
Based on the headlines, OpenAI is the only generative AI game in town. It is mentioned in every conversation about AI, even this one. But it isn’t the only service out there, nor is it the only model available.
In fact, adoption of generative AI for enterprise is not as homogenous as the headlines might lead you to think.
Our most recent research discovered that organizations are, on average, running with almost three different models. The reason behind that choice appears to be driven by use cases.

For example, it’s no surprise to see security ops as a use case gravitate toward open-source models, which can be trained privately without fear of exposing processes and sensitive corporate data. The same is true for content creation, which often requires sharing sensitive data with a model. Nor is it surprising to see workflow automation use cases looking to Microsoft’s hosted services, as many organizations are tightly coupled to Microsoft solutions both on-premises and in Azure.
No single model is going to fulfill all the technical and business requirements for the growing list of generative AI for enterprise use cases.
This leads to some challenges when it comes to app delivery and security and general operations, as different model choices imply different deployment patterns.
Emerging AI Deployment Patterns
There are three basic deployment patterns emerging. The core difference revolves around operational responsibility for scaling inferencing services. In all patterns the organization is responsibility for app delivery and security.
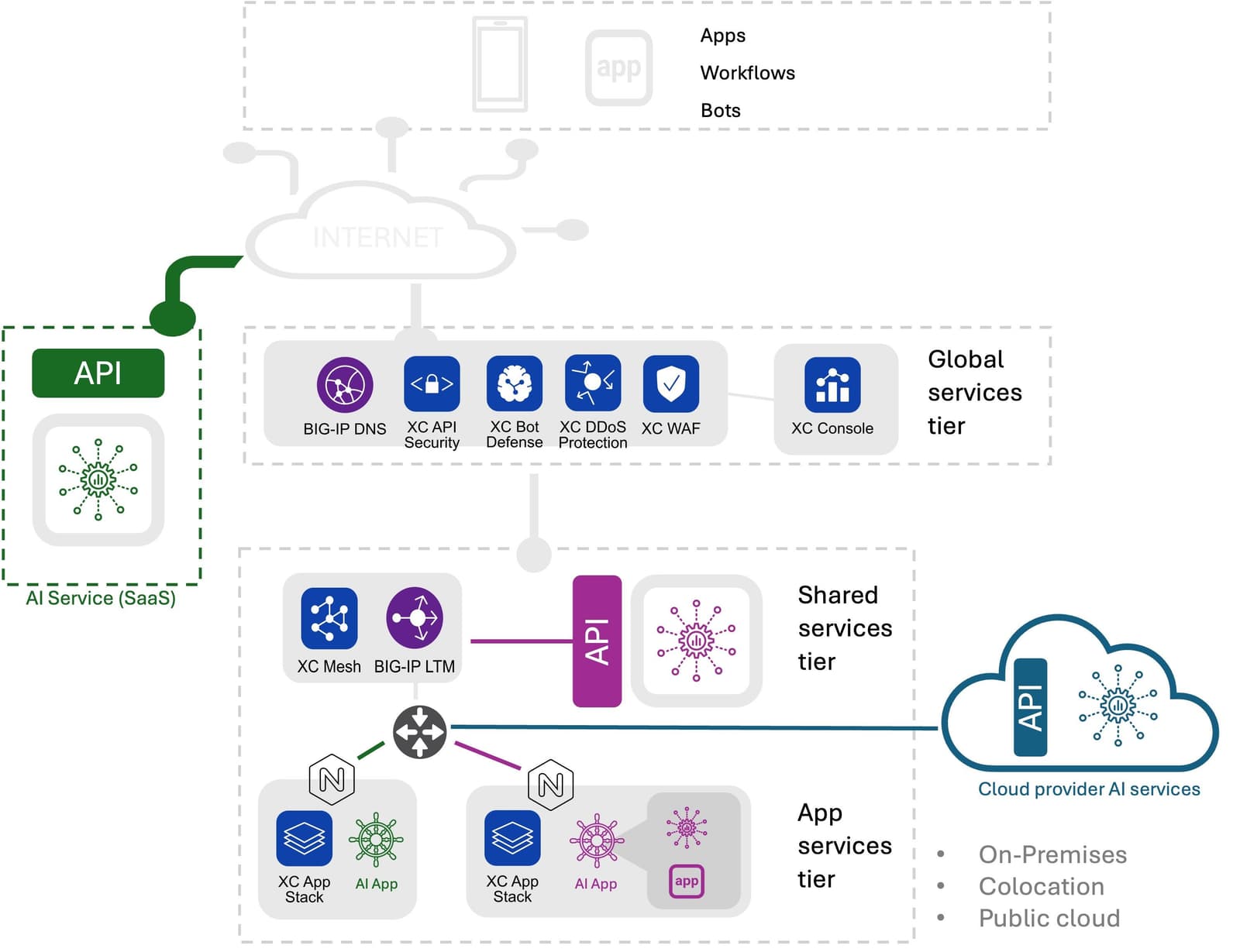
- SaaS Managed. In a SaaS managed deployment pattern, AI applications use APIs to access an AI managed service, a la OpenAI ChatGPT. Operational responsibility for scale lies with the provider.
- Cloud Managed. Cloud managed deployed patterns leverage cloud provider hosted AI services. These services are still accessed via an API but may be either private to the enterprise or shared. The AI apps themselves may also be in the public cloud or on-premises. When the service is private, the enterprise takes on the responsibility for scaling inferencing services, which can be a challenge as most organizations have little experience scaling large language models. When the service is shared, organizations defer responsibility to the cloud provider but must consider factors such as quotas and token-based costs as part of their operations.
- Self-Managed. Open-source models are most likely to be deployed in a self-managed pattern, both in the public cloud and on-premises. Models may be accessed via API or directly via an application. In this pattern, organizations take on full responsibility for scaling, securing, and monitoring the inference services.
(For a deeper dive into these patterns, you can check out this blog from Chris Hain)
There are numerous providers that will host open-source models to support a SaaS managed pattern and many cloud providers that also offer open-source as a service.
OpenAI models are not only available in a SaaS managed pattern via OpenAI, but as a cloud managed pattern via Microsoft. Mistral, a popular open-source model, can be deployed in all three patterns. This is why we see use case as the primary driver of model choice, given that enterprises can choose to mix and match, as it were, models and deployment patterns.
Organizations are already feeling the pressure with respect to the skills needed not only to train models but operate and secure them. Thus, matching models by use case makes the most sense for many organizations with limited operational expertise to spread around. Focusing resources on those use cases that cannot, for security or privacy reasons, be deployed in shared patterns will ultimately net the best results.
Beware Operational Myopia
But beware the danger of operational myopia, which can lead to silos within the organization. We’ve seen that happen with cloud computing and no doubt we will see it again with generative AI for enterprise. But being aware of the danger of isolating operations and security by model, one hopes that organizations might avoid the complexity and risk that incurs and strategically choose models and deployment patterns that make the most of operational resources, capabilities, and budgets.
These are early days, and by the time you read this there will no doubt be new providers and new models with new capabilities. But the deployment patterns will remain largely the same, which allows for more strategic planning with respect to operations—from budgets to staffing to the app services you’ll need to secure and scale whatever models you might choose.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

Multicloud chaos ends at the Equinix Edge with F5 Distributed Cloud CE
Simplify multicloud security with Equinix and F5 Distributed Cloud CE. Centralize your perimeter, reduce costs, and enhance performance with edge-driven WAAP.

At the Intersection of Operational Data and Generative AI
Help your organization understand the impact of generative AI (GenAI) on its operational data practices, and learn how to better align GenAI technology adoption timelines with existing budgets, practices, and cultures.
Using AI for IT Automation Security
Learn how artificial intelligence and machine learning aid in mitigating cybersecurity threats to your IT automation processes.
Most Exciting Tech Trend in 2022: IT/OT Convergence
The line between operation and digital systems continues to blur as homes and businesses increase their reliance on connected devices, accelerating the convergence of IT and OT. While this trend of integration brings excitement, it also presents its own challenges and concerns to be considered.
Adaptive Applications are Data-Driven
There's a big difference between knowing something's wrong and knowing what to do about it. Only after monitoring the right elements can we discern the health of a user experience, deriving from the analysis of those measurements the relationships and patterns that can be inferred. Ultimately, the automation that will give rise to truly adaptive applications is based on measurements and our understanding of them.
Inserting App Services into Shifting App Architectures
Application architectures have evolved several times since the early days of computing, and it is no longer optimal to rely solely on a single, known data path to insert application services. Furthermore, because many of the emerging data paths are not as suitable for a proxy-based platform, we must look to the other potential points of insertion possible to scale and secure modern applications.