En el mundo de los contenedores, la configuración declarativa es clave

La transformación digital en el interior es fundamental para posibilitar la transformación digital en el exterior. Uno de los componentes fundamentales de la transformación digital interna es la automatización, que depende en gran medida del plano de control . El plano de control es donde ocurre la automatización. En los viejos tiempos de la informática lo llamábamos “red de administración” y utilizábamos protocolos como SNMP para proporcionar monitoreo, configuración y control.
Hoy en día, la red de gestión todavía existe, al menos en teoría, como el medio a través del cual realizamos las mismas tareas a través del plano de control. El plano de control es un territorio desordenado de API, nodos maestros e incluso colas de mensajes que permiten que los componentes individuales de un sistema distribuido complejo se gestionen (casi) automáticamente. Está cada vez más orientado a los eventos, lo que exige un cambio de mentalidad respecto de los modelos centralizados de comando y control del pasado que se basaban principalmente en modelos imperativos de gestión. Es decir, un sistema central instruye a los componentes implícitamente con llamadas API específicas que provocan que se produzcan cambios. Los entornos actuales, por el contrario, se basan en modelos declarativos que distribuyen la responsabilidad de cambiar ellos mismos.
En ningún sistema es esto más evidente que en los entornos contenerizados. Desde afuera, tales sistemas parecen ser casi de naturaleza rebelde: los mensajes y eventos se publican y se disparan a voluntad, sin ningún jefe que ordene quién o qué debe reaccionar ante ellos. El plano de control ya no tiene tanto que ver con el control como con la distribución a lo largo de un plano que es más una malla que las arquitecturas de concentrador y radios de los sistemas de gestión arcaicos. En el mundo tradicional usamos API y protocolos para impulsar cambios en los componentes. En el mundo digital y contenerizado, utilizamos API para extraer la información necesaria para que un componente se modifique.
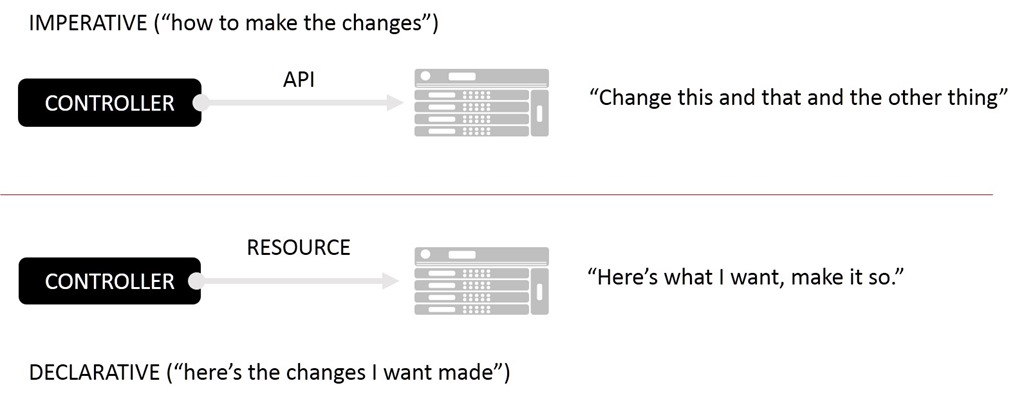
Este nuevo mundo es reactivo y evita el modelo imperativo (impulsado por API) del plano de control tradicional, basándose en cambio en un modelo declarativo más abierto para lograr el estado final automatizado deseado.
Esto no es sorprendente. A medida que hemos adoptado cada vez más un enfoque basado en software para todo (bajo el manto de DevOps, la nube y NFV), hemos tenido que lidiar simultáneamente con una escala operativa masiva. Un modelo de gestión imperativo, basado en centros de datos y radios, no puede escalarse de manera eficiente ya que la carga de todos los cambios recae sobre un controlador central capaz de comunicarse a través de una confusa variedad de API con un grupo casi ilimitado de componentes. Este es un modelo “push”, en el que el administrador (controlador) envía cambios a cada componente afectado. Se convierte en el cuello de botella que hace que todo el sistema funcione o fracase.
Es necesario un modelo impulsado por eventos que se base en la extracción de componentes para escalar y aliviar la carga del controlador, lo que a su vez requiere que los componentes que desean participar en este plano de control se sientan cómodos con un modelo de configuración declarativo. Porque en lugar de impulsar cambios a través de una API (imperativo), los contenedores nos impulsan a extraer cambios a través de configuraciones declarativas. La responsabilidad de suscribirse correctamente a los cambios y luego extraer la información adecuada necesaria para implementar ese cambio de inmediato recae en los proveedores de componentes (sean de código abierto o comerciales).
Si esto suena a infraestructura como código, debería serlo. Las configuraciones declarativas son básicamente código, o al menos artefactos de código. La automatización depende cada vez más de su premisa que disocia la configuración de su servicio. En un modelo utópico ideal, estas configuraciones declarativas son completamente agnósticas. Es decir, serían legibles por cualquier producto de cualquier proveedor (comercial o de código abierto) que admita ese servicio. Por ejemplo, una configuración declarativa que describe el servicio apropiado (servidor virtual) y las aplicaciones que comprometen su conjunto de recursos podría ser ingerida por el servicio X o el servicio Y e implementada.
Los archivos de recursos de Kubernetes son un buen ejemplo de un modelo de configuración declarativo en el que se describe lo que se desea, pero en ninguna parte se prescribe cómo . Esto es marcadamente diferente de los sistemas que dependen de API de infraestructura que requieren que la implementación esté familiarizada, a veces íntimamente, con cómo lograr los resultados deseados.
El modelo declarativo permite también tratar la infraestructura como si fuera ganado. Si uno falla, es sencillo eliminarlo y lanzar una nueva instancia. Toda la configuración que necesita está en el archivo de recursos; no hay un botón que diga “guardar su trabajo o se perderá” porque no hay trabajo que perder. Esto es casi inmutable, y es definitivamente una infraestructura desechable y es una necesidad en sistemas que cambian minuto a minuto, si no segundo a segundo, para minimizar el impacto de las fallas.
A medida que avanzamos cada vez más hacia sistemas automatizados de escala y –¿me atrevo a afirmar?– de seguridad, necesitaremos adoptar modelos declarativos para la gestión de los innumerables dispositivos y servicios que componen la ruta de datos de la aplicación o correremos el riesgo de quedar sepultados bajo una avalancha de deuda operativa generada por los métodos manuales de integración y automatización.