
The sheer complexity of modern application delivery is nothing like it was a decade ago. We used to rely on static load balancing strategies that juggled predictable traffic flows among a handful of servers. Today, we’re dealing with dynamic multicloud environments, microservices that spin up or shut down on the fly, and user bases that can swell from a thousand to a million overnight. Traditional, rules-driven load balancing can’t always keep pace.
That’s where reinforcement learning (RL) comes in. By continuously observing its environment and making decisions that maximize overall performance, an RL agent has the potential to adapt to real-time changes better than any pre-programmed script. It’s the difference between following a recipe to the letter and cooking by intuition—one scales for known conditions, while the other dynamically evolves with the situation.
Thesis: As application infrastructures become increasingly complex, we must shift from static or heuristics-based load balancing toward adaptive, reinforcement learning–driven systems to maintain resilience, optimize performance, and future-proof our networks.
There’s no shortage of hype around AI, but RL is one area where both academic research and real-world pilots are starting to show tangible promise. We’re not talking about a distant “maybe”; RL techniques are already driving positive results in simulation environments and certain production settings.
Reinforcement learning 101: Why it makes sense
Before diving deeper, let’s clarify RL in simpler terms. Picture an agent—the “brain” of the system—responsible for gathering data, making decisions, and adapting its strategy as conditions change. This agent is placed in a dynamic environment (such as a multicloud system), where it receives a “reward” for successful outcomes—like lowering latency or increasing throughput. Over time, it refines its strategy to earn bigger rewards more often.
- Adaptive and continuous: Unlike a static algorithm that’s locked to a specific rule set, RL continues to learn from new traffic patterns.
- Scalable logic: RL frameworks can coordinate thousands of variables—such as CPU usage, memory consumption, or node availability—and optimize across them simultaneously.
- Robust to shocks: Sudden changes, like a spike in e-commerce traffic during the holiday season, can be self-corrected without waiting for a human to adjust thresholds.
Controversy: Is RL overkill?
Some engineers have dismissed RL as over-engineering. “Why fix what’s not broken?” is a common question. Well, at F5, we’ve seen new customer scenarios—such as globally distributed microservices or multi-tenant edge deployments—where static rules are not just suboptimal, but occasionally dangerous. A policy that was perfect last quarter might break spectacularly under new conditions. RL’s ability to adapt amidst uncertainty can be a lifesaver in these scenarios.
Inside F5: A peek at real-world experiments
Within F5, we’ve run small-scale RL experiments in simulation environments modeled after real client traffic. Here’s one example:
- The setup: We created a synthetic “shopathon” scenario—think major shopping events on different continents launching simultaneously. Traffic ramped up unpredictably, with memory-intensive queries spiking at odd hours.
- The RL agent: Deployed in a containerized environment, the RL agent adjusted which microservices to spin up based on usage patterns. It learned to route CPU-heavy tasks to nodes with specialized hardware while shifting less-intensive processes to cheaper cloud instances.
- The results: Compared to a classical round-robin approach with some auto-scaling, the RL-driven method cut average response times by 12-15%. Crucially, it also kept error rates more stable during extreme traffic surges.
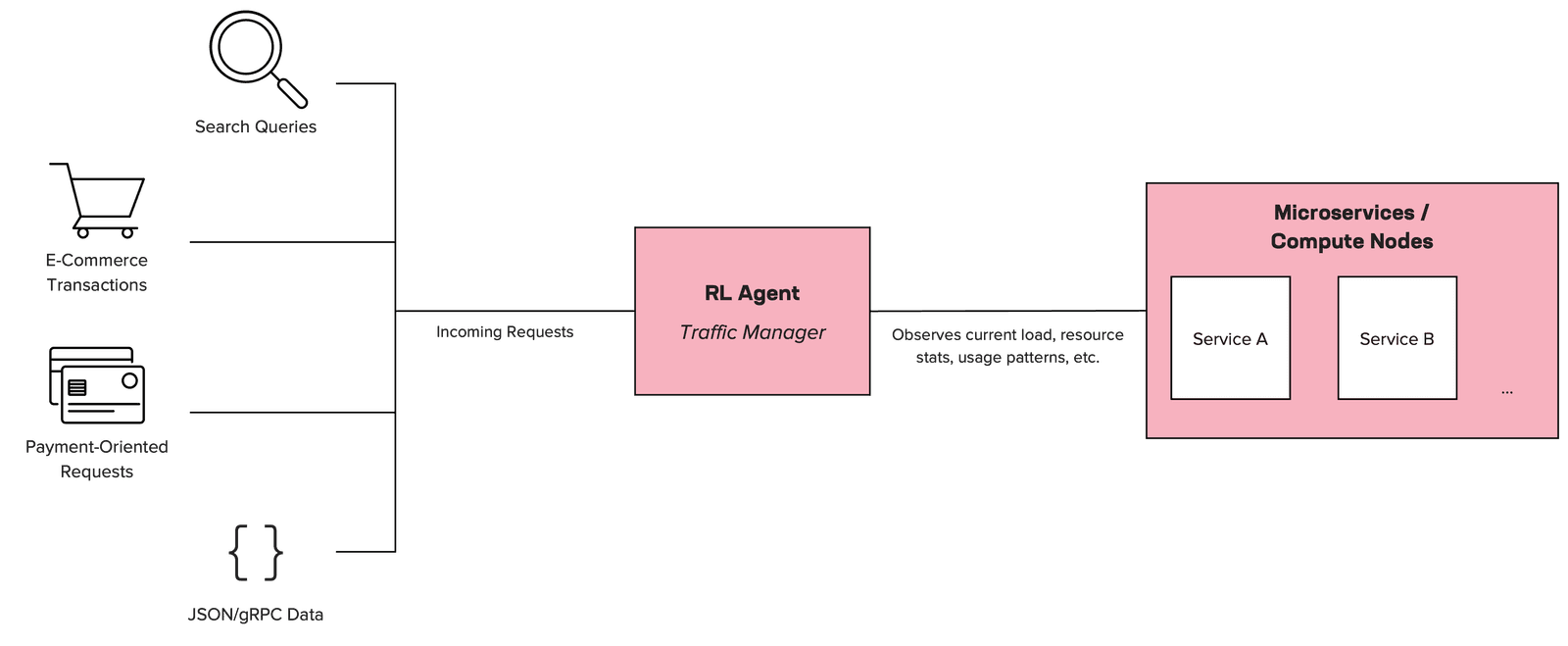
This conceptual diagram shows how the RL agent sits in place of (or alongside) a typical load balancer.
- Incoming requests: Users or client applications send requests.
- RL agent: Acts as the brain of traffic management. It watches real-time metrics (CPU usage, memory, error rates) and makes routing or scaling decisions.
- Microservices / Nodes: The RL agent spins up the appropriate microservices or routes traffic to specific nodes, based on learning outcomes.
This example shows the potential of RL to outperform traditional load balancing in many scenarios.
Potential pitfalls: Don’t drink the Kool-Aid just yet
Of course, RL is no silver bullet. Training times can be lengthy, and we had to invest in robust monitoring to ensure the RL agent wasn’t “gaming” the reward signal by making short-term decisions that hurt the big picture. Still, when it works, RL can outperform traditional heuristics by a clear margin. Here are a few other considerations:
1. Complexity vs. reliability
- Issue: RL introduces a new layer of complexity in systems that are already complex. An agent can get stuck in local optima or chase conflicting objectives (throughput vs. cost vs. latency) if not carefully managed.
- Mitigation: Hybrid approaches where RL handles high-level decisions while proven heuristics handle fail-safes.
2. Data quality and reward design
- Issue: RL hinges on reward signals. If your metrics are off or you incentivize the wrong behavior, the agent may exploit quirks in the environment that don’t translate to real business value.
- Mitigation: Invest in robust monitoring, metrics design, and thorough offline testing.
3. Ethical and regulatory concerns
- Issue: If an RL agent inadvertently discriminates against certain regions or usage patterns for cost efficiency, it might cross ethical or legal lines.
- Mitigation: Implementation teams must define permissible actions upfront and regularly audit ML-driven decisions.
Wider industry adoption trends in 2025
Beyond our internal experiments, the industry is buzzing about RL. Some highlights:
- Conference papers: Prestigious AI events—like NeurIPS ‘24—feature entire tracks on distributed reinforcement learning for network optimization.
- Cloud providers: Major cloud vendors now offer specialized toolkits for RL-based auto-scaling and traffic routing, bridging the gap between academic research and practical tools.
- Edge deployments: With emerging 5G and edge networks, there’s a pressing need to orchestrate resources across many small data centers. RL’s adaptability suits these fluid, geographically distributed architectures.
Still, enterprise adoption of RL for traffic management is in its early days. Many enterprises remain hesitant due to concerns over unpredictability or difficulties in explaining RL’s decisions to compliance teams or regulatory bodies. This underscores the importance of Explainable AI (XAI)—an active research area that aims to demystify how ML models arrive at decisions.
A vision for 2030
In my view, the next five years will see RL-based traffic management move from niche trials to more mainstream adoption among forward-looking enterprises. By 2030, I predict:
- Dynamic multicloud orchestration: RL will become the norm for orchestrating workloads across multiple public and private clouds, optimizing cost and performance far more efficiently than today’s manual tuning.
- Tighter integration with AI observability: Tools that seamlessly log, visualize, and interpret RL agent decisions will quell compliance concerns and simplify debugging.
- Collaborative agents: We’ll see multiple RL agents working together in a single environment, each with specialized tasks, akin to a team of experts—some handling resource allocation, others focusing on security or quality-of-service constraints.
While some skeptics question whether RL will deliver on these promises, I see RL as a powerful path forward for overcoming the inevitable challenges that increased complexity will bring. In my experience, momentum is already building, and I’m confident RL will continue to shape the future of traffic management as enterprises seek more adaptive, intelligent solutions.
Your next steps
So, is it time to toss out your tried-and-true load balancers? Not yet—but it’s absolutely time to start experimenting with RL-based approaches if you haven’t already. Test them in lower-risk environments, measure performance gains, and collaborate with cross-functional teams. Doing so will help you build a practical roadmap that balances RL’s promise with real-world constraints.
About the Author
Related Blog Posts

Multicloud chaos ends at the Equinix Edge with F5 Distributed Cloud CE
Simplify multicloud security with Equinix and F5 Distributed Cloud CE. Centralize your perimeter, reduce costs, and enhance performance with edge-driven WAAP.

At the Intersection of Operational Data and Generative AI
Help your organization understand the impact of generative AI (GenAI) on its operational data practices, and learn how to better align GenAI technology adoption timelines with existing budgets, practices, and cultures.
Using AI for IT Automation Security
Learn how artificial intelligence and machine learning aid in mitigating cybersecurity threats to your IT automation processes.
Most Exciting Tech Trend in 2022: IT/OT Convergence
The line between operation and digital systems continues to blur as homes and businesses increase their reliance on connected devices, accelerating the convergence of IT and OT. While this trend of integration brings excitement, it also presents its own challenges and concerns to be considered.
Adaptive Applications are Data-Driven
There's a big difference between knowing something's wrong and knowing what to do about it. Only after monitoring the right elements can we discern the health of a user experience, deriving from the analysis of those measurements the relationships and patterns that can be inferred. Ultimately, the automation that will give rise to truly adaptive applications is based on measurements and our understanding of them.
Inserting App Services into Shifting App Architectures
Application architectures have evolved several times since the early days of computing, and it is no longer optimal to rely solely on a single, known data path to insert application services. Furthermore, because many of the emerging data paths are not as suitable for a proxy-based platform, we must look to the other potential points of insertion possible to scale and secure modern applications.