
As is the case with every technology that comes to dominate data center conversations, DevOps is currently suffering from definition fatigue. Actually at this point I think it’s exhaustion, but the line between the two is difficult to determine. Suffice to say that DevOps is as far from having a ubiquitously accepted definition as cloud and SDN.
But DevOps is unique in that its composite concepts are also often confused and conflated. For example, CD can be taken to mean “continuous delivery” or “continuous deployment”. These two are not the same, and neither should they be confused or conflated. Puppet Labs did a great job of illustrating the difference in a blog post:
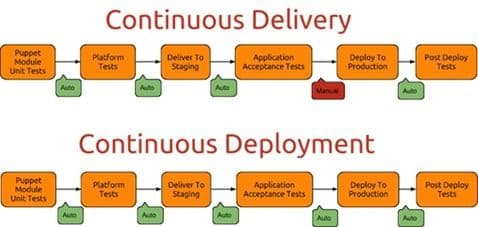
You’ll note the defining difference is whether or not the deployment to production is “manual” (continuous delivery) or “automated” (continuous deployment).
The thing is that there’s a significant amount of work in that little orange box labeled “deploy to production” that has to be automated. This is not just deploying the app and its dependences (databases, other services, infrastructure, etc…). It’s also about deploying all the network and application services required to deliver that application to the ultimate consumer. This is where application services come into play, and where application delivery (in the production sense, not the development sense) comes into the Continuous Deployment pipeline.
In order to automate the “deploy to production” step within Continuous Deployment pipeline, a lot of moving parts have to be provisioned, configured, and tested. That means everything from basic networking to security (like firewalls) to availability (load balancing) to performance (acceleration, caching, etc…) services. On average, organizations use 11 different application delivery services to realize their need for fast, secure, and available applications. Each one has to be deployed (provisioned and configured) and some are dependent on deployment of others.
Each one of those services (this is like that St. Ives riddle, for those of you playing along) has a varying number of characteristics that must be configured, options set to true or false, algorithms selected, routes established, etc…
In other words, making the switch from “manual” to “auto” isn’t anywhere as easy as it sounds.
What’s Holding up the Network?
A significant roadblock in automating these processes can be found in the differences between shared and per-app components. Infrastructure as Code is possible in the app infrastructure realm precisely because we can dedicate infrastructure (like a web server or load balancer) to an application. That means its configuration file is kind of like a micro-service: it’s localized and focused on providing services for one application.
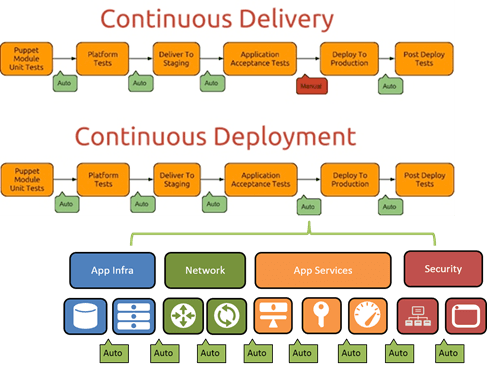
When we move to the world of networks and app services, this is not always the case. A router or switch, for example, is by purpose designed to provide connectivity and forwarding services for multiple applications. That means configuration files necessarily encompass multiple applications. While versioning might help here, it remains reality that configurations are very much tied to a device, not an app. The same is true for app services and security.
So while it’s well and good that we’re all moving toward a world where the API is the CLI, we also have to address the need to support a per-app (or app-centric, if you prefer) paradigm where configurations can be managed on a per-application basis.
That means moving toward either a microservices style network architecture in which services are deployed and configured on a per-app basis. This can take the form of either dedicated “devices” (virtual or hardware, form factor is irrelevant for purposes of this discussion) or app-specific configurations like templates.
Are we there yet?
We’re getting closer, with declarative models for provisioning and management that make use of APIs to deploy templates (that’s infrastructure as code) on a per-application basis but we’re not there yet. There remains a lot of work to be done in the realm of figuring out how to orchestrate the automation required to fully enable successful continuous deployment.
The network, infrastructure, app services, and security silos must be included if we’re going to make the move from “manual” to “auto” for that “deploy to production” step that’s critical in completing the move from continuous delivery to continuous deployment. And that means more work at the automation layer as well as the overarching orchestration needed to fully automate the processes that ultimately drive continuous deployment into production.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

A new path to technical excellence for F5 partners
Introducing F5 Partner Foundations, a structured learning curriculum to build F5 partner engineer expertise with a clear pathway to specialization.

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.