Information security often takes the form of an arms race, as attackers develop novel ways to use or abuse services on the web to their own benefit, and defenders scramble to adapt to and block these new techniques. Few technologies better exemplify this arms race than the web element known as CAPTCHA.1 This component is designed to identify and block bots that attackers use to automate and scale up attacks such as credential abuse, web scraping, or, in the case of tools like sneaker bots, to quickly buy up limited supplies of commodities like fashionable sneakers.2 CAPTCHAs weed out bots by presenting puzzles within the browser’s response that ostensibly only humans can solve. In the beginning, these puzzles were mostly visual, and usually required users to parse distorted text and type it in. Over time, CAPTCHAs have come to include different types of puzzles, including identifying specific objects within a complex image, transcribing short audio files, or solving logical puzzles, such as turning an image right-side up. Google’s latest version of their reCAPTCHA tool, version 3, transparently analyzes user behavior in the browser instead of requiring specific human input.3
For more than a decade, however, attackers have had the ability to circumvent CAPTCHAs at scale and speed, not through advances in computer vision or artificial intelligence, but by identifying and farming out the puzzles to networks of human workers (known in this industry as solvers) in developing economies, and then returning the correct responses so that bots can continue on their assigned task. These services cost attackers (that is, the customers of the solver service) roughly USD $1-$3 per 1,000 correct solutions, depending on the service and type of puzzle. The solver networks, however, only pay workers roughly USD $0.40 for 1,000 correct solutions. Depending on the solver’s speed, that puts their pay anywhere from $2 to $5 per day.
To be clear, as of 2020, the risk that human CAPTCHA solvers present is now more or less manageable (if not solved) for multiple reasons. For one, it’s an old practice with which security practitioners are widely familiar, and several security vendors have devised ways to detect human CAPTCHA solver networks. Some security vendors have developed bot mitigation or anti-fraud solutions to replace CAPTCHAs. Meanwhile, advances in artificial intelligence-based CAPTCHA solvers threaten to make the human solver networks obsolete.
So why dive into these human solver networks now? Despite the low risk, this practice deserves a through examination because of the simple nature of the hack. Instead of trying to compete with defenders to develop sophisticated artificial intelligence, CAPTCHA solvers simply use low-cost, globally distributed human labor as a front-end for a botnet. This kind of problem-solving illuminates a fundamental aspect of the battle between attackers and defenders in information security. Just as the CAPTCHA element exemplifies the arms race, this method of circumventing security controls reveals that security practitioners often misrecognize the nature of the attacker’s advantage. Unpacking that misrecognition can provide clues to general guidelines for designing future controls that could transcend this arms race and stand the test of time. Before we get to all that, however, let’s dig into the basics of solver networks and how they function.
How CAPTCHA Solver Networks Work
Human CAPTCHA solver networks involve three entities: attackers who want to circumvent CAPTCHAs so that they can scale out attacks using bots; solver networks, such as Anti-Captcha, 2Captcha, and DeathbyCaptcha; and the solver labor force. The details of the solver networks’ architecture vary slightly from network to network. Generally speaking, however, the life cycle of the service for a single CAPTCHA is as follows: when an attacker identifies a CAPTCHA at a target site, they send the puzzle content, usually encoded in base64, to the solver network API. The solver network’s software returns a task identification number to the attacker and farms out the puzzle to one of its workers, who solves it and returns a solution (see Figure 1). Meanwhile, the attacker sends a request with the task number to the network API to check for a posted solution, repeating over short intervals. When the solver network software detects a solution with the same task number, it responds to the attacker’s request with the solution, the attacker places the solution in the text field, and the attack can continue.
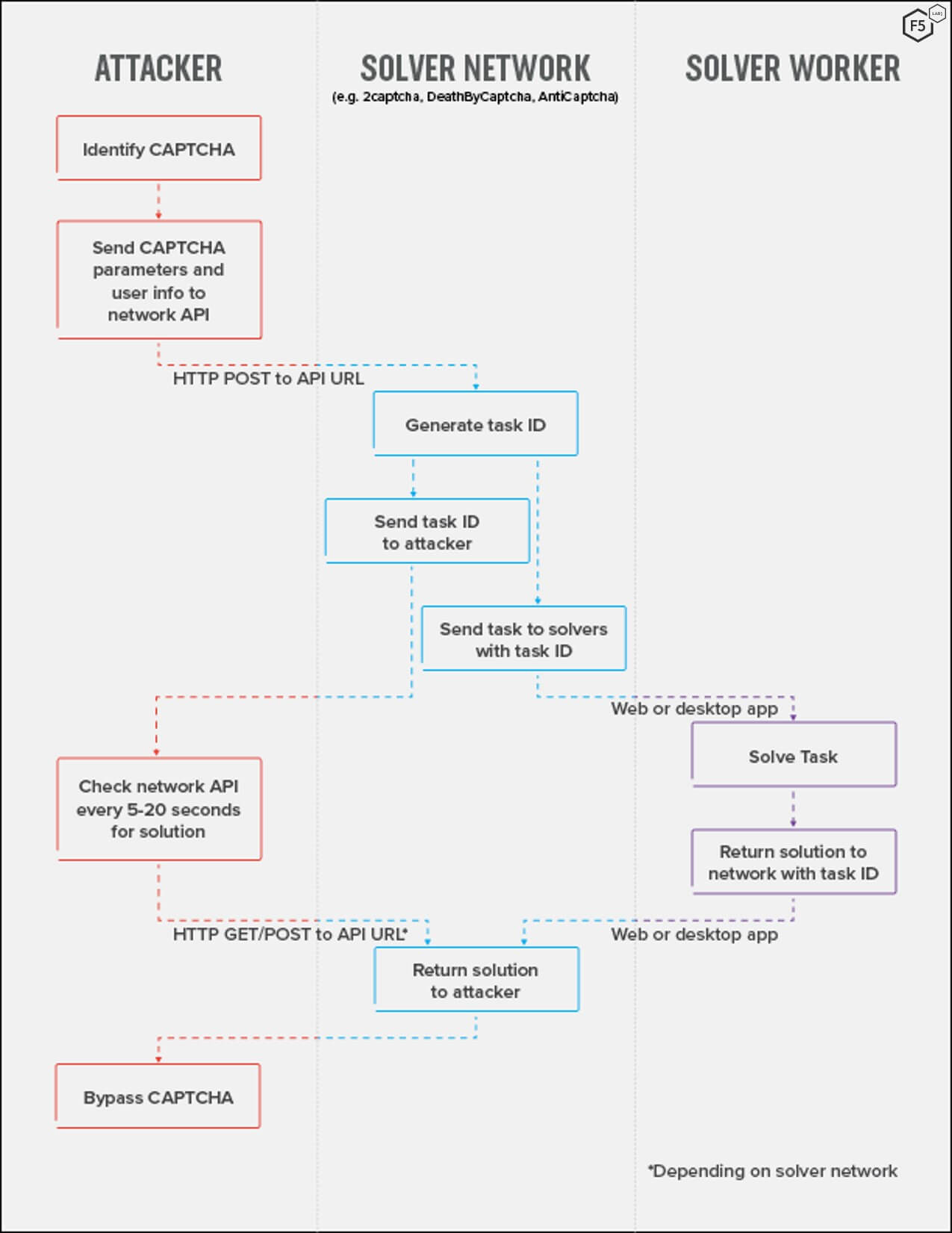
Figure 1: The life cycle for a single CAPTCHA solution event. Note that this diagram only shows a single solution event—in an attack this process would be happening hundreds of times a minute to achieve scalability.
While the process described in Figure 1 is for a single CAPTCHA event, the real point of this service is to enable scalability through automation. In an actual attack, an attacker would use scripts or off-the-shelf attack software to send hundreds or thousands of these requests per minute, which the solver network software would distribute to a large number of workers around the world.
One common method to accomplish this scaling uses a script to coordinate API traffic with the network in conjunction with a webdriver like Selenium to identify CAPTCHAs and place the returned solution back into the form. Figure 2 shows the Selenium/script approach from the attacker’s point of view.
Some of these services also offer a browser extension through which attackers can flag both the puzzle and the input field for the solution. Others leave it up to the customer to integrate the API calls with their own command and control systems. However, browser extensions have the disadvantage of changing the Document Object Model (DOM) of the target site, making them susceptible to detection. Figure 3 shows the attacker’s point of view using a browser extension to coordinate the traffic between the attacker’s browser and the solver network.
These networks also offer a surprisingly high level of service, including documentation, technical support, and language support. Most of the larger solver networks support coverage for a wide range of more advanced CAPTCHAs, including reCAPTCHA v2, text-based logic CAPTCHAs like hCaptcha, and even behavioral systems like reCAPTCHA v3. Some networks also provide expedited service at a higher cost, a guaranteed-accuracy option in which multiple separate workers return solutions in parallel for comparison, and even accessibility options for visually impaired customers.
From the workers’ standpoint, the process is simple. The networks present the CAPTCHAs to workers either through web applications or desktop applications. Workers simply log in and wait for puzzles to appear. One of the networks, Anti-Captcha, also publishes information about their workforce, even going so far as to publish worker profiles to give a sense of the humans behind this globally distributed process. The workforce that we know about through these profiles is distributed across 26 countries, though as of May 2020 nearly 75 percent of the workforce is located in Venezuela, Indonesia, or Vietnam.4 Figure 4 shows the solver worker’s point of view using one of the more popular desktop solver clients.
Reassessing the Information Security Arms Race
The thing that makes the human CAPTCHA solvers so instructive about the security arms race doesn’t lie in the technical details. Rather, it is the most fundamental thing about them. Instead of exploiting coding errors or misconfigurations that lead to vulnerabilities, human CAPTCHA solvers exploit assumptions about the value of human labor time. That is, CAPTCHAs are designed around system owners’ assumptions that it is not possible to use human labor to scale up the kinds of attacks that the CAPTCHA solver customers undertake. In one way, that assumption is correct. The skilled labor that actual attackers represent is too expensive to multiply by hundreds or thousands within a short time frame. However, the comparatively unskilled labor required to solve a CAPTCHA is not too expensive, given the necessary infrastructure that allows this fragmented, distributed labor supply to meet its demand.
The result is that, in the 21st century, attackers pay humans poverty-line wages to act as a front end for bots, which in turn act like humans, for the purpose of using an information system in a way for which it was not designed. This illuminates the core issue: for the attackers, it was never really about the bots—it was about scalability. The bots were a means to an end; when defenders made life hard for bots using CAPTCHAs, attackers found humans to front for them. Faced with a battle that, on the surface, seemed to be about artificial intelligence or computer vision, attackers instead found a way to reframe it in terms of the cost of human labor.
For the attackers, it was never really about the bots—it was about scalability.
This is, in a way, the archetypal hack. By maintaining a focus on their actual goal—scalability—and by developing a new, low-cost solution, attackers have deftly sidestepped a battle in which defenders had an advantage. In contrast, the ever-increasing complexity and fidelity of CAPTCHAs shows that stopping bots, which were only ever a means for the attacker, has become an end in itself for defenders.
Because the reframing that these solver services represent happens along nontechnical lines that are unusual in the information security world, it is easy to recognize, but the underlying thought process is also present in other kinds of attacks. The formjacking attacks that have become so prevalent and profitable over the last few years represent a similar sort of insight. Many of the prescribed controls around payment card processing, such as rigorous encryption standards, need-based access, and firewalls that are expensive to procure and maintain, are built around the goal of protecting those data once they are formally the defender’s responsibility. Viewed through this lens, formjacking attacks represent the attacker declining to attempt to infiltrate those relative fortresses, instead donning a disguise to convince users to hand over their information willingly, out on the metaphorical street.
In other words, these practices illustrate that the field of information security has tended to misrepresent the “attacker’s advantage.” In our field, we often fall back on the truism that defenders need to succeed all of the time, whereas attackers only need to succeed once. While I think this is becoming increasingly less true with time, that is not really the point here. The CAPTCHA solver networks show that the attacker’s advantage is the opportunity to constantly redefine the scope of the battlefield, to operate at the level of ends, and to force the defender to operate at the level of means.
What This Means in Practical Terms
Security practitioners are often preoccupied with tactics, techniques, and procedures (TTPs) because they are the details that allow people in a security operations center (SOC) or in a forensic analysis to diagnose or mitigate an attack. The CAPTCHA solvers, however, demonstrate that when it comes to designing proactive controls or security programs (instead of mitigating ongoing attacks), focusing on TTPs is only going to get us so far. This is because TTPs often represent a set of disposable means to the attacker. On some level, we can boil the entire history of the security arms race down to the attacker community declining to fight on the terms that the security community has laid out and seeking another way around, forcing security practitioners to adapt in turn.
By contrast, controls that can invalidate entire strategies like scalability, persistence, or concealment would offer greater utility across time, space, and diverse systems. In other words, TTPs are absolutely critical in many applications of information security, but they are neither the final word nor the only game in town.
In practical terms, controls that operate at this strategic level, at the level of ends and not means, will necessarily raise questions of application architecture and even of business models. The idea of incorporating information security more deeply in the business is neither new nor controversial, but the implication here is that it actually represents an opportunity to reduce security costs by making efforts across the board more proactive. I do not mean to imply that the time and expertise dedicated to mitigating bots has been ill-spent, but I do think that focusing on why attackers are doing something can be as productive as focusing on how they are doing it.


