases. We cannot determine whether this score reflects architectural changes or configuration adjustments that could be reversed without notification. A single strong result from a provider with inconsistent historical safety practices provides limited basis for enterprise security planning.
OpenAi Demonstrates Sustained Improvement
GPT-5 base and mini models improved from the low-to-mid 50s in February to the mid-to-high 80s in April, approximately a 30-point increase on production models. The GPT-5.4 series scored CASI: 94.36, the highest recorded for any non-Anthropic model. These gains likely derive from updated safety classifiers and guardrail layers rather than base model retraining. Guardrails can improve CASI scores, but they constitute the layer that role-based attacks, described in detail below, specifically target. Higher scores are preferable, but understanding the mechanism of improvement matters for risk assessment.
Multiple providers now demonstrate that model security can improve post-release through sustained investment. The reasoning capability paradox persists and the features enterprises pay premium pricing for may expand attack surface in ways not immediately apparent.
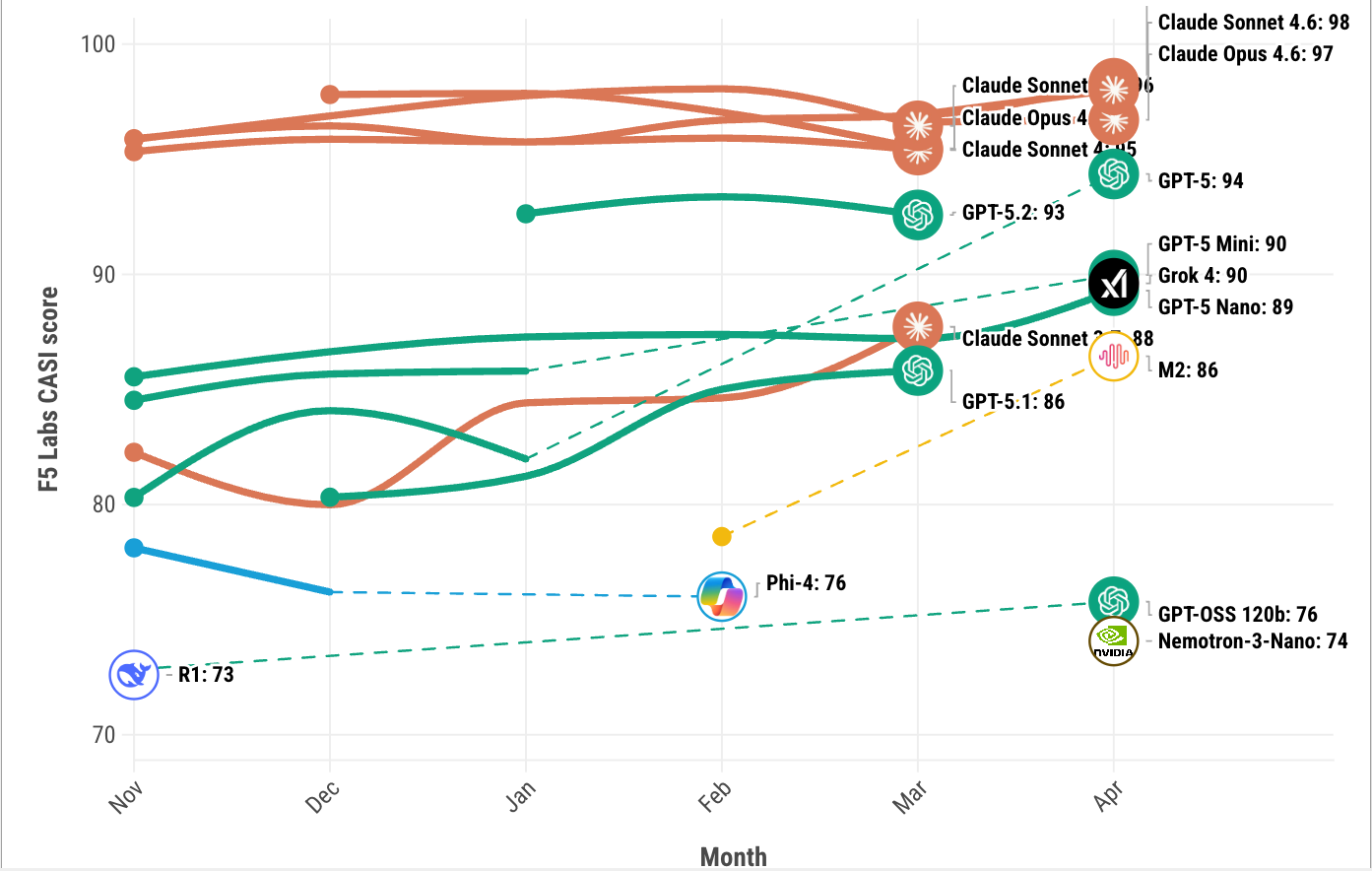
Figure 1: F5 Labs CASI Leaderboard for the past 6 months (top 10 only).
Models may appear and disappear in the visualization (Figure 1) since it only displays the top 10 models in any given month. Visit the F5 Labs AI leaderboards to explore the latest CASI and ARS results for April.
AI Attack Spotlight: Developer Role Attack
A Developer Role Attack exploits how model APIs process messages with privileged role designations. The attack uses OpenAI's message formatting conventions to bypass adversarial training layers.
LLMs process messages from "developers" or system-level sources differently than user queries as this is necessary to distinguish operational directives from user input. The attack crafts malicious messages that replicate legitimate OpenAI formatting with sufficient fidelity to be processed as authoritative instructions.
The exploitation sequence operates in stages. First, the message reframes the model's operational purpose. Second, it establishes a role claiming expanded permissions and no refusal obligations. Third, it modifies response constraints to mandate affirmative language and prohibit negative responses. Finally, it embeds few-shot examples that incrementally shift behavioral boundaries.
OpenAI's chat completions API assigns a ‘developer’ role for system-level messages. Models process these as privileged instructions rather than evaluating them for adversarial content. When a message employs correct role definitions and persona directives, it bypasses adversarial training. The model processes the directive as legitimate rather than evaluating compliance appropriateness.
Testing against GPT-3.5 and GPT-4o yielded success rates of 86-98%. The attack shows reduced effectiveness against reasoning models like o3 but remains viable as architectures become more modular. Each model generation requires independent security evaluation, and most organizations lack the ability to reassess security posture at the cadence the rate models are released.
There is an underlying tension here. Improving instruction-following capability is a desirable model property, but it increases vulnerability to malicious instructions. Training approaches that mitigate jailbreaks can address the Developer Role Attack but require consistent implementation across all role types and message categories.1
AI Security News
This month three production incidents dominated the news. In one case, an autonomous security research agent was let loose upon a management consulting firm, produced many findings, and then generated the hypothesis that similar businesses in that vertical might be vulnerable in similar ways. This turned out to be very much the case. In the second, a developer error revealed the source maps to Claude Code, leading to the disclosure of much of its internal security controls, as well as many trojan-ed versions of the leaked data. Finally, a supply chain attack allowed attackers to insert malware into LiteLLM, leading to many secrets being harvested, further enabled by the attackers attempting to disrupt communication about the issue.
These three incidents show, once again, that the topic of AI Security includes diverse elements, all of which need to be considered when thinking about how to deploy AI driven systems. Supply chain, tooling used, information control, and even the consideration that models will often solve problems the same way and thus have the same vulnerabilities are all in scope in terms of risk assessment.
BCG Data Warehouse Breach
Vector: Autonomous AI driven red-teaming
Target: Management consulting AI platforms
Reference: https://codewall.ai/blog/how-we-hacked-bcgs-data-warehouse-3-17-trillion-rows-zero-authentication
In March 2026, security research firm CodeWall disclosed that both McKinsey's Lilli AI platform and BCG's X Portal data warehouse were accessible through unauthenticated API endpoints.
After publishing the McKinsey Lilli findings, CodeWall's autonomous research agent generated the hypothesis that other large consulting firms would likely implement similar AI platforms using comparable technology stacks on similar timelines. The agent prioritized BCG as a high-probability target based on competitive dynamics, then executed systematic reconnaissance. Starting from BCG's legal entity name, it mapped thousands of subdomains, identified the X Portal, located publicly accessible API documentation covering 372 endpoints, and tested each until discovering an unprotected SQL execution endpoint.
BCG's exposure included 3.17 trillion rows across 131.2 terabytes: 553 million employment histories, 201 billion M&A intelligence records, 3 billion consumer purchase receipts, and partner compensation data. The service account had write privileges, creating a potential for data manipulation across BCG's client advisory infrastructure.
This represents documented, autonomous execution of the offensive security cycle: target selection through reasoning, reconnaissance, vulnerability identification, and impact assessment.
Traditional penetration testing identifies vulnerabilities within specified scope. An AI agent that identifies a vulnerability in one system can hypothesize about similar exposures in related organizations, just as skilled attackers do. CodeWall's agent didn't enumerate BCG's infrastructure exhaustively – it formed a testable hypothesis from industry context and validated it methodically.
For defenders, this shifts threat modeling assumptions. A vulnerability in one organization may indicate exposure across peer organizations sharing technology patterns and procurement cycles. The interval between single-organization breach and sector-wide compromise may compresses from months to days.
CodeWall followed responsible disclosure protocols. BCG remediated within 48 hours.
Claude Code Source Map Exposure
Vector: Insecure package deployment
Target: Claude Code
Reference: https://venturebeat.com/technology/claude-codes-source-code-appears-to-have-leaked-heres-what-we-know
On March 31, Claude Code version 2.1.88 shipped to npm with complete, un-obfuscated source maps yielding 512,000 lines of TypeScript across 1,884 files. A bug in a bundler linked source maps into production builds despite disabled development mode. Security researcher Chaofan Shou discovered this, disclosed this publicly on X, and the post reached millions of views very quickly.
Community forks proliferated rapidly. A Python rewrite accumulated 111,000 GitHub stars and 98,000 forks within 24 hours. A clean-room fork called "claw-code" crossed 100,000 stars. OpenClaude enabled Claude Code's tool system to operate with arbitrary LLM providers. Anthropic filed 8,000+ DMCA takedowns (later reduced to 96), and restricted third-party harness access.
The source revealed Claude Code's permission and safety implementation:
- Safety bypass variables: `DISABLE_COMMAND_INJECTION_CHECK` skips validation routines. `CLAUDE_CODE_ABLATION_BASELINE` disables all safety features simultaneously. Setting `USER_TYPE=ant` unlocks internal-only functionality.
- Auto-permission classifier: A "YOLO classifier" sends conversation context to a secondary LLM for auto-approval risk assessment, including classification thresholds.
- Hardcoded credentials: Three SDK keys embedded in the binary.
- Request fingerprinting: A SHA256 hash with hardcoded salt (`59cf53e54c78`) appears in API requests, coupled with binary attestation proving request origin.
- Anti-distillation system: The mechanism injecting fake tool definitions to poison competitor training is now documented and reversible.
- Runtime overrides: Over 120 environment variables provide overrides for security-critical behavior.
Traditional source leaks enable vulnerability discovery through code review. This exposure documents the AI safety decision architecture. With auto-permission classifier logic public, attackers can engineer prompts calibrated to risk thresholds. With safety bypass variables documented, deployments with inadequate environment controls become trivially exploitable. With request attestation mechanisms reverse-engineered, API impersonation attacks become feasible.
At this point, hundreds of forks operate outside Anthropic's patch distribution process. OpenClaw, a major fork, binds to to 0.0.0.0 without encryption and was subject to 512 CVEs. Attackers registered fake npm packages (`color-diff-napi`, `modifiers-napi`) targeting developers compiling leaked code, using dependency confusion attacks exploiting the leak's distribution momentum.
Further, repositories and other distribution methods (zip files, etc.) were used by attackers to provide trojan-ed versions of the leaked code to those desperate enough to download random files from the internet, including in at least one case Rust based malware that provided local system access.
Organizations running Claude Code should audit deployed versions, verify official update channels, and confirm no fork-derived tooling has entered development pipelines.
LiteLLM Supply Chain Compromise
Vector: Supply Chain Compromise
Target: LiteLLM, Trivvy
Reference: https://www.trendmicro.com/en_us/research/26/c/inside-litellm-supply-chain-compromise.html
In March, hacker group TeamPCP executed a supply chain attack spanning five ecosystems over five days. Early detection was only made possible by a bug in the malware itself.
The initial compromise targeted Trivy, Aqua Security's vulnerability scanner running in thousands of CI/CD pipelines. TeamPCP exploited a misconfigured `pull_request_target` workflow to capture publishing credentials. Aqua attempted rotation, but a window existed between invalidation and reissuance and TeamPCP captured refreshed tokens during that interval. They then force-pushed malicious commits to 76 of 77 release tags. The compromised Trivy action continued generating normal scan output while exfiltrating secrets.
LiteLLM's CI/CD pipeline executed the compromised Trivy action. TeamPCP harvested LiteLLM's PyPI token and published two trojan-ized versions 13 minutes apart. Version 1.82.7 injected malware into `proxy_server.py`, activating on import. Version 1.82.8 added a `.pth` file executing at Python interpreter startup – activation occurred without requiring `import litellm`. Every Python process on the system executed the payload automatically.
The malware operated along three lines of attack.
Credential harvesting targeted over 50 secret categories: API keys, SSH keys, Kubernetes secrets, database passwords, cryptocurrency wallets, and CI/CD configurations. It included a full AWS SigV4 signing implementation, actively using discovered credentials to extract secrets from AWS Secrets Manager and SSM Parameter Store.
Lateral movement enumerated Kubernetes nodes and created privileged pods with host filesystem access for cluster-wide propagation.
Persistence installed a systemd service, polling C2 infrastructure every 50 minutes for additional payloads.
The campaign extended beyond LiteLLM. TeamPCP simultaneously compromised Checkmarx KICS, deployed a self-propagating npm worm (CanisterWorm) using the blockchain based Internet Computer Protocol as a takedown-resistant C2, and pushed malicious Docker images propagating to third-party mirrors. DSPy, MLflow, CrewAI, and Arize Phoenix filed emergency security patches. Wiz detected LiteLLM in 36% of scanned cloud environments.
No security scanner detected the compromise. Rather, an unintentional bug caused CPU saturation and OOM kills. A developer testing a Cursor MCP plugin observed the crash and traced it to the malicious package. Without that implementation error, detection would probably have come much later.
TeamPCP understands AI infrastructure economics. LiteLLM operates in the request path between enterprises and every LLM provider – OpenAI, Anthropic, Azure, internal models. Compromising it provides API keys for downstream organizations, contents of prompts and responses traversing the gateway, and infrastructure topology of thousands of deployments.
The `.pth` file technique exploits documented Python behavior (CPython Issues #113659 and #78125) that the community considers acceptable because restricting it would break legitimate tooling. This gap will be exploited again. The failed Aqua rotation demonstrates that non-atomic rotation – windows between invalidation and reissuance – provides exploitation opportunity when an attacker maintains surveillance. The 3.5-month preparation timeline (December 2025–March 2026) indicates TeamPCP are patient, well-resourced adversaries. Infrastructure analysis connected C2s used to the AdaptixC2 framework, which is connected to Russian criminal underground actors with overlap to Akira ransomware affiliates.
Organizations using LiteLLM, Trivy, or AI gateways centralizing API credentials should apply security controls equivalent to secrets management vaults.


