
It should be no surprise that just as the emergence of cloud gave us cloud-native applications, edge is driving a set of edge-native applications.
These applications, however, will not reside solely at the edge. On the contrary, the accompanying convergence of IT (information technology) and OT (operational technology) is driving new architectural patterns that also take advantage of applications residing in the cloud and data center.
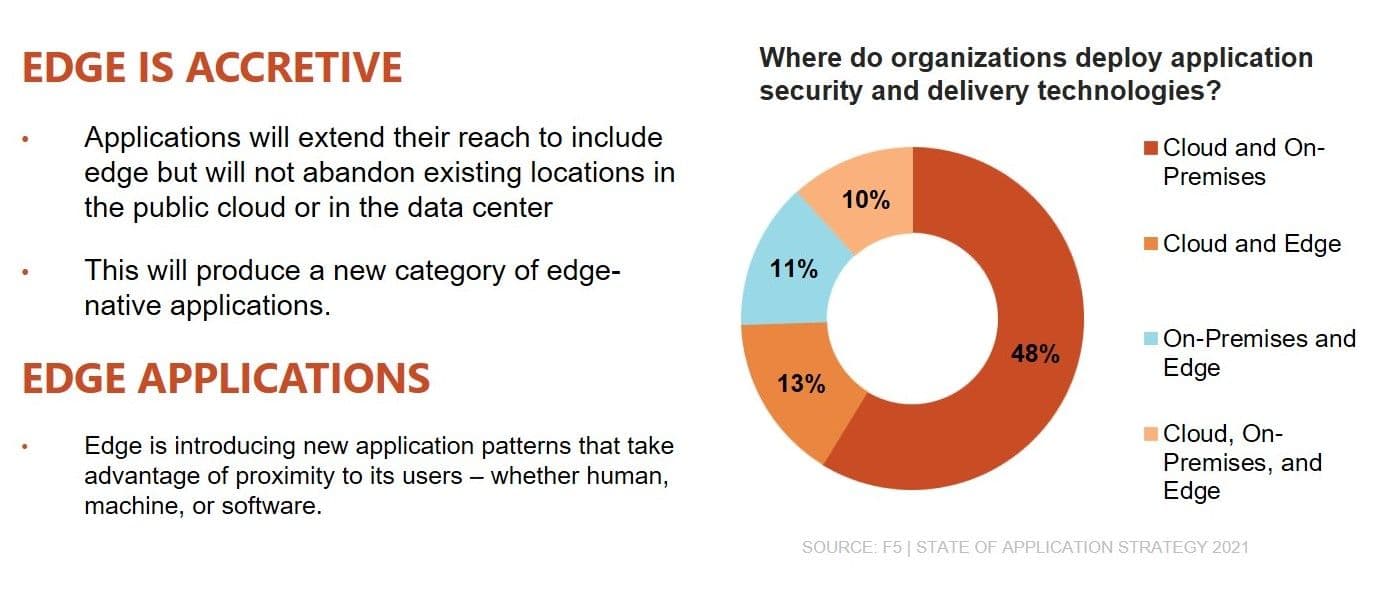
We can see leading indicators of this today when we consider where organizations currently deploy application security and delivery technologies. Less than half (41%) of organizations rely on just one location to host these technologies. The average is just over 2 – 2.11 to be exact. The most likely combination today is cloud and on-premises, but one in ten is already taking advantage of all three locations: data center, cloud, and edge.
This is particularly true for architectures built to support the, on average, ten connected things you can find in most consumer homes. Indeed, if we look at popular edge applications, we discover that they are a mix of cloud and edge, node and endpoint.
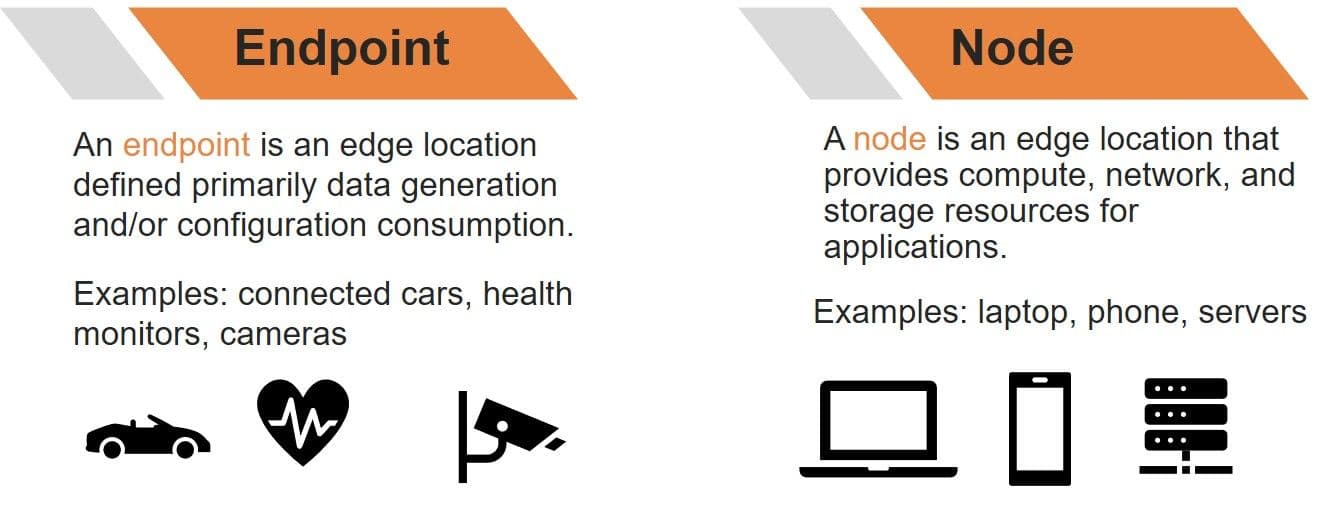
We make the distinction between an edge node and an edge endpoint based on the unique properties of each. This helps to delineate responsibility for specific functions that make up an "edge-native application" as each location has unique capabilities and constraints. For example, generally an edge endpoint does not support storage of significant volumes of data. Edge nodes might, and the data center/cloud certainly does. These capabilities and constraints help to shape edge-native applications in ways that use each location’s strengths to benefit both provider and consumer.
This is the fundamental reason that cloud and data centers play a significant role in edge-native applications.
Consider, for example, my Plex media server. I have a local server (edge node) in my house, with an app on my smart tv (edge endpoint). The edge node talks to the cloud-based Plex service for billing and account management, remote access, and for software updates. Other conversations and data exchanges take place between the two that describe usage and performance to help improve the overall application.
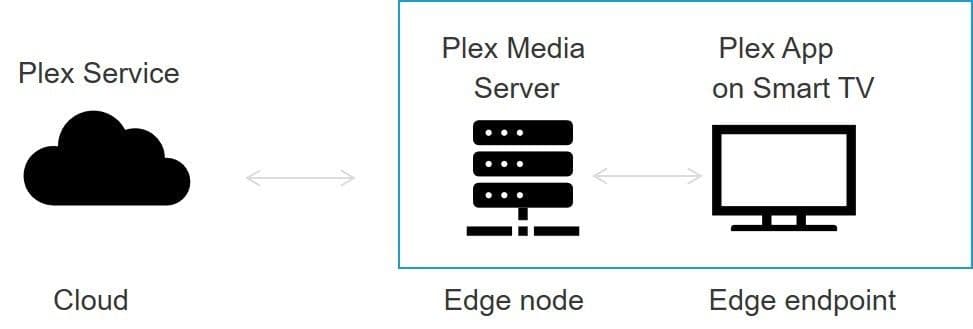
It would make zero sense for billing and account management functions to reside on the edge node, let alone the edge endpoint. Similarly, it wouldn’t be efficient (or very safe) to give the Plex service access to my local repository of digital content. Rather, that responsibility is left to the local media server running on the edge node.
In many ways, this pattern is no different than those produced by modernization efforts to provide modern interfaces for traditional (legacy, vintage, retro, mature, choose your euphemism for ‘before my time’) applications. Consider screen scraping text-based systems to provide web-based access at the turn of the century. Or the use of APIs to facilitate mobile banking, which relies on traditional transactional systems. Modernization efforts often produce application patterns that assign responsibility to systems and applications across data center, cloud, and edge boundaries.
These kinds of decisions are being made every day for connected things, sensors, and other edge applications. These decisions emerge as common, edge-native application patterns.
Nearly every one of them includes functions that reside in a cloud / data center.
Unlike the rush to declare data centers obsolete when cloud computing hit the scene, it is unlikely you will hear anyone declaring the same about cloud now that edge is emerging. On the contrary, cloud and data centers will continue to play an integral part of edge-native applications.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

Multicloud chaos ends at the Equinix Edge with F5 Distributed Cloud CE
Simplify multicloud security with Equinix and F5 Distributed Cloud CE. Centralize your perimeter, reduce costs, and enhance performance with edge-driven WAAP.

At the Intersection of Operational Data and Generative AI
Help your organization understand the impact of generative AI (GenAI) on its operational data practices, and learn how to better align GenAI technology adoption timelines with existing budgets, practices, and cultures.
Using AI for IT Automation Security
Learn how artificial intelligence and machine learning aid in mitigating cybersecurity threats to your IT automation processes.
Most Exciting Tech Trend in 2022: IT/OT Convergence
The line between operation and digital systems continues to blur as homes and businesses increase their reliance on connected devices, accelerating the convergence of IT and OT. While this trend of integration brings excitement, it also presents its own challenges and concerns to be considered.
Adaptive Applications are Data-Driven
There's a big difference between knowing something's wrong and knowing what to do about it. Only after monitoring the right elements can we discern the health of a user experience, deriving from the analysis of those measurements the relationships and patterns that can be inferred. Ultimately, the automation that will give rise to truly adaptive applications is based on measurements and our understanding of them.
Inserting App Services into Shifting App Architectures
Application architectures have evolved several times since the early days of computing, and it is no longer optimal to rely solely on a single, known data path to insert application services. Furthermore, because many of the emerging data paths are not as suitable for a proxy-based platform, we must look to the other potential points of insertion possible to scale and secure modern applications.