
The Evolution of Application Delivery Controllers
Introduction
In today’s dynamic world, organizations constantly face the challenge of delivering critical applications to millions of users around the globe. It is extremely important that they deploy network and application services to make apps scalable, secure, and available. This is one of the prime reasons behind the evolution of Application Delivery Controllers (ADCs). However, none of these features can be implemented without a firm basis in basic load balancing technology. So, let’s begin with understanding the importance of load balancing, how it leads to efficient application delivery, and how ADCs are still evolving and embracing the cloud-first world.
Load Balancing Demand Drivers
The entire intent of load balancing is to balance the incoming network or application traffic across many physical servers—and make those servers look like one server to the outside world. There are many reasons to do this, but the primary drivers are the need for "scalability," "high availability," and "predictability."
Scalability is the capability of dynamically, or easily, adapting to increased load without impacting existing performance. High availability (HA) on the other hand, is the capability of a site to remain available and accessible even during the failure of one or more systems. Service virtualization (imitating the behavior of software components to accelerate and test application development) presents an interesting opportunity for both scalability and availability. If the service or point of user contact is separated from the actual servers, the application can be scaled by adding more servers. Moreover, the failure of an individual server will not render the entire application unavailable. Predictability is a little less clear as it represents pieces of HA as well as some lessons learned along the way. It can best be described as having control on how and when the services are being delivered with regard to availability and performance.
Load Balancing: A Historical Perspective
Back in the early days of the commercial Internet, many would-be dotcom millionaires discovered a serious problem in their plans. Mainframes didn't have web server software (not until the AS/400e, anyway) and even if they did, they couldn't afford them on start-up budgets. What they could afford was standard, off-the-shelf server hardware from one of the ubiquitous PC manufacturers. The main problem with most of them was that there was no way that a single PC-based server was ever going to handle the amount of traffic their business would generate. And if it went down, they were offline and out of business. Fortunately, some of those folks had plans to make their millions by solving that particular problem. This led to the birth of load balancing.
In the Beginning, There Was DNS
Before there were any commercially available, purpose-built load balancing devices, there were many attempts to utilize existing technology to achieve the goals of scalability and availability. The most prevalent (and still used) technology was DNS round-robin.
Under this method, the DNS would assign a number of unique IP addresses to different servers, under the same DNS name. This meant that the first time a user requested resolution for “www.example.com,” the DNS server would pass each new connection to the first server in line until it reached the bottom of the line—before going back to the first server again. This solution was simple and led to even distribution of connections across an array of machines.
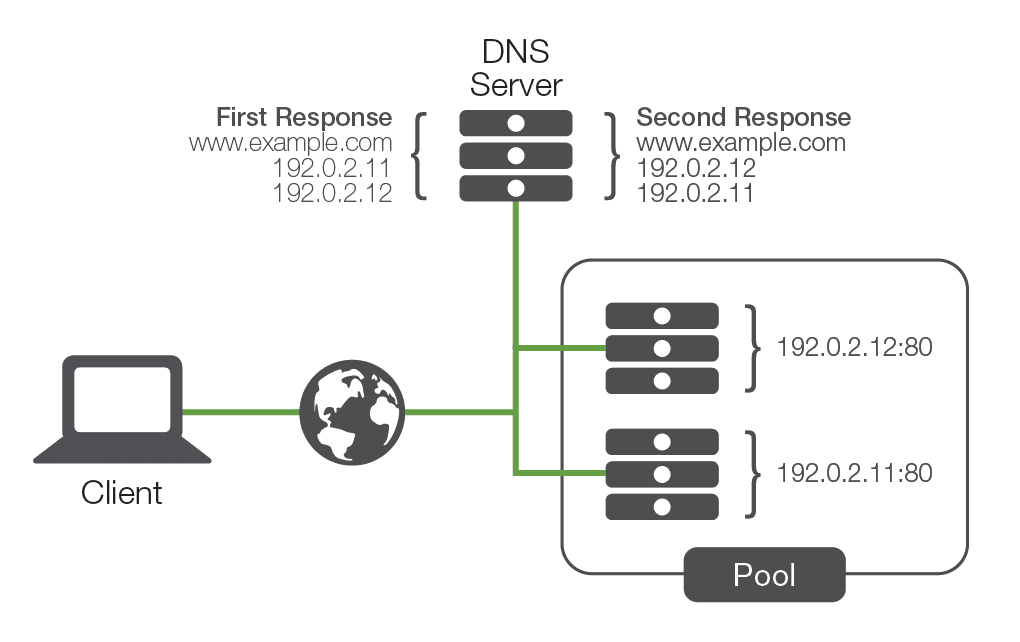
From a scalability standpoint, this solution worked remarkably well as it offered an opportunity to add almost limitless numbers of servers to a DNS name. However, regarding availability, the solution created roadblock as the DNS had no capability of knowing if the servers listed were working or not. If a server became unavailable and a user tried to access it, the request might be sent to a server that was down.
Another driver of DNS round-robin was predictability, which is a high level of confidence that a user is going to be sent to a particular server. This is centered around the idea of persistence—the concept of making sure that a user isn’t load balanced to a new server once a session has begun, or when the user resumes a previously suspended session. This is a very important issue that DNS round-robin couldn’t solve.
Proprietary Load Balancing in Software
To address this issue, one of the first purpose-built solutions was load balancing built directly into the application software or the operating system (OS) of the application server. While there were as many different implementations as there were companies who developed them, most of the solutions revolved around basic network trickery. For example, one such solution had all the servers in a pool (also known as cluster), in addition to their own physical IP address.
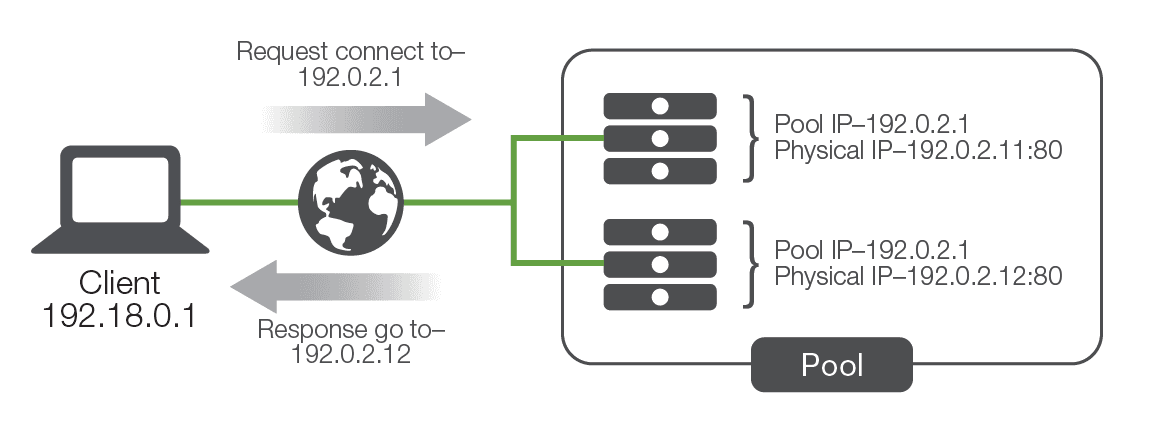
When users attempted to connect to the service, they connected to the pool IP instead of to the physical IP of the server. Whichever server in the pool responded to the connection request first would redirect the user to a physical IP address (either their own or another system in the pool), and the service session would start. One of the key benefits of this solution was that the application developers could use a variety of information to determine which physical IP address the client should connect to. For instance, they could have each server in the pool maintain a count of how many sessions each pool member was already servicing, then have any new requests directed to the least-utilized server.
Initially, the scalability of this solution was clear. All you had to do was build a new server, add it to the pool, and you grew the capacity of your application. Over time, however, the scalability of application-based load balancing came into question. Because the pool members needed to stay in constant contact with each other concerning who the next connection should go to, the network traffic between the pool members increased exponentially with each new server added to the pool. After the pool grew to a certain size (usually 5–10 hosts), this traffic began to impact end-user traffic as well as the processor utilization of the servers themselves. So, the scalability was great as long as you didn't need to exceed a small number of servers (incidentally, less than with DNS round-robin).
HA was dramatically increased with DNS round-robin and software load balancing. Because the pool members were in constant communication with each other, and because the application developers could use their extensive application knowledge to know when a server was running correctly, these solutions virtually eliminated the chance that users would ever reach a server that was unable to service their requests. It must be pointed out, however, that each iteration of intelligence-enabling HA characteristics had a corresponding server and network utilization impact, further limiting scalability. The other negative HA impact was in the realm of reliability. Many of the network tricks used to distribute traffic in these systems were complex and required considerable network-level monitoring. Accordingly, these distribution methods often encountered issues which affected the entire application and all traffic on the application network.
These solutions also enhanced predictability. Since the application designers knew when and why users needed to be returned to the same server instead of being load balanced, they could embed logic that helped to ensure that users would stay persistent if needed. They also used the same "pooling" technology to replicate user-state information between servers, eliminating many of the instances that required persistence in the first place. Lastly, because of their deep application knowledge, they were better able to develop load balancing algorithms based on the true health of the application instead of things like connections, which were not always a good indication of server load.
Besides the potential limitations on true scalability and issues with reliability, proprietary application-based load balancing also had one additional drawback: It was reliant on the application vendor to develop and maintain. The primary issue here was that not all applications provided load balancing (or pooling) technology, and those that did often did not work with those provided by other application vendors. While there were several organizations that produced vendor-neutral, OS-level load balancing software, they unfortunately suffered from the same scalability issues. And without tight integration with the applications, these software "solutions" also experienced additional HA challenges.
Network-Based Load Balancing Hardware
The second iteration of purpose-built load balancing came about as network-based appliances. These are the true founding fathers of today's Application Delivery Controllers. These appliances physically resided outside of the applications themselves and though they started as load balancers, achieved their load balancing using much more straightforward network techniques like NAT. These devices would present a virtual server address to the outside world and when users attempted to connect, the devices would forward the connection on the most appropriate real server.
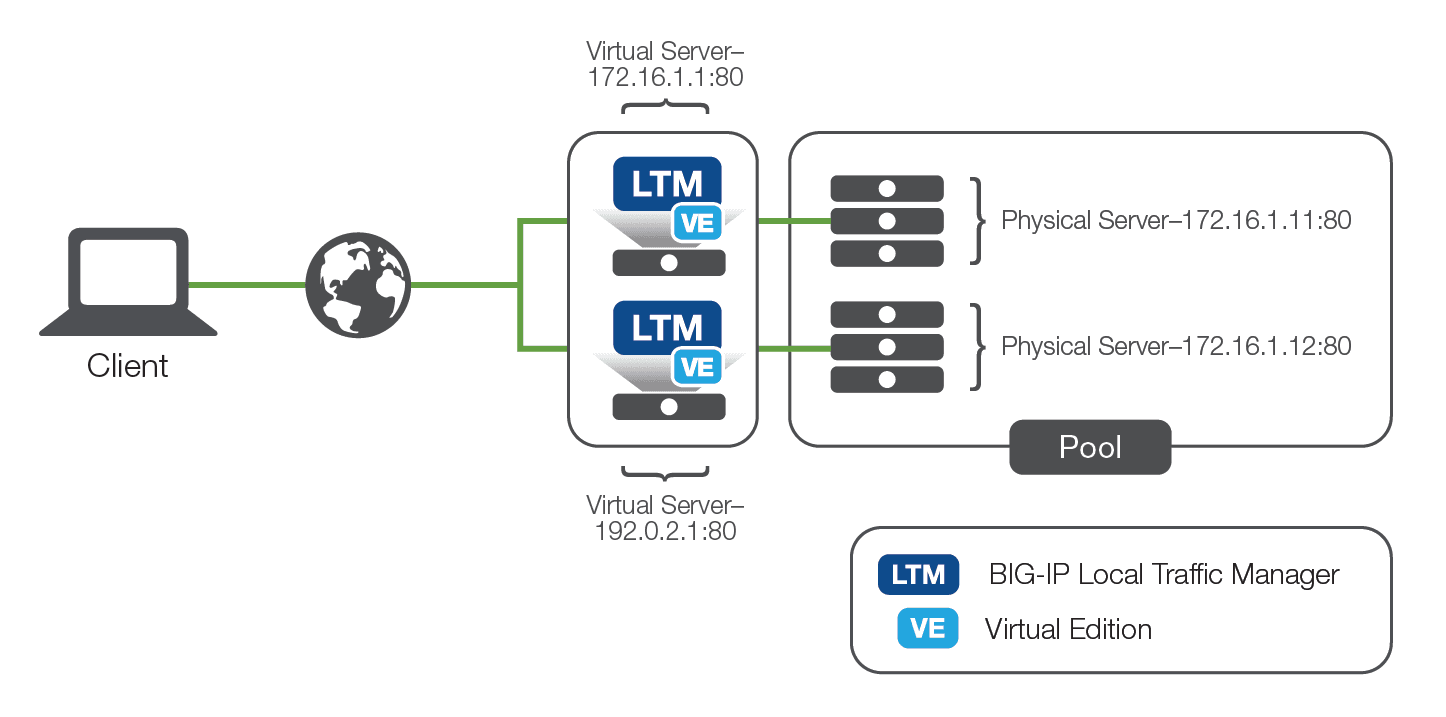
The load balancer could control exactly which server received which connection and employed "health monitors" of increasing complexity to ensure that the application server (a real, physical server) was responding as needed. If the server was not responding correctly, the load balancer would automatically stop sending traffic to that server until it produced the desired response. Although the health monitors were rarely as comprehensive as the ones built by the application developers themselves, the network-based hardware approach could provide basic load balancing services to nearly every application in a uniform, consistent manner—finally creating a truly virtualized service entry point unique to the application servers.
From a scalability point of view, organizations that started replacing software-based load balancing with a hardware-based solution saw a dramatic drop in the utilization of their servers. This kept them from having to purchase additional servers in the short term and helped generate increased ROI in the long term.
Similarly, HA helped reduce the complexity of the solution and provide application-impartial load balancing—leading to greater reliability and increased depth as a solution. Network-based load balancing hardware enabled the business owner to provide a high level of availability to all their applications instead of the select few with built-in load balancing.
Predictability was a core component added by the network-based load balancing hardware. It was now much easier to predict where a new connection would be directed and much easier to manipulate. These devices added intelligence to the process, which in turn helped to create controlled load distribution (as opposed to the uncontrolled distribution of dynamic DNS). This allowed business owners to distribute load to servers based on the server’s ability to handle the load.
The advent of the network-based load balancer and virtualization brought about new benefits for security and management, such as masking the identity of application servers from the Internet community and providing the ability to "bleed" connections from a server so it could be taken offline for maintenance without impacting users. This is the basis from which ADCs originated.
Application Delivery Controllers
With a central load balancing function, which is also a full-proxy, IT saw a great place to layer on and consolidate new and emerging services. This led to a load balancing device evolving to an extensible ADC platform. Simply put, proxy is the basis for load balancing and the underlying technology that makes ADCs possible.
When discussing ADC security, the virtualization created by proxy (the base technology) is critical. Whether we discuss SSL/TLS encryption offload, centralized authentication, or even application-fluent firewalls, the power of these solutions lies in the fact that a load balancer (hardware or virtual edition) is the aggregate point of virtualization across all applications. Centralized authentication is a classic example. Traditional authentication and authorization mechanisms have always been built directly into the application itself. Like the application-based load balancing, each implementation was dependent on and unique to each application's implementation—resulting in numerous and different methods. Instead, by applying authentication at the virtualized entry point to all applications, a single, uniform method of authentication can be applied. Not only does this drastically simplify the design and management of the authentication system, it also improves the performance of the application servers themselves by eliminating the need to perform that function. Furthermore, it also eliminates the need—especially in home-grown applications—to spend the time and money to develop authentication processes in each separate application.
Availability is the easiest ADC attribute to tie back to the original load balancer, as it relates to all the basic load balancer attributes: scalability, high availability, and predictability. However, ADCs take this even further than the load balancer did. Availability for ADCs also represents advanced concepts like application dependency and dynamic provisioning. ADCs are capable of understanding that applications now rarely operate in a self-contained manner: They often rely on other applications to fulfill their design. This knowledge increases the ADC’s capability to provide application availability by taking these other processes into account as well. The most intelligent ADCs on the market also provide programmatic interfaces that allow them to dynamically change the way they provide services based on external input. These interfaces enable dynamic provisioning and the automated scale up/down required for modern environments like cloud and containerized deployments.
Performance enhancement was another obvious extension to the load balancing concept. Load balancers inherently improved performance of applications by ensuring that connections were not only directed to services that were available (and responding in an acceptable timeframe), but also to the services with the least amount of connections and/or processor utilization. This ensured that each new connection was being serviced by the system that was best able to handle it. Later, as SSL/TLS offload (using dedicated hardware) became a common staple of load balancing offerings, it reduced the amount of computational overhead of encrypted traffic as well as the load on back-end servers—improving their performance as well.
Today's ADCs go even further. These devices often include caching, compression, and even rate-shaping technology to further increase the overall performance and delivery of applications. In addition, rather than being the static implementations of traditional standalone appliances providing these services, an ADC can use its innate application intelligence to only apply these services when they will yield a performance benefit—thereby optimizing their use.
For instance, compression technology—despite the common belief—is not necessarily beneficial to all users of the application. Certainly, users with small bandwidth can benefit tremendously from smaller packets since the bottleneck is actual throughput. Even connections that must traverse long distances can benefit as smaller packets mean fewer round trips to transport data, decreasing the impact of network latency. However, short-distance connections (say, within the same continent) with large bandwidth might perform worse when applying compression. Since throughput is not necessarily the bottleneck, the additional overhead of compression and decompression adds latency that the increased throughput does not make up for from a performance perspective. In other words, if not properly managed, compression technology as a solution can be worse than the original problem. But by intelligently applying compression only when it will benefit overall performance, an ADC optimizes the use and cost of compression technology, leaving more processor cycles for functions that will get the most use out of them.
Where the World Is Headed
Because digital transformation is such an important strategic imperative, many enterprises have started embarking their journey to the cloud. With the increasing number of applications rising and changing the world around us, it is believed that organizations moving to the cloud will enjoy many benefits such as greater agility, better-aligned operational cost, on-demand scalability, and more focus to their core business.
The “cloud” isn’t an amorphous single entity of shared compute, storage, and networking resources; rather, it is composed of a complex mix of providers, infrastructures, technologies, and environments that are often deployed in multiple global nodes. This is the reason many enterprises have actually deployed applications into a number of different clouds—public, private, and even combination of them all. This is multi-cloud: the new reality.
Even with this rapidly evolving landscape, several factors are slowing the cloud adoption. The first challenge is the multi-cloud sprawl, where existing applications have been “lifted and shifted,” and “born-in-the-cloud” applications have been deployed in an unplanned and unmanaged manner. In addition, to meet their short-term needs, organizations tend to use disparate cloud platforms, different architectures, varying application services, and multiple toolsets. This results in architectural complexity across the enterprise, and makes shifting applications from one environment to another much more difficult, not to mention expensive.
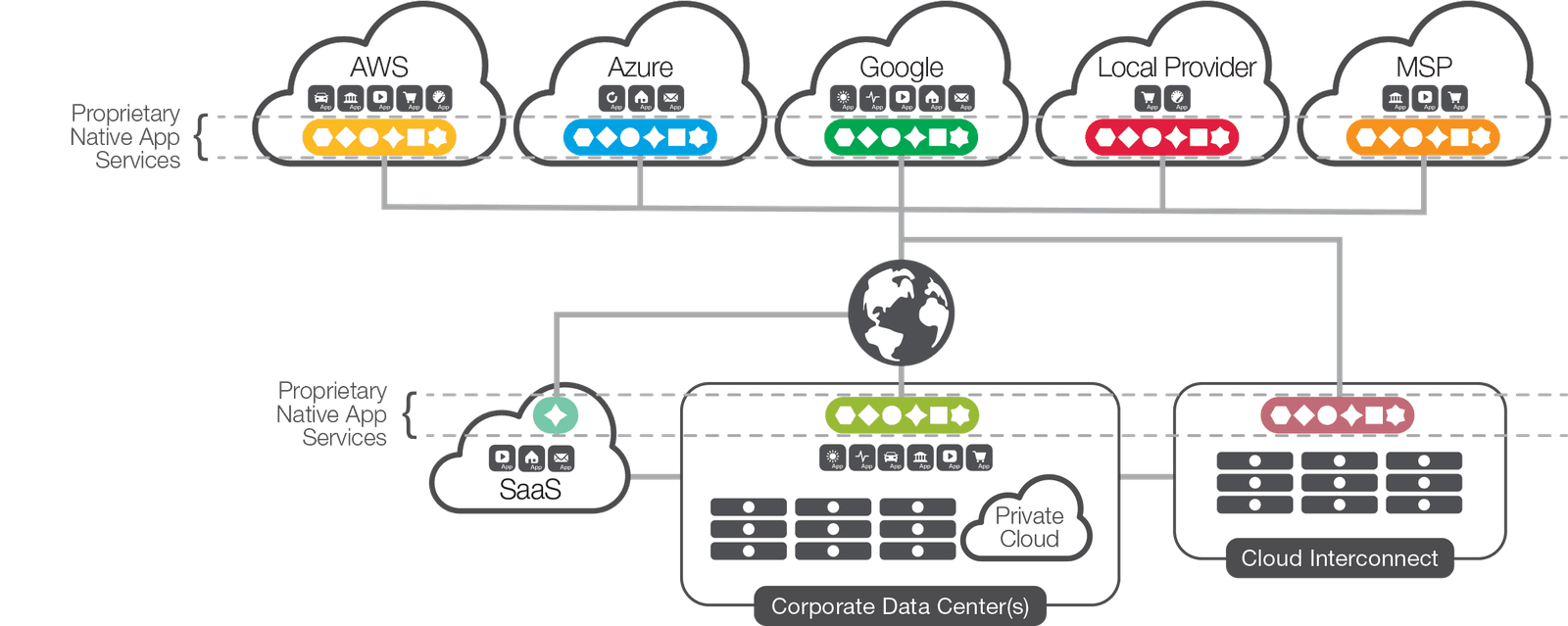
Despite these challenges, new deployments in and across public and private clouds will inevitably increase in the coming years. Multi-cloud is fast approaching and it’s time for enterprises to deploy smart application services and ADCs that do more than support limited applications, or operate only in hardware and single cloud.
Summary
ADCs are the natural evolution to the critical network real estate that load balancers of the past held. While ADCs owe a great deal to those bygone devices, they are a distinctly new breed providing not just availability, but performance and security. As their name suggests, they are concerned with all aspects of delivering an application in the best way possible.
With advanced features such as application intelligence, SSL offload, and programmatic interfaces, modern ADCs can help organizations scale their business and reach users anywhere, at any time. With the ever-changing needs of the technical world, the ADCs are also more capable of adapting themselves to the newest technologies in multi-cloud and container environments.
In the end, we can safely say that ADCs will not only be the primary conduit and integration point through which the applications will be delivered in a faster, smarter, and safer way, but will continue to evolve and embrace the cloud-first world.
PUBLISHED SEPTEMBER 10, 2017