
This is the third blog in a series of blogs that cover various aspects of what it took for us to build and operate our SaaS service:
- Control plane for distributed Kubernetes PaaS
- Global service mesh for distributed applications
- Platform security for distributed infrastructure, apps, and data
- Application and network security of distributed clusters
- Observability across a globally distributed platform
- Operations & SRE of a globally distributed platform
- Golang service framework for distributed microservices
My initial blog provided some background on the needs that led us to build a new platform for distributed clouds. Using this platform, our customers build a complex and diverse set of applications — like smart manufacturing, video forensics for public safety, algorithmic trading, and telco 5G networks.
Since many of these applications are mission-critical, our customers expect that we not only deliver multi-layer security but also have the ability to make continuous improvements to keep their distributed clusters secure. This specific blog will tackle the challenges of securing infrastructure, applications, and data across multiple clusters.
TL;DR (Summary)
- While it is relatively well understood how to provide secure access for users and employees to applications (we do this every day when we access our bank accounts or our corporate emails), it is not as straightforward to do the same for app-to-app or app-to-data access as there is no human involved in the verification process.
- Securing apps and data in a heterogeneous environment (edge, multiple clouds, and network PoPs) required us to solve a multi-layer problem — identity, authentication & authorization, secrets, and key management
- Even though there are many point solutions available (eg. multiple services from individual cloud providers, Hashicorp Vault, SPIFFE/Spire etc) to these four problems — there does not exist an integrated solution that works across cloud providers or seamlessly combines each of these services for ease of use.
- Given a lack of expertise within our developer and DevOps teams on how to bring these pieces together, it became essential for our platform team to deliver these capabilities as an integrated solution that was easy to use. The evolving security landscape and new technologies make it even harder for these teams as they don’t have the necessary expertise or the bandwidth to keep up with all the changes.
- As part of delivering multi-layer platform security, we built new software components that solved three critical problems in an entirely new way — securely bootstrapping a universal identity that does not suffer from the problem of “turtles all the way down”, secrets that can be stored and disbursed without ever worrying about compromise of a central vault (goldmine problem), and distributed key management to ease security of data-at-rest.
Background on the Security Problem
As stated in the above — the problem of securing user access to applications (for example, access to our bank accounts or our emails) is well understood. However, it is not as straightforward to do the same for app-to-app or app-to-data access as there is no human involved in the verification process.
For an application to access another resource in a secure manner — for example, data stored in an object store or make an API call to another application, etc — the following needs to happen:
- Identity — the requestor needs to securely acquire a verifiable identity that can be used for Authentication and Authorization purposes when accessing the required resources. The requestor also needs to be securely provisioned with necessary trust anchors that can be used to verify peers’ identities.
- Authentication — In the process of accessing a given resource, the requestor and the resource owner need to securely verify each other’s identity. The process of verifying a peer’s claimed identity against the presented identity is called Authentication.
- Authorization — once the requestor is authenticated, the process of checking whether it is allowed to access the resource (or not) is called Authorization.
As part of the authentication process, the requesting application can present its identity in the form of a PKI certificate or a secret (e.g. a password) or a key. There are two issues that need to be addressed when using secrets or a key for identity:
- The secrets and keys should not be stored directly in the code, as that is an easy attack vector and leaked keys can be a big problem.
- If the secrets are stored in an external vault, then what identity (usually another secret) should be used to obtain the secret and how do we secure this identity to obtain the secret?
Performing these security operations (for app-to-app interaction) in a reliable and repeatable manner is a non-trivial problem. There are many reasons why this is non-trivial:
- Applications can be easily cloned and spawned (e.g. microservices). How to assign a unique identity to each clone that may be required for forensics, auditing or observability purposes?
- Application identity will be different depending on the environment it is running in. For example, in development vs. production, the application is the same, but it needs a different identity in each environment.
- How to build trust that the infrastructure in which the application is being spawned will not steal the identity or secrets and keys without being noticed?
- How to secure the central vault against attacks and secure all the secrets and keys stored in this vault?
As a result, securing infrastructure, applications and data across a dynamic environment is a very challenging problem. While cloud providers have risen up to this challenge and provided a lot of tooling to deal with these problems, integrating and maintaining these is not easy for the following reasons:
- Complexity — Each cloud provider requires the customer to configure and manage multiple services. For example in AWS - metadata service, IAM roles, service account, RBAC, KMS and secrets manager. Each of these services is very different in each cloud provider — both in their semantics, APIs, and monitoring.
- Interoperability — Even when cloud provider services are configured and operationalized, none of these allow for interoperability. For example, a VM running in GCP cannot access a resource in AWS because the identity assigned using the GCP service account is not understood by an AWS resource.
- Heterogeneous Environments — If the environment is spread across public and private clouds, or multiple public clouds, or — worse — at the edge, the challenge will be how and where to store secrets like passwords, keys, etc — centrally or distributed.
- Environment specific — The solution for credentials rotation and/or revocation is very different in each of the cloud providers while none of this exists for edge clusters.
While many enterprises are a single cloud provider and it may be good enough for them to invest resources in managing and enhancing the security primitives from that provider, we operate in a heterogeneous environment (hybrid-cloud and edge) and had to build a new solution to solve these problems.
Solution for Securing a Distributed Platform
Our team was tasked with providing security for the applications, infrastructure, and data that may reside across a distributed infrastructure as shown in Figure 1.

As a result, our platform team decided to build new software services that integrated the following four aspects to deliver platform security across the edge, any cloud and our network PoPs:
- Identity Management — we will describe how we deliver cryptographically secure and unforgeable PKI-based identity to not only applications, but also the infrastructure that is distributed across a heterogeneous environment (multiple clouds, our global PoPs, and geographically spread out edge locations) and operating as multiple environments (eg. developer machine, unit test, production, etc)
- Authentication and Authorization — our infrastructure is built on microservices that make use of a PKI-based identity and mutually authenticate all communications regardless of the communication protocol in use. We also decoupled authorization from authentication so that a common authorization engine can be used for a variety of authorization decisions and the policy structure can be unified.
- Secrets Management System — there are many types of secrets (like TLS certificates, passwords, tokens, etc) that are needed by our software, as well as customer workloads. The simplest method could have been to adopt a centralized vault where all the secrets are stored, but this approach had the downside that any compromise will reveal all the secrets. We will describe a different approach that we implemented to achieve a higher level of security by giving up some simplicity.
- Key Management System (KMS) — data security is critical for our distributed system and the team had to deliver a KMS that works seamlessly across cloud providers. The KMS has to manage, version and rotate keys that are used for symmetric encryption and decryption of data-at-rest, HMAC of CSRF tokens, and digitally sign binaries. We will discuss how we provide capabilities for both security-sensitive operations using this KMS and latency-sensitive operations using the secrets management system.
Unforgeable Identity for Infra and Apps
Identity is a fundamental issue as many security challenges can be tackled more easily once the identity problem is solved. However, to solve for identity, we need to define what we mean by it and how to issue identity in a reliable manner. Crypto geeks like to have their own spin on everything, and the definition of identity is no exception:
The unique and entire set of unforgeable and cryptographically verifiable characteristics cryptographically certified via an undelegated and secure protocol by a trusted authority that make up what a person or thing is known or considered to be.
n essence, what is needed is an unforgeable and cryptographically verifiable identity delivered securely. Issuing such an identity is challenging for two reasons: 1) bootstrapping of identity and 2) root-of-trust
There are a few approaches that get discussed often in relation to identity — SPIFFE and Hashicorp Vault. We would clarify that SPIFFE is a naming scheme that could be used in our system as an identity document (X.509 certificate) — however, the format is not suitable for some identity attributes that contain binary data. While Vault can be used to issue an identity document, it does not solve the challenges of Bootstrapping of Identity and Root of Trust problem:
- Bootstrapping of Identity — in real life, when a person is born, his/her identity is established by the birth certificate. This logically bootstraps the identity of the person and using this certificate the person can derive/request more identity certificates such as passport, driver’s license, etc. Similarly, in the computing world, every launch of an application (or a microservice) needs to bootstrap an identity. The establishment of identity is one of the first steps any running code needs to perform in order to be able to interact with other services. In addition, since the same application code may be launched multiple times and in different environments `(developer laptop vs. unit test vs. production), it is also required that each of these launches establish a separate bootstrap identity.
- Root of Trust — while issuing a bootstrap identity may seem like a straightforward process, the problem is who gets to provision this identity. For example, in the real world, provisioning of identity begins with the hospital asserting the fact that a child was born on a given date+time to a particular person and an assumption is made that the hospital is minting the birth record with proper checks and cannot be forged. As a result, the birth record document can be used as a source-of-truth (or root-of-trust). Similarly, when an application is launched by a human or automated code, there needs to be a root-of-trust that can verifiably assert the identity of the application that was launched. This assertion can then be used to generate a subsequent identity document for the application.
For example, when a VM is launched in AWS it is provided with a bootstrap identity and the metadata service of AWS acts as the root-of-trust. The identity document (that is signed by AWS using their own cryptographic key) looks something like this:
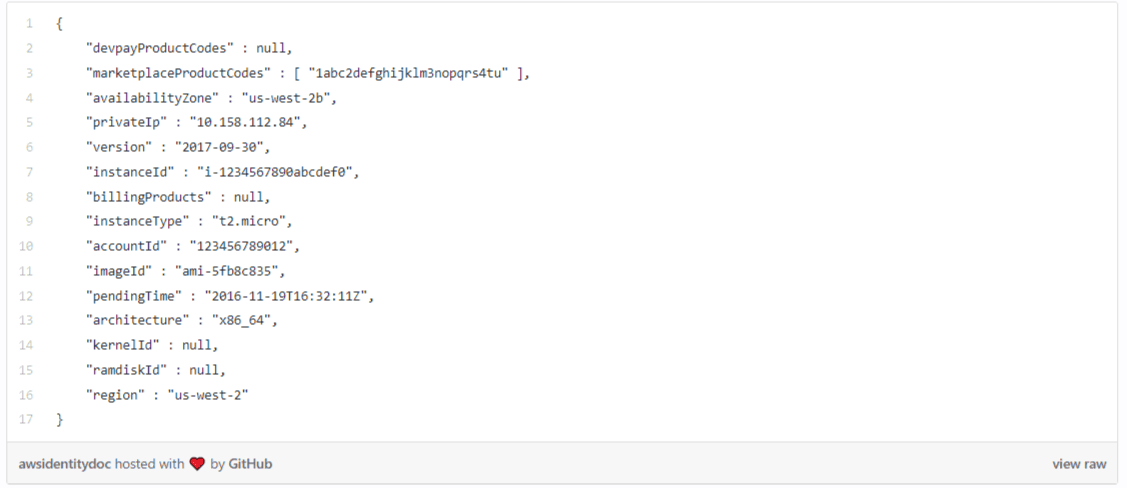
While the instanceId may denote the unique identity of the application instance that was launched, it needs to be chained up to some well-known name (myserver.acmecorp.com) that other applications will use to communicate to this particular instance. As a result, even this AWS bootstrap identity document is insufficient, but can be used to issue another identity that can be used by the applications to communicate with another application.
As stated earlier, it was critical for us to deliver an identity that allows applications to communicate and share information across cloud providers and/or edge locations (Figure 2). This meant that we had to build a system for both identity bootstrapping and root-of-trust that works across all of these environments.

Since we use Kubernetes to manage and orchestrate applications (both microservices and VMs), this meant that the bootstrapping of a unique identity for every pod launched had to be hooked into the Pod creation process of Kubernetes. Figure 3 shows how we hook into the pod creation process using the K8s webhook mechanism. This webhook, called Voucher, injects a security sidecar, called Wingman, into all Pods created in the cluster and also provides necessary cryptographically signed information that can be used as the root-of-trust. This webhook provides a short-lived signed token that is used by Wingman to request an X.509 certificate from Identity Authority in Volterra’s SaaS backend.
The Identity Authority enforces the rules of minting the identity in a way that minimizes the “blast radius” in case one of the K8s clusters is compromised. Many other solutions that rely on a common root CA or federation of K8s clusters cannot limit the blast radius, which was a major input into our design decision.

For a given Pod in K8s, the attributes can change after the creation of the Pod — For example, a Pod can be attached to a new service after its creation. This meant that identity certificates had to be updated with the new service. Wingman continuously watches the Voucher that tracks the K8s API server for any such updates.
This mechanism delivers a unique and universal global identity to every application instance running across our platform, irrespective of whether it is our own workload or customer workload. This unique identity and sidecar (Wingman) are then used to secure all communication, access and keys/secrets across a distributed system.
Authentication and Authorization
Having a unique identity per Pod is a great start as it eases the task of implementing mutual authentication among communicating services. Our underlying infrastructure is made up of many different services that run on different protocols such as gRPC, REST, IPSec, BGP, etc. Since the early days, the team set a goal of achieving mutual authentication and communication security (encrypted channel) for all communicating parties regardless of the protocol. This also meant that we couldn’t tie our identity to a solution (e.g. Istio) that limits itself to a particular set of protocols (e.g. HTTP/TCP vs. IP-based).
Since our platform also allows customers to run workloads of their choice, we expect that these workloads could run a variety of protocols and the platform should not limit their ability by providing an identity that is limited to a particular set of protocols. Instead, the authentication is decoupled from the identity (via Wingman) and this makes hooking into various service mesh technologies possible. Our service mesh sidecar/dataplane (covered in a previous blog) uses this identity to deliver mTLS for customer workloads.
Since many of our own infrastructure services were written using Volterra Golang Service Framework (to be discussed in a future blog), we decided to build the logic of consuming identity (from Wingman) directly into the framework. This has helped our developers secure their service to service communications out of the box without relying on service mesh sidecar for mTLS.
The next logical step after achieving a mutually authenticated secure channel is Authorization — a process for the receiver of the request (server) to determine whether or not to allow the request coming from the identified caller (client). The reasons to not allow the request could be many — quota limitations, permissions, etc. Since these reasons and their thresholds are dynamically changing, a hard-coded set of rules (policy) for authorization was a non-starter for our platform.
We decided to use Open Policy Agent’s engine as a starting point and built a wrapper for authorization within Wingman sidecar. This wrapper code fetches the relevant policies dynamically and keeps them hot for fast evaluation. Similar to Authentication, decoupling the Authorization engine from identity (and Authentication) has allowed us to enforce authorization policies at multiple stages of request processing, including deep down in the business logic and not just immediately after authentication.
Since Wingman is inserted in all workloads, including the customer’s workloads, our platform provides an Authorization engine as a built-in feature. Even though Open Policy Agent (OPA) is built on a powerful language called Rego, we wanted to hide its complexity from our developers and customers. All policies on our platform can also be defined using a much easier to understand and intuitive policy structure that does not require the users (DevOps) to learn Rego and therefore avoid mistakes. Similar to authentication configuration, our Golang Service Framework was hooked into Wingman’s authorization engine by automatically calling Wingman for authorization and hiding the complexity of authorization from the developers.
Using a unique identity (issued using Wingman) for authentication and a programmable policy engine (within Wingman) for authorization, we are able to secure communication using mTLS and control every access using a robust and programmable policy.
Secrets Management without a Centralized Vault
Every day, engineers make inadvertent mistakes by storing keys and passwords in their code and it somehow makes its way to public code or artifact repositories. Managing secrets is hard and without an easy to use toolkit and a well defined process, developers are expected to follow the shortest path forward. As a result, from the very beginning of the company, our platform security (different from network and app security) team’s mission was to ensure that developers don’t have to ask questions like “Where do I store secrets — source code or artifacts or …?”
We evaluated two common approaches that were available to us for secrets management when we started building our platform, and both of them had certain shortcomings:
- Kubernetes Secrets — While we use Kubernetes and it comes with its secrets solution, it is not particularly useful for various reasons — secrets are not encrypted-at-rest, policy constructs are not comprehensive, and it does not solve multi-cluster scenarios.
- Centralized Vault (e.g. Hashicorp or Cyberark Vault) — Another approach could have been to use a Vault where the secrets are stored centrally and are handed out to authorized requestors. The secrets are protected by a single encryption key that is used for encrypted storage of Vault. The problem with this approach, however, is that the secret management system has access to clear secrets (even if they are stored in encrypted form) and any compromise of the system could reveal all the secrets.
In our case, being a SaaS service, we had to come up with a more robust method to secure our customers’ secrets, as any compromise should not reveal their secrets.
As a result, we decided to implement a new technique that we call Volterra Blindfold (trademark), which works in conjunction with our security sidecar, Wingman, as shown in Figure 4. This approach allows the owner of the secret to lock (encrypt) the secret in such a way that the secret is never revealed in clear to any undesired party (including the decryption server). The secret is not even stored in a central decryption server and this design, in some respects, dramatically simplifies the server design.

We provide users with a blindfold tool that can be used in a completely offline setting to encrypt the secret (S) which can then be distributed — for example, the secret can itself be stored with the workload and uploaded to the registry. Once this is achieved, the following steps need to happen:
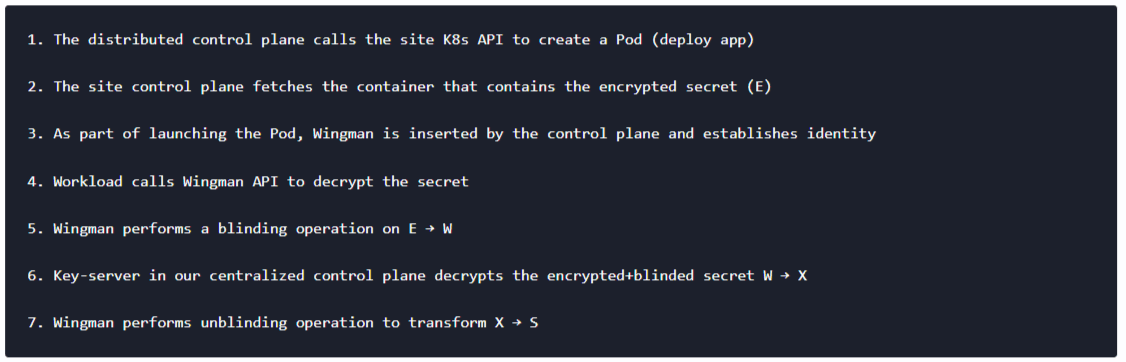
This ensures that the centralized control plane never gets access to the secret in clear (S) and also the secret is only available in the runtime memory of the Pod for the duration of the access. In addition, access policy can be applied to define who gets access to a secret. The policy can be defined based on the identity attributes such as application name, location, compliance level etc. This way any complex subset of workloads can be carved out and precise access control can be achieved. The policy is cryptographically woven into the encryption, blinding, decryption and unblinding process — it is computationally infeasible to defeat the intent of the policy.
Using our unique Blindfold technique to lock each secret and Wingman to unseal each secret based on policy and unforgeable identity, we are able to overcome the problems with existing solutions and deliver secrets management in a distributed environment without ever worrying about compromise of the central goldmine.
Key Management for Distributed Systems
Although secrets and key management may sound like two different names for the same problem, there are subtle (but important in practice) differences between the two depending on who you ask and how one may want to implement the solutions.
Secret refers to any information that is supposed to be secret and not available to unauthorized parties. In a way, cryptographic keys are a specific case of secrets. Key Management, on the other hand, generally refers to a system that securely stores sensitive cryptographic key material and controls the use of the material. In some cases, the key management system may hand out raw bytes of the key to authorized parties and therefore may get confused with a secret management system. In most cases however, the key management system does not actually hand out raw bytes of the key material and instead performs operations for authorized requestors and sends only the output of the operation. Many key management systems are also backed by hardware storage (eg. HSM) for the key material such that the key is never exposed in clear to the software.
In distributed environments, even for a single cloud provider, the problem of managing, syncing and rotating cryptographic keys is very challenging and current solutions are error-prone, inefficient and even insecure. For example, if one uses 3 AWS regions today and wants to use the same crypto key in all 3 regions, they will have to manually sync and rotate the keys. The problem becomes even worse when the environment spans across multiple cloud providers ( public and/or private). Even after all this is said and done, the application owners still have to write complex code to make use of these KMS capabilities.
Our platform hides all the complexities of key management from the application by making Wingman sidecar do all the heavy-lifting and provide simple interface(s) to the application to make the key management requests including encryption, decryption, HMAC, HMAC verify, digital signature, signature verification, fetch key (when allowed) etc. This makes key management not at all daunting for our own infrastructure services as well as customer workloads.
The following diagram (Figure 5) shows how Volterra’s KMS works across environments and helps workloads to offload their key management and crypto operations to the Wingman sidecar. Depending on the configuration, Wingman is able to cache keys and refresh the cache without the application even knowing it. The enabling factor here is the universal and unforgeable identity that we introduced earlier. Since each Pod, regardless of its location, gets a globally unique identity, it is easy for the Volterra KMS system to apply access policies to crypto keys and specific operations like encryption, decryption, HMAC, HMAC verify, digital signature, and signature verification in a very accurate manner.

Since all the keys are managed via Volterra’s SaaS backend, the workloads running in heterogeneous environments do not have to deal with key sync, rotation, revocation etc — they just have to know simple Wingman APIs for all their data-at-rest security needs.
Gains Delivered by Our Platform Security Solution
Using multi-layer platform security, we have been able to deliver a comprehensive solution to three critical problems in an entirely new way! Our system is able to securely bootstrap a universal identity that does not suffer from the problem of “turtles all the way down”, manage secrets that can be stored and distributed without ever worrying about the goldmine problem, and provide key management to ease security of data-at-rest in a distributed environment. This has led to the following gains for our internal teams as well as our customers:
- Security and Compliance — unforgeable and universal identity, Blindfold, and security sidecar (Wingman) that is fully integrated and automatically managed by the platform to secure all communication, authorize every access, and manage keys/secrets across a distributed system. Using these advances, we are able to deliver a more robust security solution that has eased our and our customers’ ability to meet compliance.
- Productivity Improvements — using a security solution that is integrated in our DevOps process and service framework, it is easy for developers and DevOps teams to focus on their deliverables without worrying about key aspects of application and data security.
- Continuous Evolution — the evolving security landscape and new technologies lead to continuous evolution of Blindfold, Wingman and our Golang Service Framework. As a result, new capabilities get automatically rolled out by the platform without any changes to application logic.
To Be Continued…
This series of blogs will cover various aspects of what it took for us to build and operate our globally distributed SaaS service with many application clusters in public cloud, our private network PoPs and edge sites. Next up will be Application and Network Security…
We are seeking a few volunteer developers and solution architects to help us bring this capability to broader community as an Open Source Project, please reach out directly to asingla@volterra.io if there is interest to be part of something fun!
About the Author
Related Blog Posts

A new path to technical excellence for F5 partners
Introducing F5 Partner Foundations, a structured learning curriculum to build F5 partner engineer expertise with a clear pathway to specialization.

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.