
"Data is the new oil" or "Data is the grease of the digital economy." If you're like me, you've probably heard these phrases, or perhaps even the more business school-esque phrase "data exhaust monetization," to the point of being clichés. But like all good clichés, they are grounded in a fundamental truth, or in this case, in a complementary pair of truths. The first truth is the observation that the data byproduct of normal operational processes does contain latent value. The second, related but often unmentioned, truth is that the intensive process of distilling that latent value is a multi-step journey, though it does have natural stages of progression and maturity along the way.
Stepping back, the concept of harvesting the data from operations to reap business value is certainly not new. In fact, industries that are reliant on optimizing logistics—such as the grocery and delivery verticals—have long understood and embraced this concept. Similarly, the modern enterprise trend towards "digital transformation" is a generalization of this idea, typically applied first to internal business processes and workflows. Pointedly, there is an analogous evolution in the space of applications and application services. In this article, I would like to focus on how the evolution of applications and application services interacts and harmonizes with the larger megatrend of data value extraction, where that symbiosis is today, and finally, where it's headed in the near future.
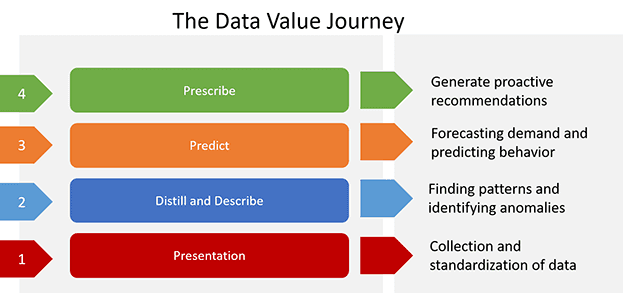
Step 1: Collect & Report
This journey starts with the collection of data. It’s helpful to think of data as the fuel for the system; if you don't have the fuel, you can't feed the engines that do the work. Superficially, it seems this is a fait accompli, given that application services solutions provide a plethora of events and statistics available—for security, reliability, performance management, and orchestration. But the data is often unstructured, the syntax is variable, and the semantics are often ad-hoc. Think of a simple, but common example: How is the concept of time represented in your data? Typically, there are many ways that something as conceptually simple as a timestamp is represented. This illustrates the need for a lingua franca, a common representation of basic "atoms" that describe events and statistics. In technology terms, we refer to this as “data ingestion,” built on a consistent data schema and leveraging adapters/translators as needed. This need was historically one of the key drivers that enabled the growth and value for SIEM vendors, who filled the need to provide this standardized vocabulary in order to provide a holistic view of security across a profusion of security point solutions. The ability to have, as an output, an integrated presentation of the data—an organized and holistic eyewitness report of what is happening now and what has happened in the past—is the phase of the journey where most of the industry is today. Within the application ecosystem today, this is primarily exemplified by SIEM and APM market verticals.
Step 2: Distill and Describe
The next step in the journey is making sense of the eyewitness reports: looking for commonalities, distilling the data into describable patterns, and identifying anomalies. Due to the volume of data involved, humans are typically assisted or augmented with computers in this activity. This assistance may take the form of using advanced, often unsupervised, statistical classification techniques sometimes augmented with human-guided data exploration and visualization.
One example from the anti-DoS domain is visualization of the geographic nature of incoming traffic, often used to identify malicious traffic that originates from a small set of countries. Another example is in the space of user behavior analysis ("UBA") tools that characterize the attributes of human behaviors versus bot behaviors. These solutions often use statistical analysis to assign probability to how likely a web interaction is from a human.
This phase of the journey—"Distill & Describe"—is an evolution from the previous "Collect & Report" step. It still relies, foundationally, on having a large, structured pool of data on which to apply the analysis. As mentioned above, this approach is the basis for some of the more recent (though narrowly focused) point solutions for application security.
Step 3: Infer & Predict
The third step of this journey is to go beyond the modest analysis of "Distill & Describe" onto making deeper analytical inferences resulting in predictions and forecasts about anticipated future observations. This advances the solution to more than purely reactive, by making intelligent extrapolations for expected future behavior. An example at the application infrastructure layer can be found the Application Performance Management (APM) space—namely, the identification of time-based behavior patterns, and the use of those patterns to forecast future resource requirements. Another example, using an application business logic use-case, is how travel sites use machine learning (“ML”) techniques to predict the supply and demand for specific routes on future dates. The technologies employed here most often are advanced analysis technologies, especially those based on time series and linear regressions techniques, building on the data patterns found in the prior step.
Step 4: Reason & Prescribe
The fourth and final step involves "closing the loop" to enact actionable adjustments and remediations to the whole system. Analysis from the prior two steps is translated into a set of proactive recommendations. At this point, the system becomes adaptive and robust against attacks and changes in its environment. For example, a conceptual application infrastructure utilizing the capability would have the ability to proactively create or destroy container workload instances, based on predicted demand. Or, in the context of application security, it might proactively filter botnet-generated traffic based on previously learned botnet behaviors. A notable example already exists today in the business logic space—in the form of dynamic pricing, again based on anticipated supply and demand.
The underlying technology is often rule-based, where the rules are used to translate predictions into actions. However, in the context of application infrastructure and application services, this approach is often coupled with more intent-based or declarative directives for configuration and orchestration.
Accelerating the Journey
This journey—from "Collect & Report" to "Distill & Describe" to "Infer & Predict" and finally to "Reason & Prescribe"—is a natural progression. Each incremental advance builds on the prior ones and unlocks a new and more incisive level of value. Today’s set of solutions to the challenges in the application infrastructure & services spaces are uneven in their maturity along this data value extraction progression, and typically not well integrated across the profusion of point solutions.
The precursor enabling step—the proverbial “fuel” for the data “engine”—is gaining visibility across a rich set of application services. This instrumentation, deployed along multiple points in the application delivery chain and coupled with the principles of consistent data semantics and federated data repositories, is one of the ways in which F5 is accelerating our journey into the future of application services. We intend to further hasten our pace to deliver value to our customers by simultaneously both widening the data funnel to allow better point-solution integrations, as well as expediting advanced development of the relevant technology building blocks.
In future articles, I hope to expand more on the data-shepherded architecture—both zooming in to dive deeper into the core technologies involved, as well as zooming out to examine the interactions of multiple data ecosystem across multiple sovereign data pipelines.
About the Author
Related Blog Posts

Multicloud chaos ends at the Equinix Edge with F5 Distributed Cloud CE
Simplify multicloud security with Equinix and F5 Distributed Cloud CE. Centralize your perimeter, reduce costs, and enhance performance with edge-driven WAAP.

At the Intersection of Operational Data and Generative AI
Help your organization understand the impact of generative AI (GenAI) on its operational data practices, and learn how to better align GenAI technology adoption timelines with existing budgets, practices, and cultures.
Using AI for IT Automation Security
Learn how artificial intelligence and machine learning aid in mitigating cybersecurity threats to your IT automation processes.
Most Exciting Tech Trend in 2022: IT/OT Convergence
The line between operation and digital systems continues to blur as homes and businesses increase their reliance on connected devices, accelerating the convergence of IT and OT. While this trend of integration brings excitement, it also presents its own challenges and concerns to be considered.
Adaptive Applications are Data-Driven
There's a big difference between knowing something's wrong and knowing what to do about it. Only after monitoring the right elements can we discern the health of a user experience, deriving from the analysis of those measurements the relationships and patterns that can be inferred. Ultimately, the automation that will give rise to truly adaptive applications is based on measurements and our understanding of them.
Inserting App Services into Shifting App Architectures
Application architectures have evolved several times since the early days of computing, and it is no longer optimal to rely solely on a single, known data path to insert application services. Furthermore, because many of the emerging data paths are not as suitable for a proxy-based platform, we must look to the other potential points of insertion possible to scale and secure modern applications.