
As part of our SaaS-based Control-plane, we have built and run our own global backbone (AS35280), using multiple 100G and 400G links between our PoPs.
That way, we have complete control over end-to-end connectivity between our regional edges, but also this allows us to provide the same high-performance connectivity and low latency to our customers — across their private data centers, edge sites, public cloud VPCs(AWS, Azure, GCP), as well as SaaS providers.

The requirement
Our European footprint was already pretty good, with presence in Paris, London, Amsterdam, and Frankfurt, but existing and new customers required a new PoP in Lisbon, Portugal.
This was all agreed at the beginning of 2020, and deployment was planned for Q3 2020. Of course, this was pre-COVID-19 :)
With the crisis, we saw a lot more traffic (and also DDoS attacks, but more on that in a future blog post) on our backbone, and so did our customers.
They asked us to deploy before Q3, because they needed this PoP ASAP — more precisely, before the end of May. And since we at Volterra are nice guys, and also because we like challenges, we looked carefully at the time needed to meet the customer demand:
- We needed at least 2 weeks to deploy and test,
- And one week to validate
Knowing that we were early April, this looked fine and we decided to carry on and launch the project, even though that was really the worst possible time to do it, due to:
- Travel ban,
- No datacenter access,
- Global component shortage,
- Not to mention risks for health.
What is needed?
Deploying a new PoP is not only about routers, switches, and cables. You also need to:
- perform network engineering to chose the best location and providers for waves,
- make a deal/negotiate with the chosen data center (Equinix LS1 in that case),
- deal with IXP to secure peering ports,
- and of course ordering the relevant hardware/material (routers, switches, cable, firewalls, …)
How we did it
With the ongoing crisis, having the required hardware in time was impossible. So we decided to reuse some we had available, mostly from our lab. This was an acceptable trade-off (e.g. routers used will be Juniper QFX10K instead of the planned MX10K).
Staging, which we usually do obviously in a datacenter (because of power and rack space needed, but also… noise!) would have to be done at home because of the lockdown. Raphaël, our CTO of Infrastructure, had a big enough office room (including a 60-Amp contract, which can prove useful when you boot/power equipment who take up to 16 Amp!), so he would do the whole staging by himself, which would also avoid having other staff involved/having to get out.

Once everything had been configured and tested multiple times, we shipped to Lisbon:

Rack installation in Lisbon by Equinix remote-hands
Even though we were confident on the setup we did (and had remote access via OOB or our backbone anyway), still this was the first time that a new PoP would not be deployed by us directly, but by someone else 😅

We use the same rack design all around the world, and the goal was to be consistent and have the same setup for this new Lisbon PoP.
So we had to be extremely precise with the instructions we were giving to Equinix remote-hands so that they can mimic and just had to “follow the guide”.
Below is a part of the procedure we sent to Equinix - so that they can easily rack and connect everything.
There’s a lot of components to deal with — not only the hardware devices (routers, switches, firewalls, servers) but also the cabling, and more importantly, the switch and server ports to connect the cables to.
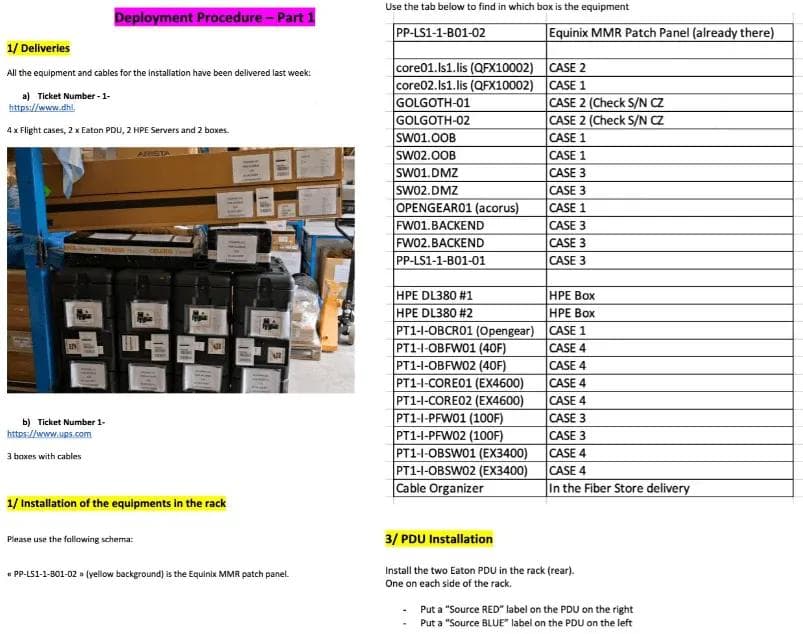
As you can see below, the procedure is as detailed as possible, bearing in mind that the Equinix technicians have lots of installation to do, so the more precise we are, the better it is!

Did that work?
Yes! Installation began on May 5th, with all the devices racked and powered, and no hardware failure — we’ve been lucky, or maybe thanks to our experience, shipment and packaging were done properly, or maybe both — but in any case, everything worked fine.
The day after, Equinix technicians took care of cabling (copper/fiber), and at 11:30 PM, we could ping our Lisbon PoP from Paris!
The installation was completed on May 7th, with the final tasks to carry, such as the configuration of PDUs, Cross-connect of the OOB ports, IXP ports check end-to-end. Even our switches/firewall configuration were fully functional, we didn’t have to ask Equinix for configuration changes.
The final installation looks like this:

As we are super demanding, we are not 100% satisfied e.g. the rear panel of the rack is not as clean as we would like it to be — but we’ll fix that once the Crisis settles down and we can travel again to Portugal.
“Post-Mortem” — what worked, why, and what can be improved
Even though we are extremely happy and proud that we managed to meet the challenge, we like to step back and reflect on what worked, but especially what can be improved.
What worked:
- Equinix: it is important to let a provider know when things are not going well, but it is even more important to do so when things went well and beyond — and that is the case here. From Sales and Senior Management to Datacenter technicians, the support and reactivity we received were just incredible — especially during those tough times — so really, kudos to Equinix!
Why did that work?
- Volterra was already mainly a distributed and remote-first company — especially, our French team, responsible for NetOps, is spread across France and is used to work remotely using collaborative tools.
- We had enough spare/lab hardware to use, which allowed us to be on time
- The procedure we’ve briefly explained above is the result of years of deployment and experience, with iterative improvements, and it paid off.
- Having a good relationship with our vendors is critical to us: again, when something goes wrong, we’ll jump on a call and won’t be shy to tell them, but on the other side, this allows them to improve, not only for us but for all their customers.
- Need for speed/price/quality: You have to have high expectations — this includes investment in resources BEFORE you need it!
What can be improved?
- We realized that only a handful of people (3 to 4) in the company could handle such a deployment — we need to find a way to scale
- Also, we want to improve how we’re doing the staging, to avoid having to do a full staging first
- Finally, such a deployment is not only a technical matter: Sales/Presales must be aware of how much time is needed for the whole project and individual steps — and not assume NetOps can solve anything and therefore throw projects without proper timing qualification.
We presented this deployment during the first remote RIPE meeting (RIPE 80), you can watch the recording here:
About the Author
Related Blog Posts

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

F5 joins the Dell AI Ecosystem Program to help enterprises operationalize AI
F5 joins the Dell AI Ecosystem Program to help enterprises deploy production AI with greater performance, security, and control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.