
At the heart of availability is monitoring. Every load balancer – before it chooses a target resource – has to know whether that resource is actually available or not. Otherwise, what’s the point?
In environments where resources have lifetimes that might be measured in minutes rather than hours or days, it becomes even more critical to know the status of resources before a decision is made to send a request to it.
Health monitoring is part and parcel of load balancers and proxies. That’s true (or should be true) within containerized environments, as well. As these environments continue to mature (rapidly) we’re seeing new models of monitoring emerge to combat the somewhat unique challenges associated with such highly volatile, distributed systems.
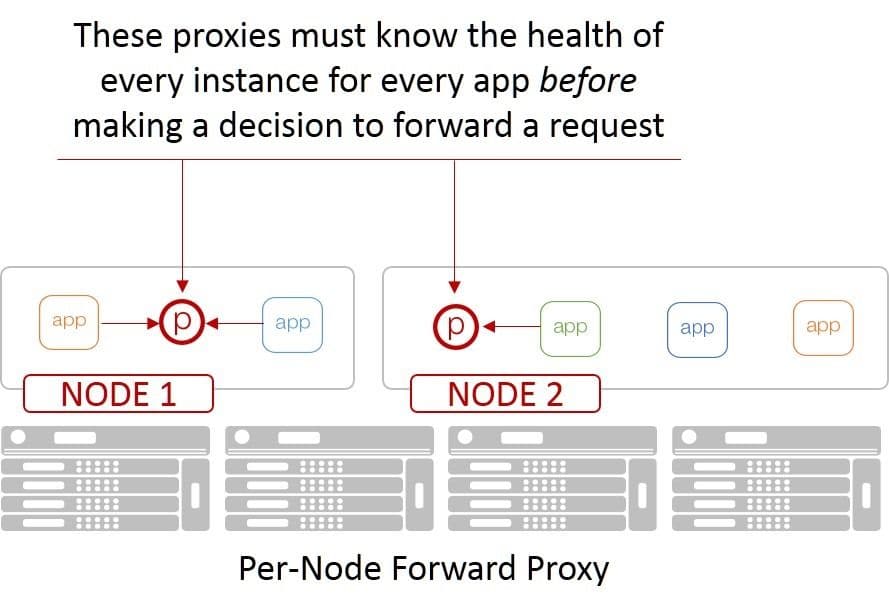
Traditional health monitoring is certainly part of the equation, but some models of availability and scale inside container environments put strains on traditional health monitoring that must be addressed. For example, proxies deployed in a forward proxy model are expected to be able to select a healthy (available) target across all possible services. Where a reverse proxy (a traditional load balancer, if you will) is only responsible for tracking the state of a very specific set of services for a single application, a forward proxy is responsible for knowing the state of every service for every application in the environment. Because sending a request to already out-of-service container would be bad, m’kay?
Traditional Health Monitoring
Traditionally, health monitoring is accomplished by a proxy in two ways:
- Active Monitoring: Sending probes or health check requests to containers and evaluating their responses.
- Passive Monitoring: Observing natural client requests and their responses.
You can imagine that active monitoring by every forward proxy of every service is going to rather dramatically increase the traffic on the local network and unnecessarily consume resources. Useful monitoring occurs at at least the TCP and ideally the HTTP layers. Network connectivity is not an indicator of service health or availability, after all. Consuming TCP connections and requiring HTTP processing will quickly place burdens on containers as the number of nodes (and thus forward proxies) increases. You don’t want to have to scale up because containers are overwhelmed by monitoring.
Passive monitoring is a better option in this case, in that it doesn’t place a burden on the system being monitored, but it does have its limitations in some container environments. Many are built upon overlay networking principles that make it challenging to ensure every proxy can see every service response and track it. Not impossible, but challenging at the networking layer.
Both models place a burden on the proxy itself, too, requiring resources be dedicated to merely monitoring the environment rather than on the task they’re in place to perform: scaling services.
Containerized Health Monitoring
Container environments are not ignorant of these challenges. In response, we’re seeing two new models emerging that that will certain help to ensure availability in architectures employing forward proxies for availability and scale.
Those two models are:
- Environmental Monitoring: Proxies are aware of health/availability thanks to information from the Container Orchestration Environment (COE) about container health.
- Shared Monitoring: Because there are likely to be many proxies in an environment, the monitoring work can be divided across proxies and the results shared.
Environmental monitoring is often associated with the service registry, which tracks containers as they enter and leave the system. That means it’s often the most authoritative source of container availability in the system. Proxies can also subscribe to events triggered by creation and destruction of containers in order to keep track of those resources themselves (in effect, acting as a registry themselves).
For example, if health monitoring is enabled for an app in Marathon, a proxy can make use of the 'healthCheckResults' field. In Kubernetes, proxies can use liveness and/or readiness checks. Environmental health checks allow proxies to begin selecting healthier endpoints before the orchestration system restarts an unhealthy one.
Shared monitoring makes a lot of sense in systems employing forward proxy models, notably those with a service-mesh foundation like Istio. The proxy associated with the node can certainly manage to monitor the health and availability of those containers for which it is forwarding requests (much in the same way it might keep track of services in a reverse proxy model). But you certainly don’t want every proxy actively probing every endpoint in such a system. So by sharing local health information with other proxies (or with the environment, even better), the entire known state of the system can be obtained by all proxies without requiring excessive health checks on every service.
There’s a lot of changes going on in “the network” with respect to app services like load balancing and how they interact to meet the needs and requirements of new models like containerization. These requirements are constantly putting pressure on proxies to adapt. That’s because proxies are one of the most flexible technologies to be develop in the past twenty years and continue to be a signification foundation upon which app services are designed, developed, and deployed.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

F5 joins the Dell AI Ecosystem Program to help enterprises operationalize AI
F5 joins the Dell AI Ecosystem Program to help enterprises deploy production AI with greater performance, security, and control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.