

Early this year, our team was asked to augment our existing security tools and software dev+test practices for PCI-DSS and SOC-2 compliance. One of the key areas we had to augment was vulnerability scanning for our K8s-based microservices and a couple of monolithic services. As a result, our DevOps team had to pick between a few commercial tools and open source solutions to implement vulnerability scanning for our software. All of these tools do very similar things: they scan dependencies (either project libraries or OS packages) and compare them with vulnerability databases (like NIST’s NVD and others).
Build vs. Buy?
There are a few open source tools that can be used to build your own vulnerability scanning solution, or you can use a commercial product that adds additional features over basic scanning that can make your life easier. Examples include:
- Nice dashboards for quick overview of vulnerabilities in your projects
- Notifications (email, Slack, etc.)
- Integration with Git repositories (GitHub, GitLab)
- Integration with other services (Docker registry, Kubernetes)
- Integration with project management (e.g. Jira)
- Automatic merge request creation to fix vulnerable dependencies
- Support for teams, projects and RBAC
Most commercial solutions augment public vulnerability databased with their own vulnerability database to eliminate false positives/negatives and give you more relevant results. That said, all of these commercial tools become really expensive as the number of developers increase. So you need to consider whether it’s “better” for you to buy or to build your own solution using existing open source tooling.
Initially, we decided that commercial tool would best suit our need given the time constraint we had. However, after spending 3-months deploying and testing an industry leading commercial product, we faced a many challenges — limited support for golang, it would pick incorrect dependencies and not exit gracefully, problems with containers built from scratch vs those build with some base image, etc. As a result, we decided to give up on it and switch to building our own tool using available open source technologies.
In this post, I am going to provide you a solid base to start with if you choose to go open source. In addition, at the end of the post is the link to our open source repo to get you going!
What to scan?
There are basically two things you want to scan for vulnerabilities:
- Your project’s code dependencies (yarn.lock, Gopkg.lock, etc.)
- OS dependencies (Debian packages, Alpine packages, etc.) in a Docker image
In the future, it’s possible to add more capabilities like license checking or static code analysis, but that is out of scope for this post.
When to scan?
First of all, you want to ensure that no new vulnerability is introduced by your code or Docker image change, so it’s a good idea to scan every merge request before it’s merged.
But you also need to scan periodically, as new vulnerabilities can appear over time. Also, severities might change — a low severity that you initially ignored may become critical over time as a new attack vector or exploit is found. While commercial tools remember the last scan and will notify you if a new vulnerability is found, in our open source solution, we simply repeat the scan on top of the project’s master branch.
Choosing tools
There are a lot of open source tools available but our pick was Trivy because it’s simple to use, under active development, and can scan multiple projects and OS types.
Trivy is a simple and comprehensive vulnerability scanner for containers and other artifacts. A software vulnerability is a glitch, flaw, or weakness present in the software or in an operating system. Trivy detects vulnerabilities of OS packages (Alpine, RHEL, CentOS, etc.) and application dependencies (Bundler, Composer, npm, yarn, etc.). Trivy is easy to use — just install the binary and you’re ready to scan! All you need to do for scanning is to specify a target such as an image name of the container.
It can be easily installed and executed locally against the built Docker image or project’s root. It also supports multiple outputs, including JSON and table output:

Unfortunately there are projects which Trivy cannot scan (e.g. Golang), so we had to rely on OWASP Dependency-Check as a lot of our code is in golang.
Dependency-Check is a Software Composition Analysis (SCA) tool that attempts to detect publicly disclosed vulnerabilities contained within a project’s dependencies. It does this by determining if there is a Common Platform Enumeration (CPE) identifier for a given dependency. If found, it will generate a report linking to the associated CVE entries.
It can generate html pages with report, JUnit and JSON output (and some others).
Reports and dashboards
Now we are getting closer to more interesting stuff 😊
As we are already use Elasticsearch + Kibana + Fluentd in our DevOps and SRE teams, it was a natural fit to use existing infrastructure to analyze JSON output of our security scans.
We only needed to find a way to send data from untrusted infrastructure (CI runners) to our secure Elasticsearch. For this purpose, we decided to have a message queue in the middle. Fluentd has in_sqs plugin to read messages from Amazon SQS and it’s also simple to use so final architecture looks like this:

Once data reaches Elasticsearch, it is simple to create a few dashboards with Kibana or use Discover to query vulnerabilities with all details as needed.


Addressing vulnerabilities
So now we have scans and some nice dashboard, what next? We cannot expect that developers will watch these dashboards on regular basis. Instead we decided to fail CI when an issue of high severity or above is found and has a fix available, that way responsibility is moved to developers and project owners.
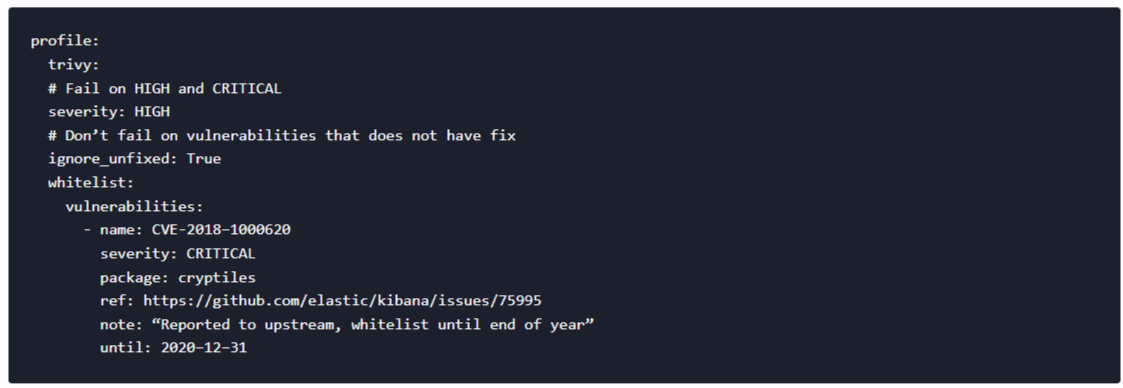
Naturally, we needed to have an option to whitelist some CVEs or to override this default behavior on a per-project basis. So we created a repository with security scanning profiles which are consumed by our scanning tool which wraps Trivy execution and handles its behavior and output.
Now any developer can submit a merge request against this repository and ask for an exception. Example profile for kibana project:
Future improvements
This implementation of security scanning is a solid base that can be extended beyond our initial use-cases. For example:
- Add Slack notifications, utilize security profiles to specify per-project channel and options
- Add integration with Gitlab Issues, Jira or any other ticketing system
- Create simple service or sidecar to execute scan of images deployed on Kubernetes cluster
Fork it and use it
You can find Dockerfile and tooling in our public Gitlab repository: https://gitlab.com/volterra.io/security-scanning
Thanks to Jakub Pavlík.
About the Authors
Related Blog Posts

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

F5 joins the Dell AI Ecosystem Program to help enterprises operationalize AI
F5 joins the Dell AI Ecosystem Program to help enterprises deploy production AI with greater performance, security, and control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.