
The infrastructure renaissance has a catch phrase: let servers serve and inferencing inference.
Back in the early days of technology, I spent years mired in testing and analyzing SSL accelerators. These little cards were designed to address a significant problem that arose from the explosive growth of digital business and commerce; namely that security functions using SSL consumed CPU cycles and were a significant source of performance problems. So, the industry—including F5—developed hardware to offload those functions and let servers serve.
Today we’re seeing the same issues arise with AI—specifically inferencing—and, unironically, we’re seeing the same kind of solutions arise; namely, specialized hardware that lets servers serve and inferencing inference.
Yeah, I’m not sure that’s grammatically correct but let’s go with it for now, shall we? Kthx.
As we’ve pointed out, AI applications are modern applications in their architectural construction. But at the heart of an AI application is inferencing, and that is where AI diverges from “normal” modern applications.
Inferencing in Action
We’ve seen how AI compute complexes are constructed out of banks of CPUs and GPUs. These compute resources have ratios and balances that must be maintained to keep the cluster working efficiently. Every time a CPU can’t keep up, a very expensive GPU sits idle.
You see, only part of an inferencing server’s processing is actually inferencing. A great deal of it is standard web processing of HTTP and API requests. It’s that part of the inferencing service that uses the CPU and often becomes overwhelmed. When that happens, the GPUs are used less and less as the server side of inferencing becomes bogged down trying to handle requests.
That’s probably why 15% of organizations report that less than 50% of their available and purchased GPUs are in use (State of AI Infrastructure at Scale 2024).
Part of the problem here is the use of CPU resources for what should be infrastructure work. Services like traffic management, security operations, and monitoring consume CPU resources, too, and contribute to the load on the overall system. That leads to a reduction in capacity and performance of inferencing servers and leads to less utilization of GPU resources.
Luckily, this infrastructure renaissance is all about conserving CPU resources for inferencing work by offloading infrastructure operations to a new processing unit: the DPU.
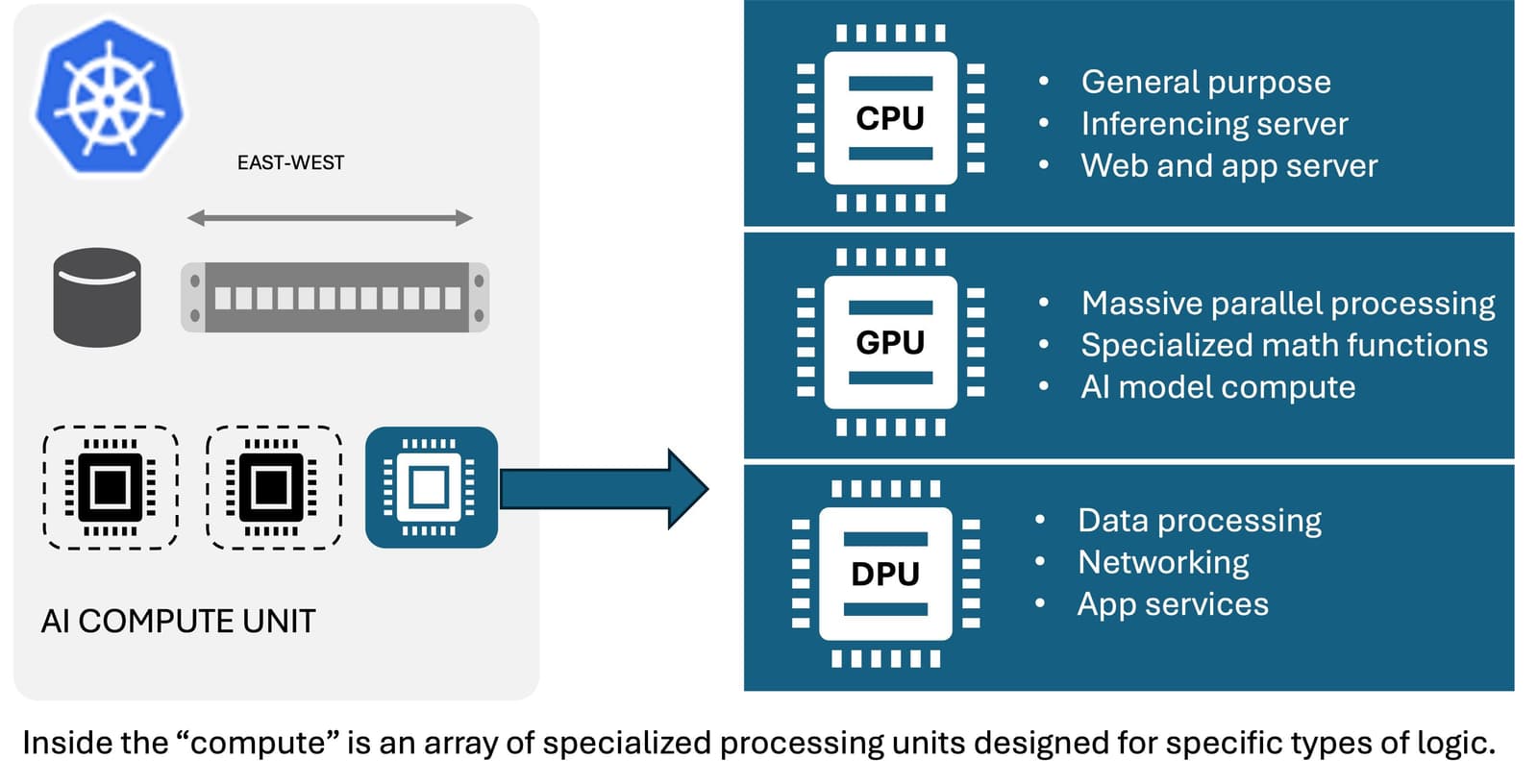
Now, the interesting thing about DPUs is that they actually support two different modes. In one, they can offload networking like RDMA over Infiniband or Ethernet. This helps immensely when building out an AI compute complex in which significant amounts of data are going to be flowing, such as training an AI model or scaling out inferencing for a large user base.
But DPUs can also be configured in ‘DPU’ mode. In Kubernetes this makes them show up as a separate node on which functions like application delivery and security can run. This effectively reserves CPU compute for inferencing services by ‘offloading’ the less predictable and more demanding infrastructure workloads to their own node in the cluster. This allows solutions like F5 BIG-IP Next SPK (Service Proxy for Kubernetes) to manage and secure inbound N-S AI requests via API and properly distribute them to the appropriate inferencing service within the AI compute complex.
This approach means organizations can leverage existing knowledge and investments in Kubernetes management of infrastructure because our solution is Kubernetes native. Core, cloud, edge—it doesn’t matter because the operation is at the cluster level and that is consistent across all environments.
It also separates responsibility for managing application delivery and security services, which enables network and security ops teams to handle the infrastructure independent of the AI workloads managed by dev and ML ops teams.
Lastly, leveraging the DPU for application delivery and security better supports the multi-tenancy needs of organizations. This is not just about isolating customer workloads, but model workloads. We know from our research that organizations are already using, on average, 2.9 different models. Being able to manage the use of each via a consistent solution will enable greater confidence in the security and privacy of the data being consumed and generated by each individual model.
This isn’t the first time F5 has worked with NVIDIA DPUs on AI-related use cases. But it is the first time we’ve worked together to develop a solution to help customers of all sizes build out scalable and secure AI compute complexes so they can safely and confidently harness the power of inferencing in any environment and optimize the use of GPU resources, so they aren’t sitting around idle.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

Multicloud chaos ends at the Equinix Edge with F5 Distributed Cloud CE
Simplify multicloud security with Equinix and F5 Distributed Cloud CE. Centralize your perimeter, reduce costs, and enhance performance with edge-driven WAAP.

At the Intersection of Operational Data and Generative AI
Help your organization understand the impact of generative AI (GenAI) on its operational data practices, and learn how to better align GenAI technology adoption timelines with existing budgets, practices, and cultures.
Using AI for IT Automation Security
Learn how artificial intelligence and machine learning aid in mitigating cybersecurity threats to your IT automation processes.
Most Exciting Tech Trend in 2022: IT/OT Convergence
The line between operation and digital systems continues to blur as homes and businesses increase their reliance on connected devices, accelerating the convergence of IT and OT. While this trend of integration brings excitement, it also presents its own challenges and concerns to be considered.
Adaptive Applications are Data-Driven
There's a big difference between knowing something's wrong and knowing what to do about it. Only after monitoring the right elements can we discern the health of a user experience, deriving from the analysis of those measurements the relationships and patterns that can be inferred. Ultimately, the automation that will give rise to truly adaptive applications is based on measurements and our understanding of them.
Inserting App Services into Shifting App Architectures
Application architectures have evolved several times since the early days of computing, and it is no longer optimal to rely solely on a single, known data path to insert application services. Furthermore, because many of the emerging data paths are not as suitable for a proxy-based platform, we must look to the other potential points of insertion possible to scale and secure modern applications.