
Today I have a job for you. I want you – yeah, you right there – to deposit a check at the bank. You have to get in the car, drive to the bank, go inside, and do that thing with the teller, and then go back home.
Irritated? You should be, especially when you could just use your mobile banking app to do it without all the extra steps.
And that, my friends, is the difference between a workflow (a process) and an API.
There is a very real thing (I made up the name, but not the existence) called an API tax. That’s the time and technical debt incurred by executing complex processes using individual API calls. It’s like physically going to the bank instead of using your mobile app to make that deposit.
This tax grows as processes expand. If you have a lengthy process that requires ten or twenty different API calls, the code (scripts are code, too) gets increasingly complicated which impacts troubleshooting and makes it more difficult to change in the future. Ossifying processes through individual API calls is the opposite of agility. It’s fragility that freezes opportunity to improve efficiency through optimization.
Workflows are basically pre-defined processes for commonly executed tasks. Most business (and even operational) processes fall into this category. They’re the commands you use to login in, navigate to the right part of the system, change the access control on the port, and then commit the change. Every time you do this task, it is the same. It’s a commonly executed process that could easily be codified. There are many such processes in operations, and by wrapping them up as a workflow we can not only eliminate the API tax but improve the quality and sustainability of the scripts that invoke them.
That’s because using workflows instead of APIs means less complex code that’s easier to manage and easier to change. They are more agile and less fragile.
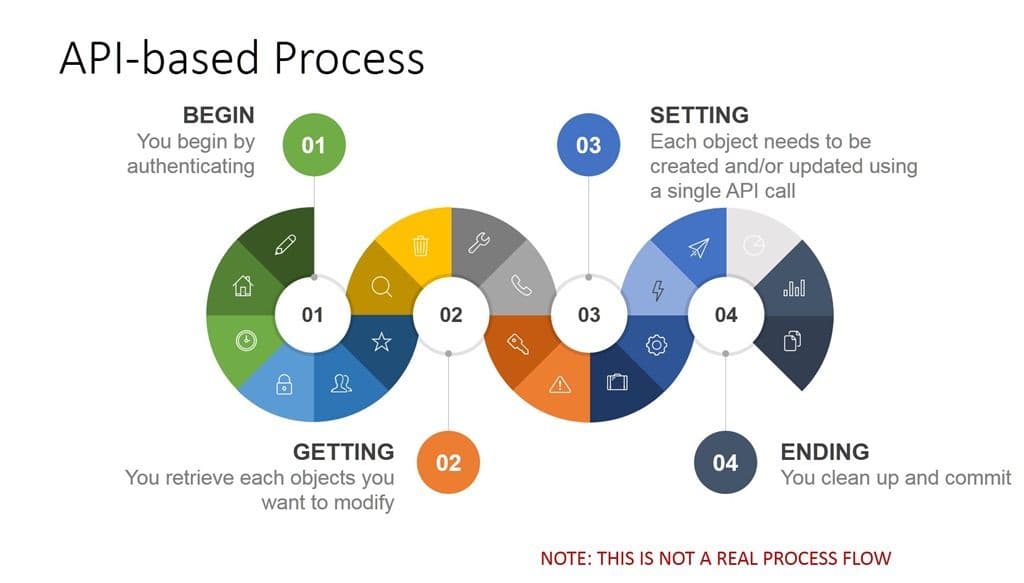
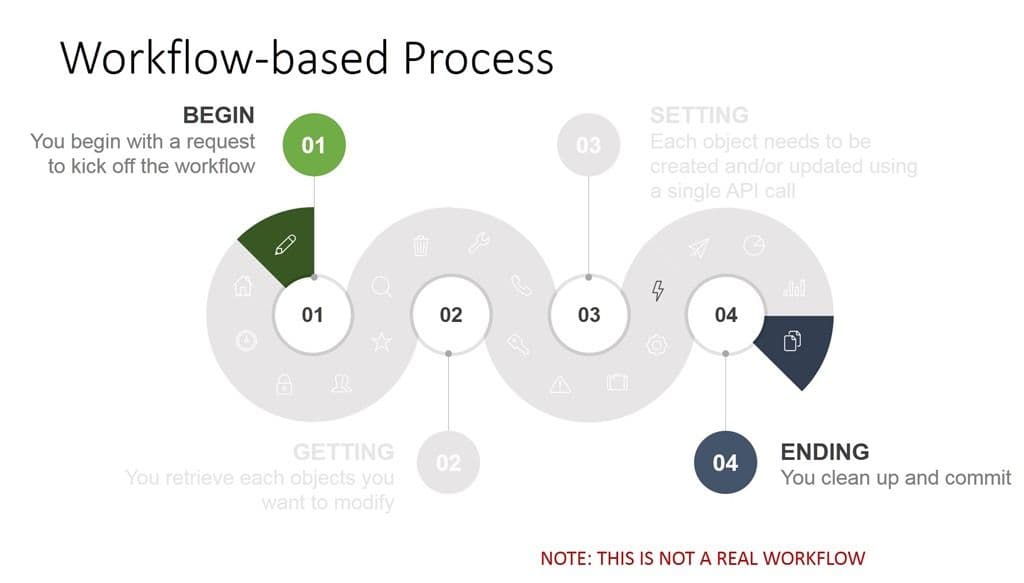
Consider this completely made up example. In the first, you have an API-based approach. Every single step in that process represents an API call. That means a script with nearly twenty different calls has to be developed, tested, and maintained over time. That’s technical debt. It’s tied to the API version of the system it’s working with at the time it was written. If one of those calls changes, the script has to change, too.
On the right you have a workflow-based approach. You can still initiate the process via an API call (likely preferable in many organizations) but the actual steps of the process are executed based on the parameters (variables) sent with the initial call. You might have to clean up and commit, but still you’ve reduced the code necessary to two or less interactions.
That’s not to say that using APIs and templates is a bad thing. It’s not. But it is often the case – particularly in the network world – that the use of APIs requires knowledge specific to the system and to networking in general. That makes it hard for DevOps or developers to work with the APIs. A workflow approach removes the assumption of knowledge or expertise, which means DevOps will be comfortable using them and NetOps retains job security.
In environments where automation is taking hold (and maybe even taking over), a workflow-based approach can offer substantive relief to NetOps by enabling DevOps with the ability to invoke tasks without requiring a ton domain-specific knowledge.
And hey, they can also avoid those pesky API taxes. And who doesn’t like avoiding taxes?
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

A new path to technical excellence for F5 partners
Introducing F5 Partner Foundations, a structured learning curriculum to build F5 partner engineer expertise with a clear pathway to specialization.

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.