Identifying Trends in Recent Cyberattacks
Web attacks vary quite a lot—by target, technique, objective, and attacker—which makes it difficult for a system owner to assess the instantaneous risk to their particular combination of systems until they’re attacked. To help defenders anticipate the risks they face, we analyzed several months’ worth of global honeypot traffic from our research partner Effluxio as part of the 2020 Application Protection Report. While honeypots have some limitations, they also provide a view of cyberattacks that is difficult to get any other way.
What Are Honeypots Good For?
Honeypots are unique among hosts in that they don’t actually serve a page or have a domain name associated with them, which means that no human is likely to stumble upon one. In exchange for losing practical utility as a server, honeypots solve one of the most difficult problems in security: differentiating malicious from normal traffic. Because all of the traffic that a honeypot logs is either automated, like search engine crawlers, or malicious (or both), they are useful in seeing which combinations of tactics and targets are front of mind for attackers.
What Are Honeypots Not Good For?
The scope of the Internet makes it practically impossible to capture a significant chunk of its malicious traffic, no matter how many sensors you have or how you distribute them. Furthermore, because most honeypots don’t provide any actual services, they are unlikely to capture traffic from targeted attack campaigns that are seeking a specific asset as opposed to a category of asset. While honeypots are good for getting a sense of what less sophisticated attack traffic looks like, they will probably not catch traffic from state-sponsored actors or high-end cybercriminals. In short, honeypots can’t rule out attacks or threat actors, but they can rule them in.
Recent Cyberattacks: Breaking Down the Data
The set of Effluxio data that we analyzed contains server requests from mid-July through mid-October of 2020. Effluxio prefers not to disclose the locations or number of sensors, but we can still make a number of observations and a few conclusions based on this traffic. Here are the basic characteristics of the data set:
- About 1,090,000 connections logged
- 89,000 unique IP addresses
- 22,000 unique target path/query combinations1
- 42 unique countries represented in the targets
- 183 unique countries represented in the sources2
Nearly every aspect of the data set is characterized by a long tail. This means that a small subset of IP addresses, target paths, and geographical targets stands out as particularly common. For instance, 42% of the traffic in the time period came from the top 1% of IP addresses, and 52% of the traffic was targeting the top 1% of target paths. However, only 0.2% of the traffic featured both the top 1% of IP addresses and the top 1% of target paths—meaning that a huge proportion of the traffic was composed of either IP addresses or targets that the sensors logged only a few times. The tails of the traffic distributions were so long that for both the target paths and the source IP addresses, the median number of instances was one. The single most frequently seen IP address made up 2% of total traffic, and the most frequently seen target path, the web root /, made up just under 20% of total traffic (see Figure 1).
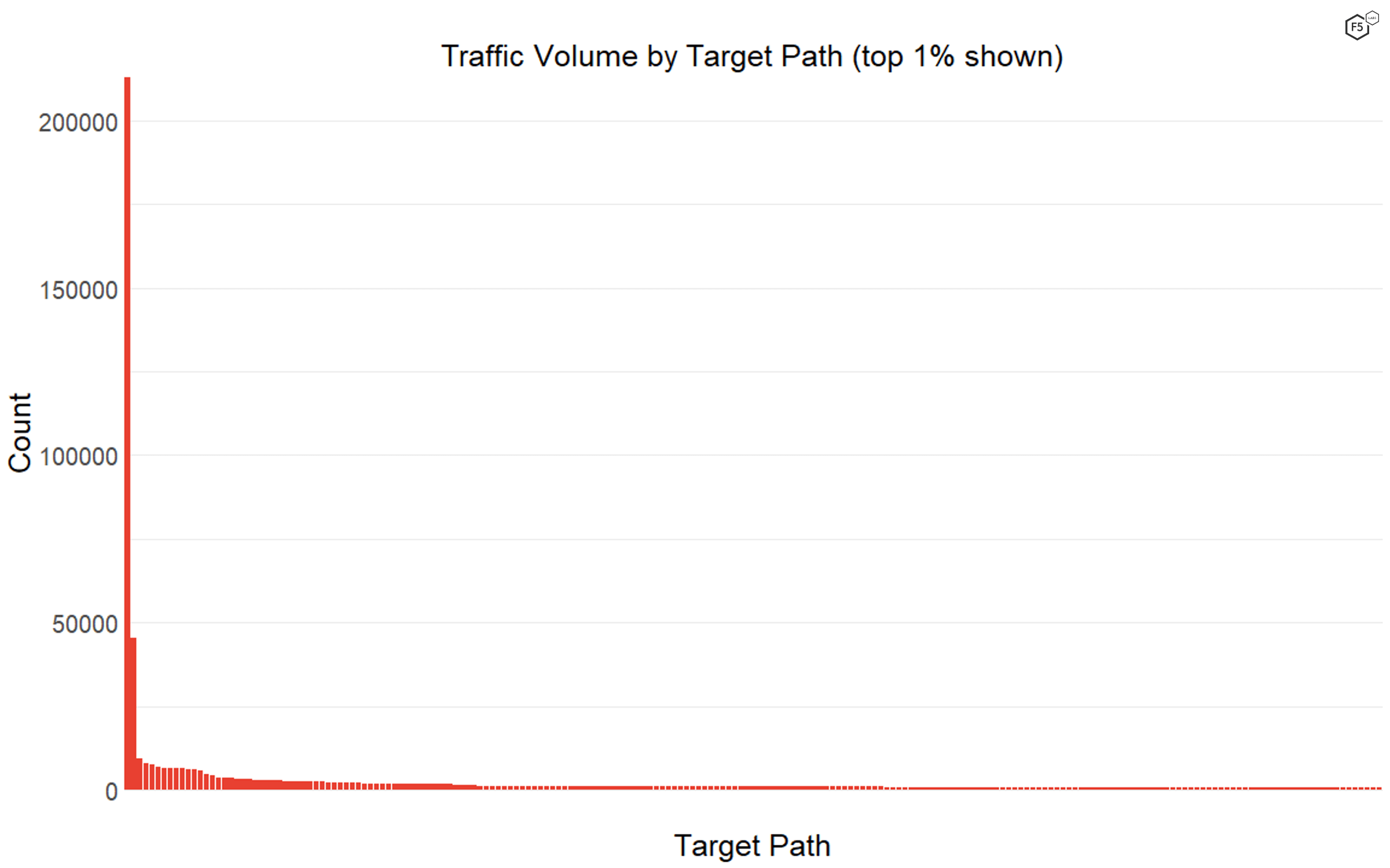
Figure 1. The distribution of traffic by target paths. The web root was by far the most common path, followed by the indexing instruction file robots.txt, and then a long tail of rarely seen targets.
We do know that the most widely seen IP address, 195.54.160.21, which had more than three times as many logged connections as the next one, is a known malicious IP address associated with Russian scanning networks, as shown in Figure 2. None of the other top 10 IP addresses stood out as confirmed malicious assets.
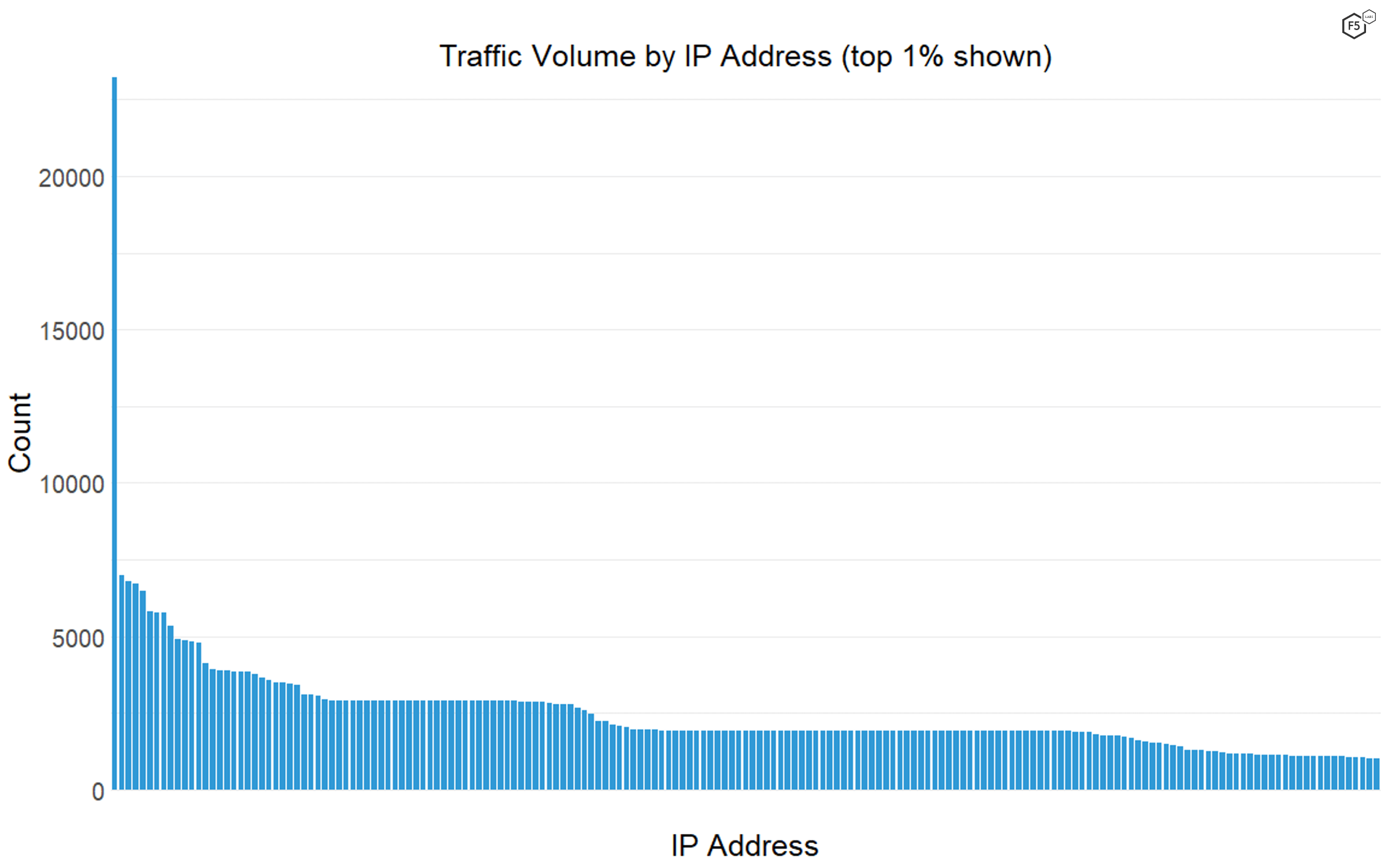
Figure 2. The distribution of traffic volume by IP address. One single IP address, associated with malicious activity from Russia, showed up in the data more than three times as often as the next most common IP address.
In this time period, we also found that the most frequent geographical location for targets was Israel, followed by the United States, Russia, and India (see Figure 3). The target paths in the data show no particular association with Israeli systems or organizations, so we can only speculate as to the reason behind this geographical (or geopolitical) targeting.
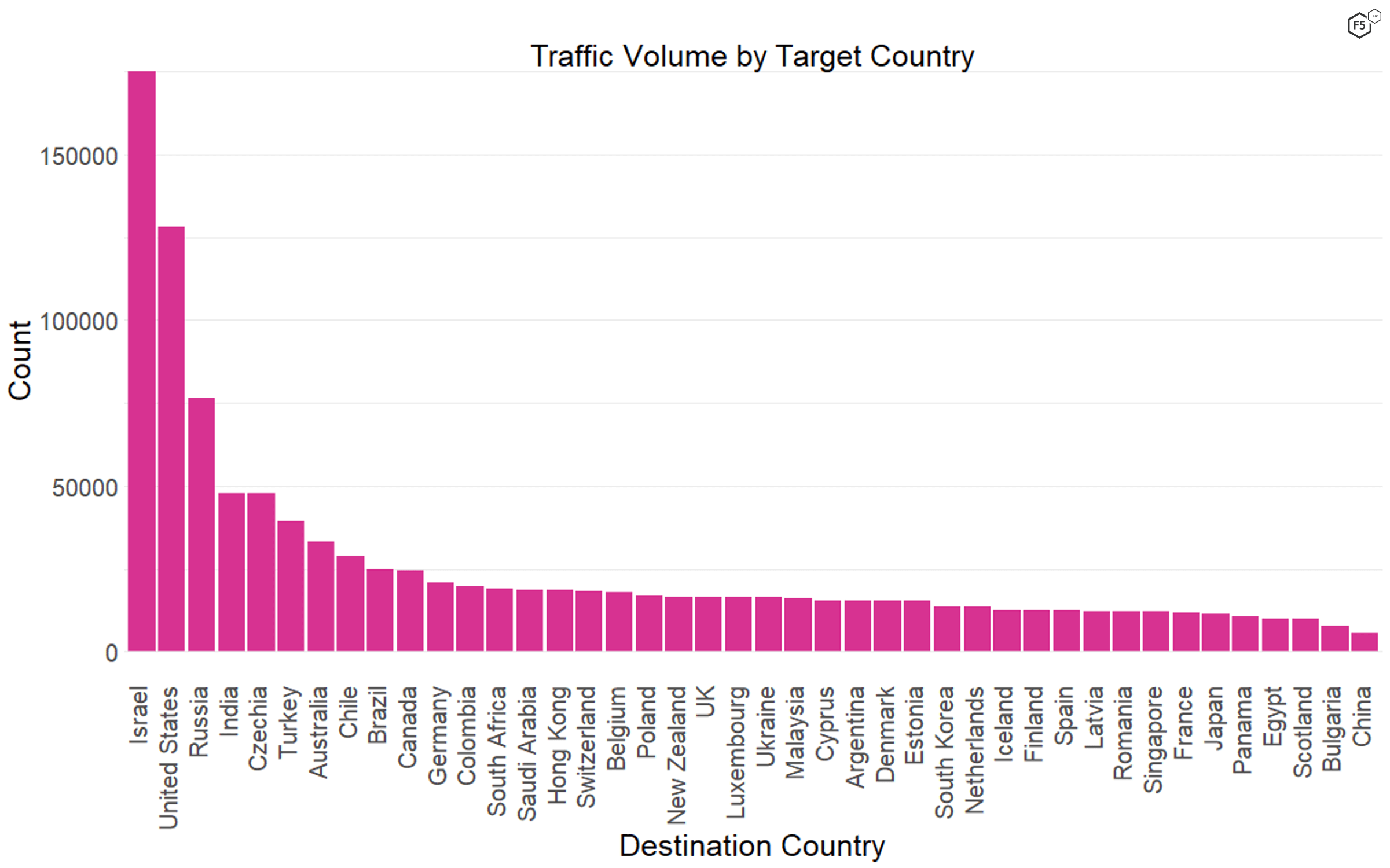
Figure 3. The distribution of traffic by geographical location of destination. Israel was overrepresented in targets in this data set, though we do not know why.
Target Analysis
The two most prominent targets by far were server requests connecting to the web root itself (the / path) or robots.txt files. We don’t know if the connection attempts against robots.txt were malicious scanners looking for directories that administrators don’t want to be scanned or neutral scans from search engines.
The rest of the top 20 target paths featured a combination of known vulnerabilities, such as several PHP remote code execution vulnerabilities and an Apache SOLR vulnerability, or scans for authentication portals for common targets such as WordPress sites (see Figure 4). Interestingly, many of the known vulnerabilities were against IoT devices, such as routers and security cameras. The last of the top 20 targets was the server location of browser icons, or favicons, reflecting the growing use of favicons to inject malicious code. This tactic is most common against WordPress sites,3 though in 2020 Magecart threat actors used favicons to inject skimmer scripts as part of the growing trend of formjacking attacks.4
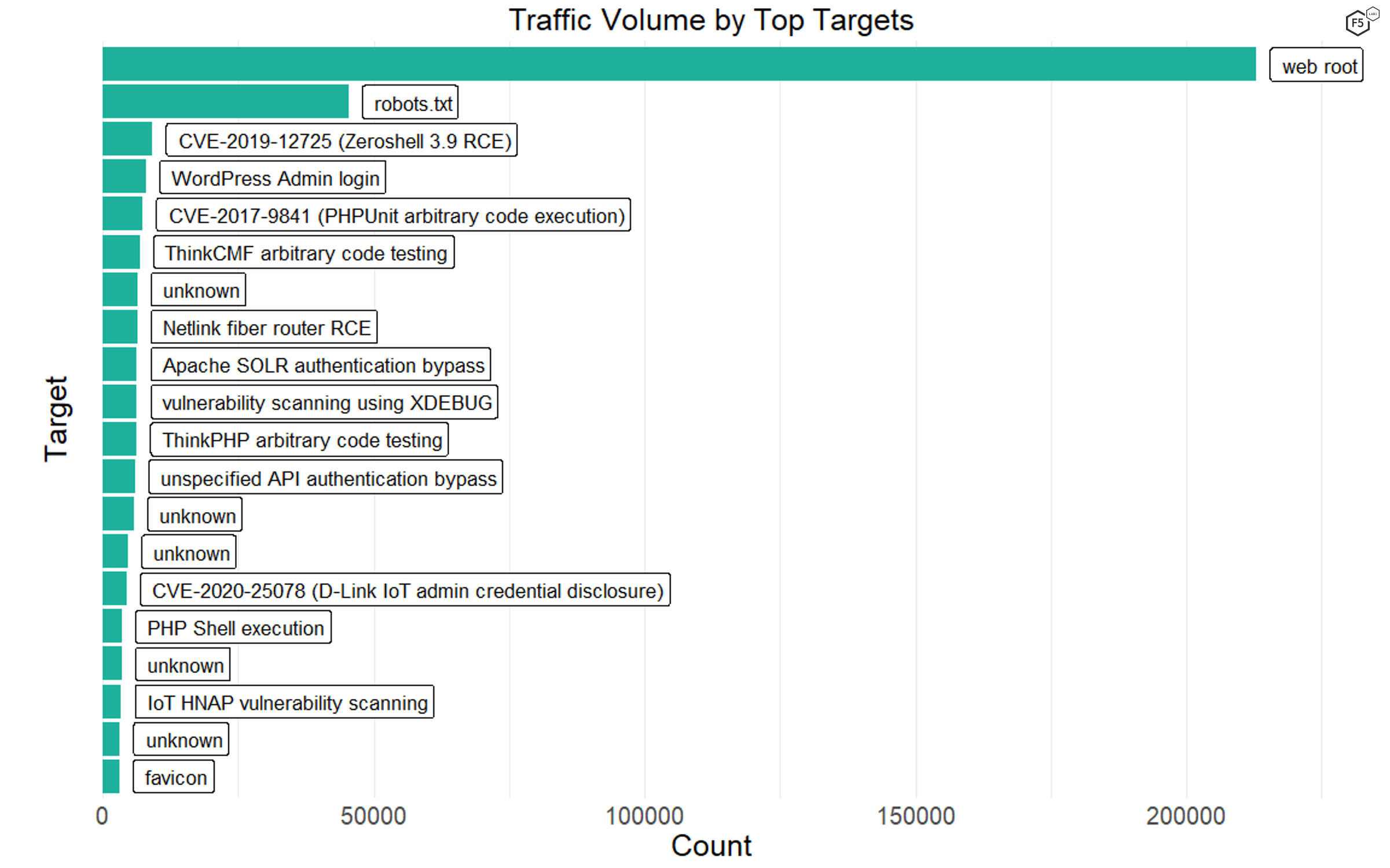
Figure 4. Top 20 target paths. Note several IoT vulnerabilities, a number of remote code execution vulnerabilities, and the favicon exploit, which grew in popularity over 2020.
One remarkable thing about the huge amount of traffic targeting Israeli assets was how much it focused on WordPress administrative portals, presumably for the purposes of credential stuffing or brute forcing their logins. In fact, though all of the traffic focused a fair amount on WordPress sites, 92% of the traffic connecting to /wp-login.php was against Israeli systems (see Figure 5).
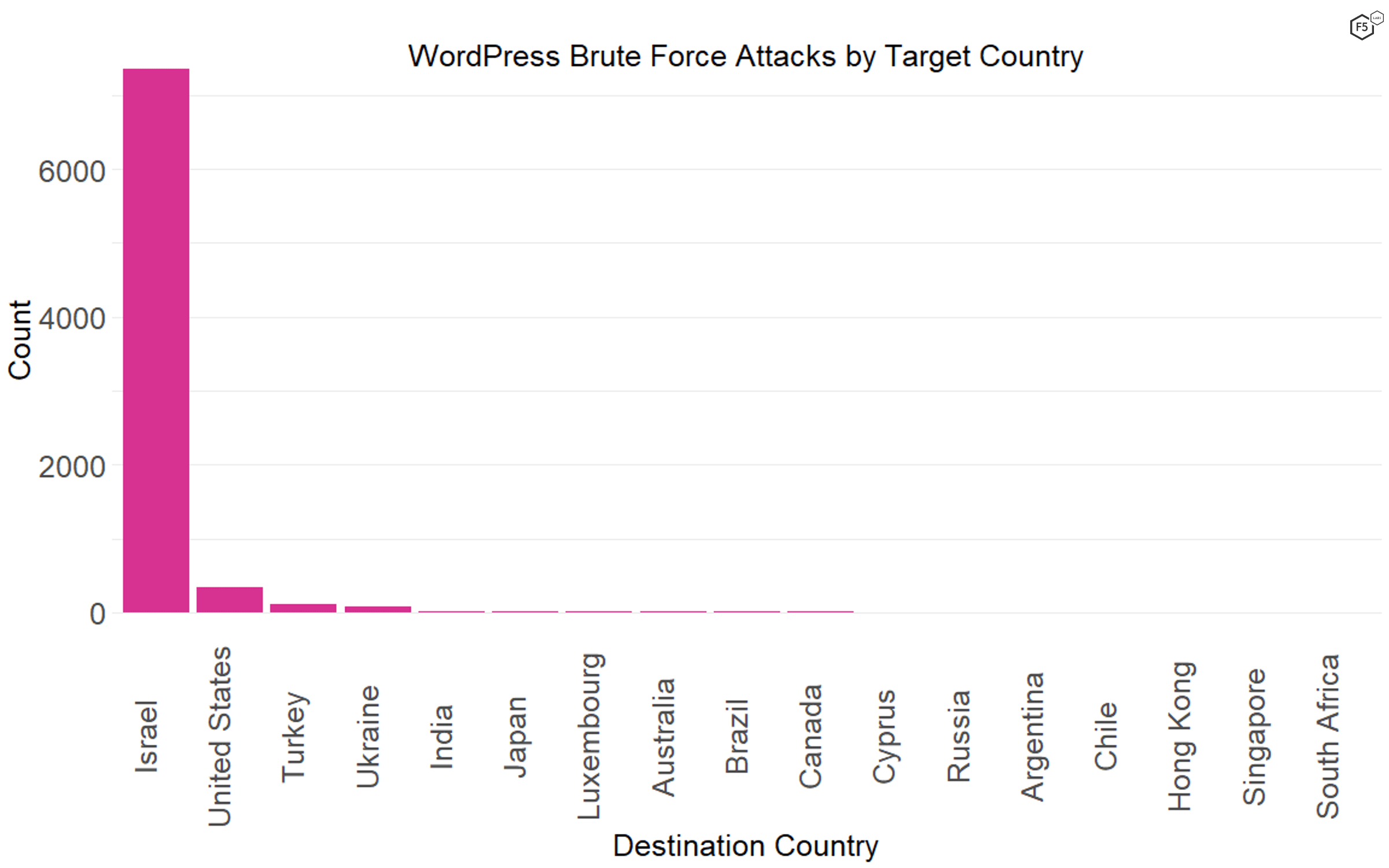
Figure 5. The distribution of WordPress administrative portal connections by geographic destination. Note that Israeli systems represented 92% of the traffic.
We can only speculate about the bigger objectives of attackers looking for Israeli WordPress sites to compromise—they could be geopolitical adversaries looking to get a foothold inside the country to launch further attacks against Israel or its allies, or they could be actors with zero interest in Israel who are looking to misdirect attention. Nevertheless, given the sophistication and reputation of the Israeli cybersecurity community, it is a good reminder that even Israel has easy targets like this. Every pool has a shallow end, and every place has assets that are either difficult to secure or poorly managed or, in the case of WordPress, often both.
What Do Attacks Look Like?
While analyzing targets and their prevalence can help defenders know whether their assets are at particular risk, we also wanted to get a sense of how threat actors and targets combine over time—in short, what these attack or reconnaissance campaigns actually look like in the wild.
As noted earlier, the vast bulk of the traffic was not contained within the most prevalent few actors or targets but was distributed across the long tails. When we analyzed IP address frequency against target frequency, we found less of a pattern than we expected, which mirrored the earlier observation that the most common targets and the most common actors only coincided in 0.2% of the data.
Figure 6 shows the distribution of IP addresses and target paths in the data, with each point representing a single connection. The axes rank frequency from left to right and bottom to top. The most common IP addresses and targets are in the lower left. If the frequencies of IP addresses and targets had a strong relationship, we would see a line from bottom left to upper right as the frequencies dropped in concert.

Figure 6. Comparison of IP address and target prevalence. We saw less of a pattern here than expected.
Instead we see clustering around specific paths across a larger number of less common IP addresses. In fact, the diagonal lines on the right side of the graph, showing a relationship between decreasing frequency in both measures, are misleading because the long tails in both variables mean that most of those connections only happened once.
Figure 7 shows that even when we just looked at the top 1% of IP addresses and targets, we found essentially no pattern.

Figure 7. Comparison of IP address and target prevalence for the top 1% of both variables. Even for the most common targets and actors, we found no relationship between frequencies.
We found surprisingly little consistency in terms of attacker targeting, with some of the most common IP addresses only targeting a six or seven paths, and some targeting more than eight hundred. Figure 8 shows the distribution of targets for three of the top 10 IP addresses. The most common IP address, shown here in blue, had only six targets in the data, one of which, the web root, it only targeted a small number of times. Similarly, the IP address marked in purple, which was ranked ninth in terms of overall traffic, had seven targets. However, the IP address marked in red had more than 800 unique targets in its list, most of which it requested fewer than 10 times.
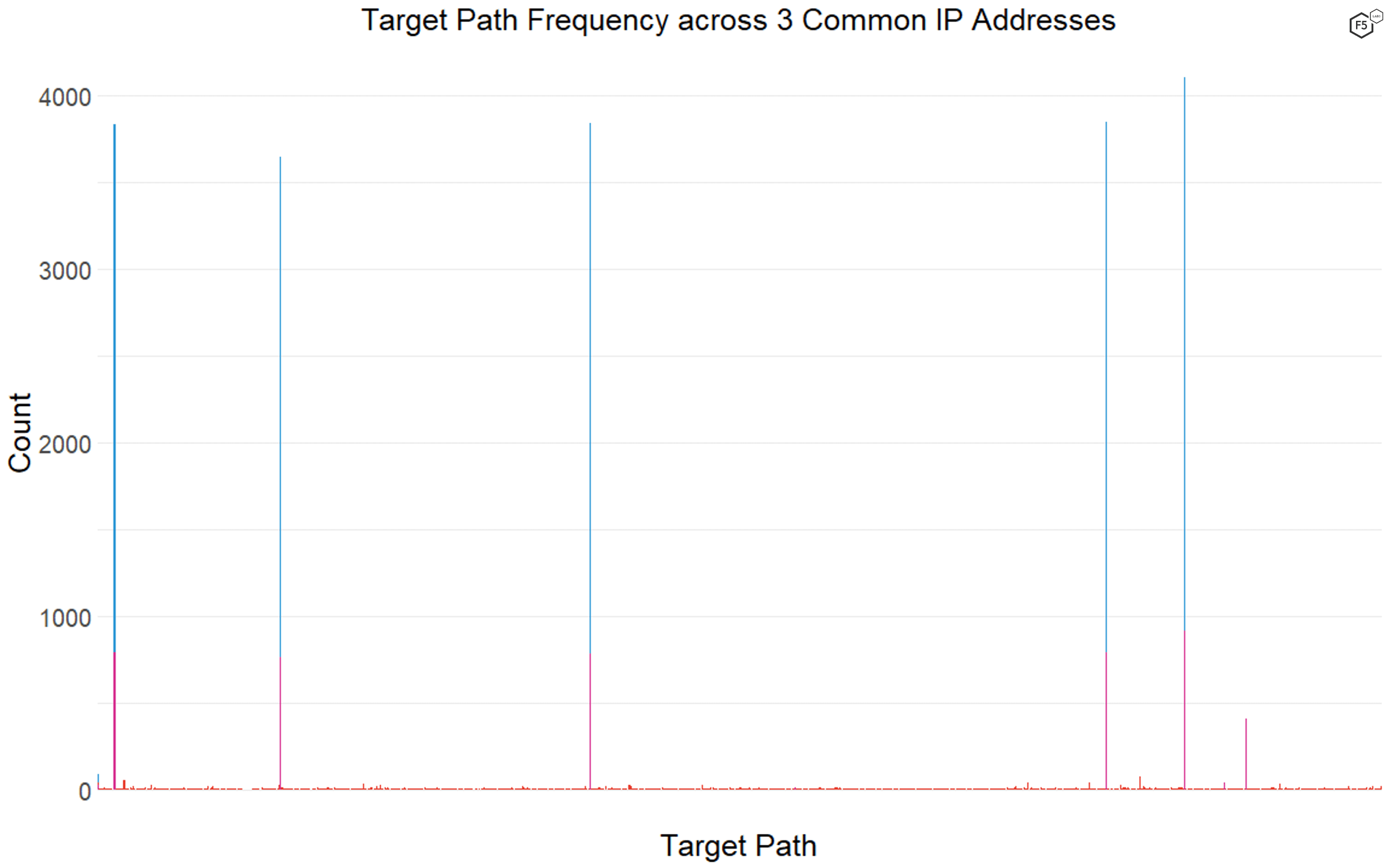
Figure 8. Comparison of target density across three frequently encountered IP addresses. The blue and purple bars show IP addresses with only six or seven targets across thousands of connections, whereas the red bars show an IP address with more than 800 targets.
The implication is that some threat actors have already selected their tactics and tools and know exactly what they’re looking for, while some are just getting the lay of the target landscape. Unfortunately, we didn’t identify any identifiable turning points in attack campaigns, in which a single IP address or a few IP addresses started with a wide net and eventually focused down to a few targets.
How Do Attacks Unfold Over Time?
As shown in Figure 9, some attacker IP addresses tend to be chatty, running attacks against targets continually for weeks at a time. Others tend to go on short, focused campaigns.
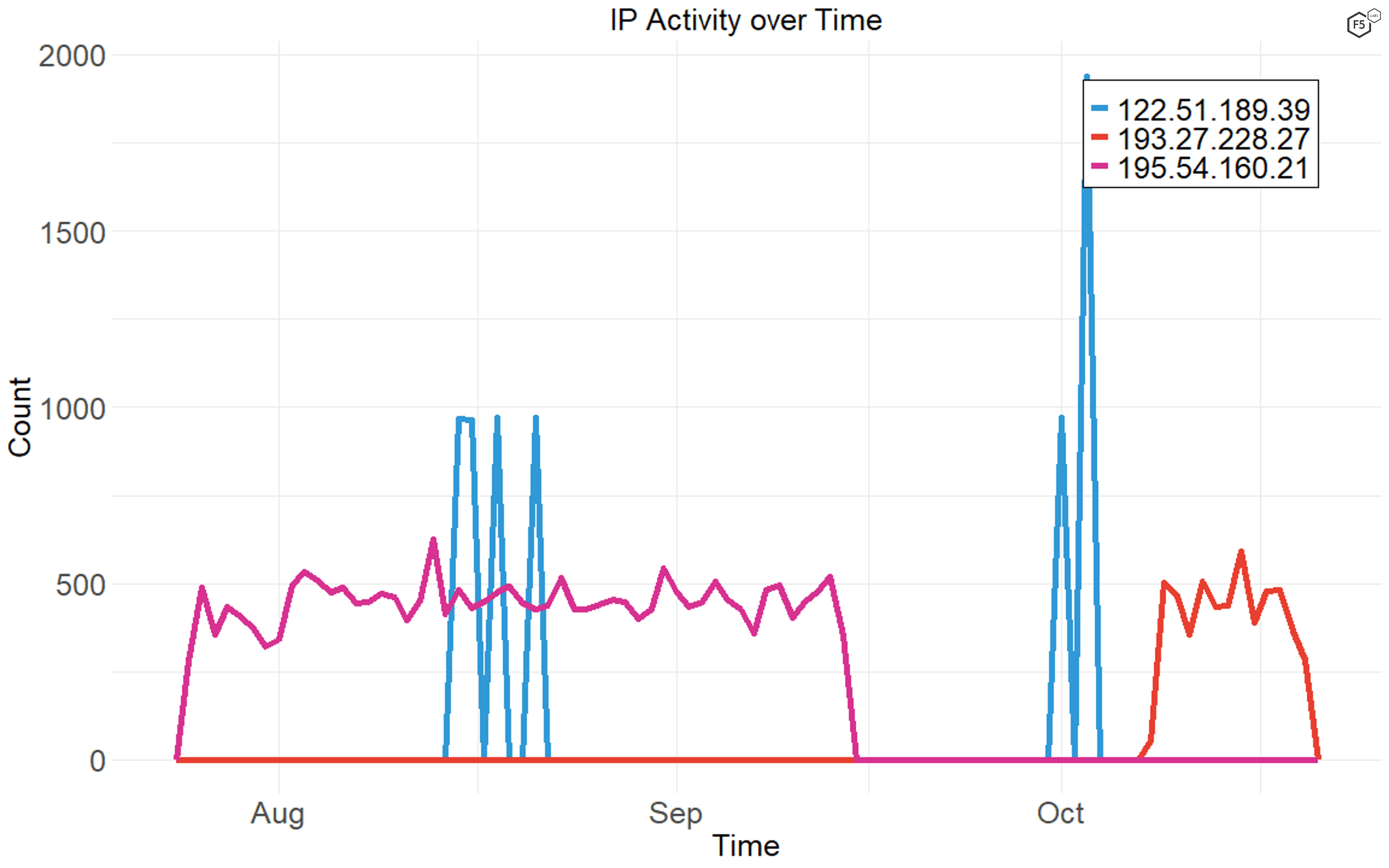
Figure 9. Distribution of connections over time by three commonly seen IP addresses. Some actors' activity is very tightly focused in time, while other actors maintain a smaller number of connections constantly over their campaign period.
In this case we found that the IP addresses that had short, focused bursts of activity, like 122.51.189.39, also tended to have a large number of targets (see Figure 10), whereas the attack sources that tended to be more gradual over time also went after a smaller number of targets (see Figure 11).
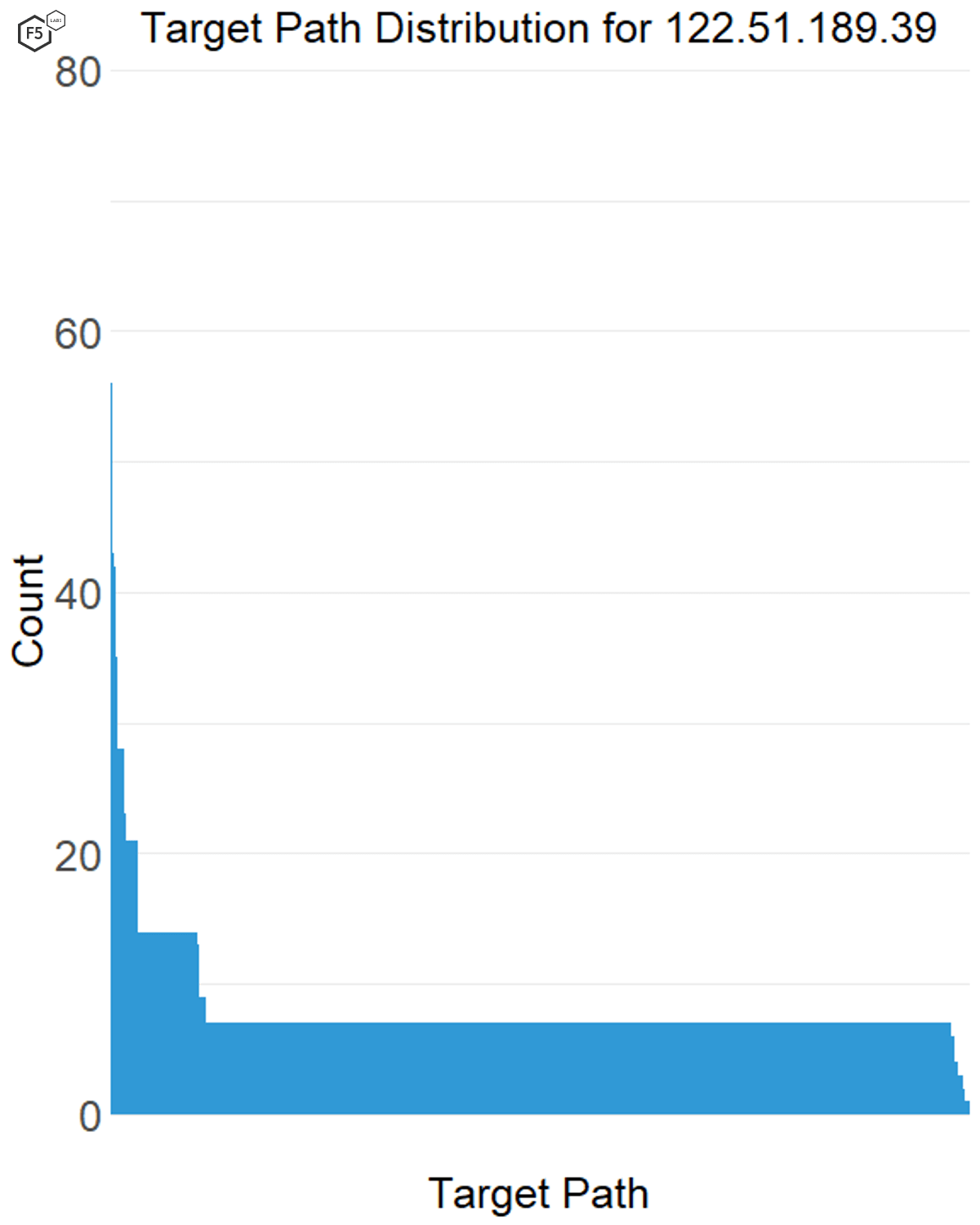
Figure 10. Distribution of traffic across targets for a single IP address. This IP address, 122.51.189.39, went after more than 800 targets but only connected to each one a few times.
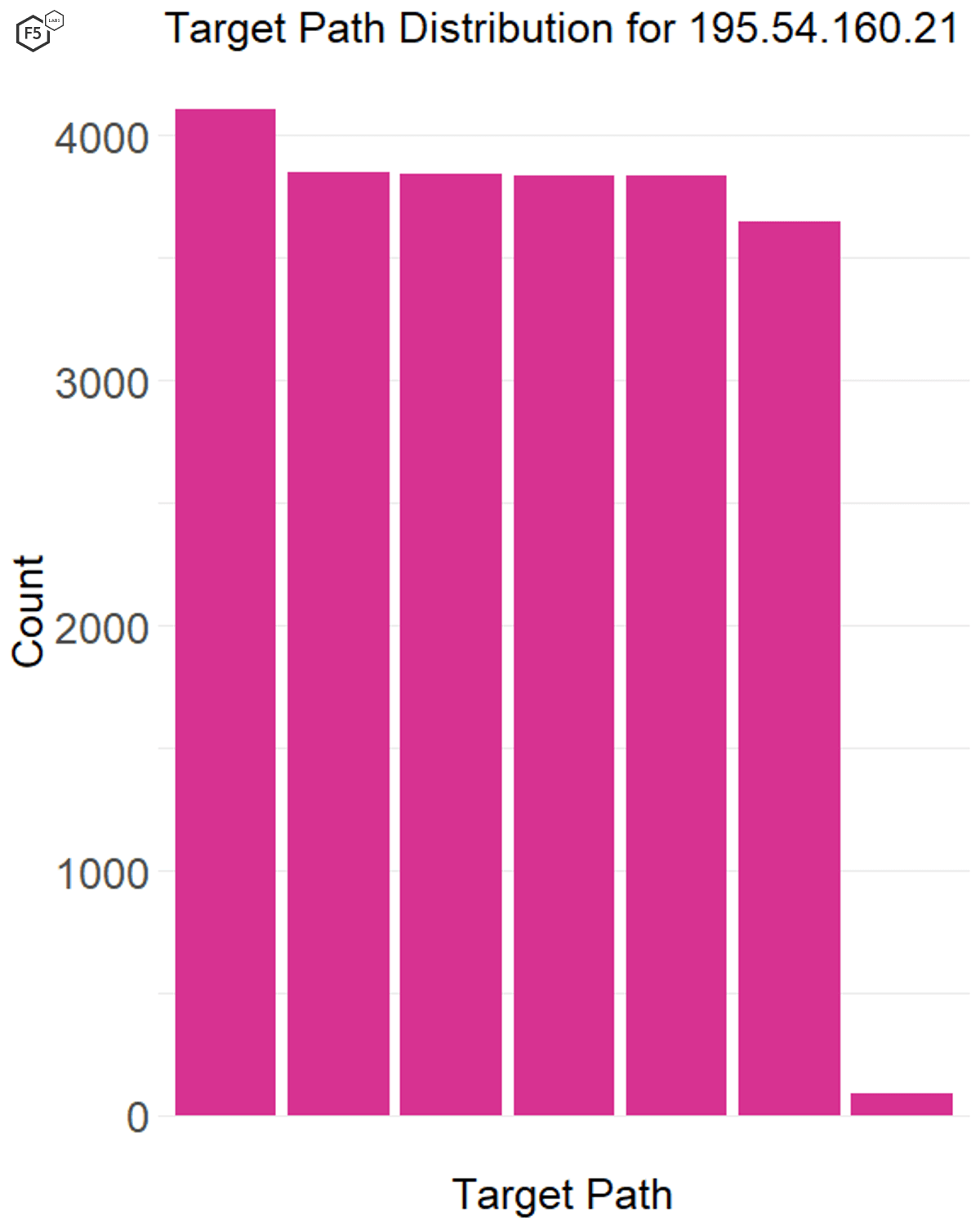
Figure 11. Distribution of traffic across targets for a single IP address. This IP address, 195.54.160.21, had only a few targets but produced “chatty” traffic, connecting to sensors several times a day for weeks at a time.
From this we can tentatively conclude that as attacks become narrower in targeting scope, attackers are less concerned about being detected through traffic volume alone. The increased precision of their traffic gives them a little more leeway in terms of timing and lets them look for specific targets and systems (such as specific IoT vulnerabilities or unprotected API endpoints) for the same given amount of traffic.
Conclusions
Sadly, this web attack data contains no smoking guns or leading indicators about the next big threat. Of course, since this is only a three-month sample, the future could easily look different. However, we can draw some broad conclusions based on what we saw in the third quarter of 2020:
- Long tails in the attacker IP address and target distributions indicate that the cyberattacks or scans that stand out in the logs are not necessarily the ones that will result in a compromise.
- IoT vulnerabilities remain tempting to attackers, with routers, cameras, and other small office, home office (SOHO) equipment showing up in the top 20 targets.
- PHP-based content management systems, including but not limited to WordPress, remain a focus for this end of the attacker spectrum. WordPress site owners should come up with a plan for patching and managing plugins to reduce their attack surface to the greatest degree possible.
- The campaign against Israeli WordPress sites is a reminder that even a place that we associate with information security talent and culture has its own batch of low-hanging fruit.
- For these kinds of unfocused attacks, we tend to see clustering in time or in targets, but rarely both.
- Attacks (including scans) vary widely in terms of traffic density over time, making it difficult to routinely detect a specific threat based on level of activity.
The best way to think about data from honeypots is like a water sample from a river. It will not tell us the direction the river is headed, or what the flow rate will be tomorrow, but it will tell us if there’s something in the water to watch out for. Inversely, the absence of a phenomenon in the sample doesn’t mean the absence of the phenomenon in the river. Just because a particular cyberattack isn’t captured here doesn’t mean it isn’t a threat, it just means that traffic didn’t occur in the time period and in the part of the Internet that Effluxio was watching.
Because we know that the honeypots serve no actual business purpose, the cyberattacks that show up here are inherently from the unfocused end of the threat landscape. These attackers might know which kinds of targets they want, or where in the world they want those targets to be, but any traffic showing up here doesn’t know which combination of location, technology, and information the attackers want to compromise. Because of that, the threat vectors represented here should signify a minimum bar, and the nature, timing, and targeting of these campaigns is a reminder that even high-end environments have low-end systems that might be vulnerable.
Recommendations
- Patch systems to the greatest degree possible. This is particularly important for WordPress systems and SOHO IoT devices.
- Review logs regularly and configure Security Information and Event Management and Intrusion Prevention Systems for anomalous traffic.


