
As DevOps approaches creep over the wall into network operations, it drags with it new terminology. These colloquialisms can be confusing to NetOps who’ve not encountered them before, and can befuddle IT executives who are being pressured to embrace the methodology.
Amongst them is the notion of infrastructure as code. In the world of developers, infrastructure is primarily the platforms and servers and container systems on which apps are deployed and in which they are scaled. Infrastructure is primarily compute.
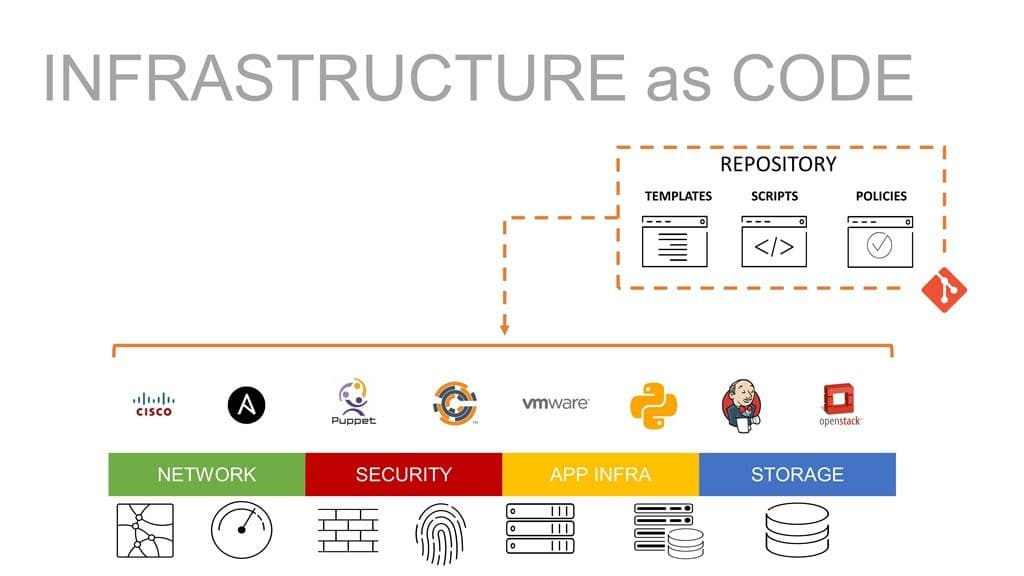
On the other side of the wall lives a wider, more robust, set of infrastructure that spans storage, security, and networking in addition to compute. There are four ops, after all, and all must be operating in sync to achieve continuous deployment and enable the kind of optimization IT and business leaders are looking for out of digital transformation. That means infrastructure as code includes a much broader range of systems, devices, and services in production than it does in development. An app deployment generally means infrastructure in each of the four ops will be touched in some way. That makes infrastructure as code in production a bit trickier, but also has a greater impact on efficiency and speed.
That’s because automation can eliminate the wait times between hand offs that are too often the source of inefficiencies in deployments, particularly when manual processes run afoul of vacations and sick days and lunch hours.
IT’S A SIMILE
Infrastructure as code is a simile; which means we don’t actually (at least not now) want to turn our network and application services systems into code that we build and then deploy. That’d be craziness for most enterprise organizations and disrupt the stability and reliability of the corporate network. But we do want to take advantage of the benefits of a system that decouples configuration and profiles from the systems on which they are running.
That means separating out configurations, policies, and profiles from the hardware or software on which they are deployed.
It is this collection that is then considered “deployment artifacts” and can be treated just like code. That means they can be stored and managed in repositories, versioned, and reviewed. They can be pulled, cloned, and committed in the same way a developer pulls, clones, and commits code to and from a repository (like Github).
We also should include “automation artifacts”. These are the scripts and associated files describing automation tasks that go along with your automation toolkit of choice. If that’s Ansible, it’s playbooks. If it’s Chef, it’s a recipe. For Puppet, a manifest. Or it might just be a plain old Python script.
For BIG-IP and an increasing number of network-hosted systems, that also includes templates (iApp) that might further describe more complex or standardized configurations. Using a template can be advantageous here because it can support options and application services that might not yet be supported by the core toolset.
Along with the deployment artifacts, automation artifacts form the collection that we call “infrastructure as code.” It is assumed that you can provision a system and subsequently run an automation process against it to configure it as desired.
When combined with a per-application approach to network and application services, an infrastructure as code approach can dramatically mitigate the risk of frequent deployments. By isolating configurations and confining their impact to a single system, the impact of a deployment gone wrong is practically eliminated. That, in turn, encourages per-application schedules that better align with the needs of the business and demands of users.
For cloud-minded organizations, taking an infrastructure as code approach can reduce the friction involved in migrating from data center to cloud, or cloud to cloud. Because the configuration is decoupled from the system it can ostensibly be deployed on a similar system elsewhere.
There are a lot of good reasons to undertake the effort to move to an infrastructure as code approach, and very few good reasons not to. Infrastructure as code is one of the most advantageous ways to realize the agile network organizations need to succeed in a multi-cloud, app-driven digital economy.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

A new path to technical excellence for F5 partners
Introducing F5 Partner Foundations, a structured learning curriculum to build F5 partner engineer expertise with a clear pathway to specialization.

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.