
Perhaps the biggest impact on operations due to the abrupt migration of consumer and employee to digital experiences is availability. Certainly, a significant percentage of organizations struggled with remote access as workers moved from the office to the home. But only some workers wound up working from home while entire populations were suddenly reliant on digital equivalents of day to day life.
Consider findings from Nokia, who is reporting that "upstream traffic (select networks in the US) for the month of March 2020" saw a "30% increase in the upstream traffic over their pre-pandemic levels." Or this data showing a 72% increase in transactions (and 29% increase in page views) for the second week of April.
Demand for digital experiences is up. And there’s very little more frustrating to a user than an app or website failing to load. To be honest, there's very little more frustrating to an operator than an app or website failing to load.
Achieving high availability is not just a matter of inserting a load balancer into the data path. That's part of the equation, but it's just one of the steps needed to ensure an app or website stays available.
The first thing you need to do is answer two not-so-simple questions:
- How do you distribute traffic between servers for high availability?
- What level of health checking is required to properly validate a server's availability?
At first glance, these appear to be simpler than they really are. That's because to answer them you need to know a lot about the app and its infrastructure.
Let's get started, shall we?
How do you distribute traffic between servers for high availability?
This question is really digging at the right load balancing algorithm to use, as algorithms are what determine how traffic (requests) are distributed across resources (servers). The answer to that depends on many things but starts with the app architecture and usage patterns.
You see, if you're trying to make a traditional app (monolith, client-server, three-tier web) highly available, you have to understand usage patterns from an entirely different perspective.
This is because one back-end "server" is responsible for executing all business logic. Trying to login? Ordering a product? Browsing the catalog? All the same "server." You might think you can just use a simple algorithm like round-robin to distribute traffic then. Au contraire, my friend. Each business function has different compute, memory, network, and data requirements. That means each business function puts a different load on the "server." A single "server" instance can quickly become overwhelmed simply by directing too many resource-heavy requests to it.
The best way to optimize distribution of requests to ensure availability for traditional apps is to use a least connections-based algorithm. This will keep load distributed across instances of "servers" based on the number of connections currently open. The reason this works is because resource-heavy requests will take longer to process, thus keeping connections active. By directing requests to "servers" with fewer connections, you're more likely to keep all of them available.
For modern (microservices-based) apps, this question is more easily answered. That's because a modern app is already decomposed into business functions that individually scale. It's still a good idea to use a least connections-based algorithm because some requests for the same function may consume more resources than another, but traffic is naturally balanced in a modern app architecture so just about any algorithm will serve to keep all the "servers" available.
The interesting (to me, anyway) thing about availability is that knowing how to distribute requests is only half the battle. The other is not, sadly, red and blue lasers, but relies on visibility into the health status of the application.
What level of health checking is required to properly validate a server's availability?
Here's where my dissertation on observability* should be inserted but, for the sake of brevity and your sanity, I'll just summarize thusly:
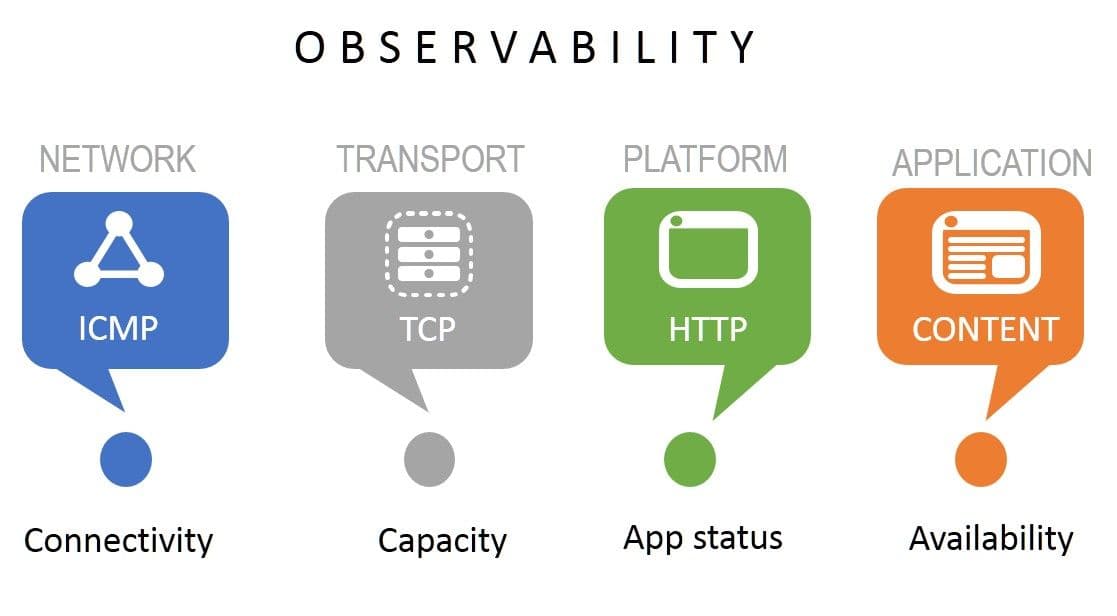
If you are using anything other than "application availability" to determine the status of an app, you are putting high availability in jeopardy. That's because none of the other observable measures tell you anything about the app. While you need network and transport and platform availability, until you're assured of the app's readiness to receive requests, you're asking for trouble if you send it traffic.
All four components of observability are important. If you lose network connectivity then the rest really doesn't matter, after all. Therefore, you need to keep an eye on all four measures, which means checking them all. It doesn't matter what the app architecture is. All apps are dependent on the network, transport, and platform layers. Where the architecture makes a difference is at the app layer because the architecture may constrain the way in which you determine the app is working or not.
You should always ask for way to "health check" the app during development. Whether via an API or HTTP request, the existence of a dedicated "health check" affords developers and ops an easy way to provide verification that the app is working correctly. This can include functionality that verifies connectivity to external resources like data or partner APIs. Because failure of any of these components can cause the app to appear unavailable or unresponsive to the consumer, it's important to verify availability of all required components.
High Availability is Harder than it Seems
Often, marketing literature would have you believe that high availability is as simple as cloning a server and shoving a load balancer in front of it. But the reality is that there are serious considerations, measurements, and preparation necessary to ensure that an app is highly available. It's not just a matter of making sure instances are available; it's a matter of making sure all their dependent apps are available and distributing requests in a way that doesn't overwhelm any given instance.
The upside to all the extra work you put into ensuring apps are highly available is a positive customer experience and fewer late-night frantic calls about apps being down.
* I don't actually have a dissertation on observability. But if I did, this is where it would have been inserted.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.
F5 joins the Dell AI Ecosystem Program to help enterprises operationalize AI
F5 joins the Dell AI Ecosystem Program to help enterprises deploy production AI with greater performance, security, and control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.