
As AI and machine learning capabilities are increasingly viewed as critical to driving innovation and efficiency at companies of all sizes, organizations must determine how best to provide their application developers with access to those capabilities. In many instances, an AI inference service will be used—that being: “a service which invokes AI models to produce an output based on a given input” (such as predict a classification or generate text), most typically in response to an API call from other application code.
These inference services may be built and consumed in a wide variety of ways (even within a single organization). These services may be developed entirely in-house or be consumed as a SaaS, leverage open-source projects, and use open or commercial models. They may come as part of a fully functional “Machine Learning Platform” that supports wider data science and model creation efforts, or they might provide you with nothing but an API endpoint to invoke the models. They might run in a private data center, on a public cloud, in a colocation facility, or as a mix of these. Larger organizations are likely to rely on more than one single option for AI inference (especially at lower levels of organizational maturity in this space). While there’s no one-size-fits-all approach that will work for everybody, a handful of common patterns are emerging.
Pattern Overview
We’ll examine three broad AI inference consumption patterns, as well as their various strengths and weaknesses:
- AI Inference as a SaaS – Applications connect to an external dedicated AI inference service provider.
- Cloud Managed AI Inference – Applications connect to fully managed AI inference services running in public cloud.
- Self-Managed AI Inference – Applications consume AI inference managed by the organization itself, either as part of a centralized service, or directly at the application level.
Key Decision Points
When evaluating the tradeoffs between the following operating patterns, there are a few key factors to keep in mind:
Operational Considerations
Scalability – Who is responsible for, and how well does a given option scale up and down as capacity needs shift over time? Are there scale limits or ceilings on capacity?Cost – Fully managed services may appear to be more expensive at first glance but factoring the total cost of ownership (including any specialized hardware and staffing) may make the decision less clear. How do operational costs scale as capacity increases or decreases; are there floors on costs?Maintenance / Support – Who is responsible for maintaining the inference service? Will your organization need to hire employees or pay consultants with expertise in this area, or would a managed service offering make more sense?
Development Considerations
Ease of Workload Integration – How quickly can the AI service be integrated with the consuming workloads? Does the service offering work with your expected use pattern (e.g., offline / batch inference) and operating environments?Agility – How quickly can the overall application be adapted for changing business requirements? What aspects of the architecture are more baked-in, and would be difficult to change?
Performance Considerations
Performance – Does the physical location of the service (relative to service consumers) and the latency of the inferencing matter for your use cases?Hardware Availability – Are there any special hardware requirements for the service, and, if so, do you have the capacity to meet the expected demands (applicable to both on-prem and cloud environments)?
Data Considerations
Data Leakage – Is there a concern that sensitive data may be sent to the inference service or may be present in the inference result? If so, can the traffic be inspected, and guardrails be applied?Data Governance – Where geographically is the application data sent (and how)? Does direct control remain within the organization, or is it sent to third parties? Are there special regulations or compliance policies that apply to how you must treat the data?
SaaS Pattern
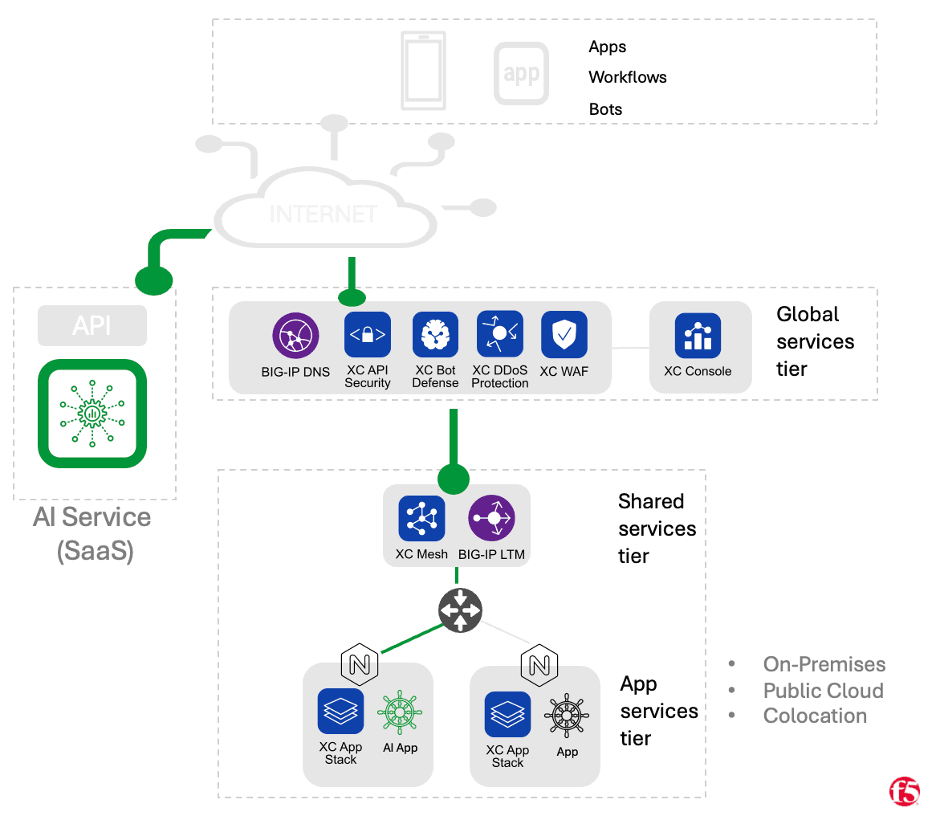
Organizations may choose to consume services from a dedicated SaaS provider which focuses on hosting AI models for inference (such as OpenAI or Cohere). In this case, workloads running on an organization’s infrastructure (be it private data center, colocation, or public cloud) leverage APIs published by the SaaS provider. With this pattern, the burden associated with operating the infrastructure required for hosting the models falls entirely on the SaaS provider, and the time it takes to get up and running can be very brief. These benefits, however, come at the cost of control, with this pattern being the least “flexible” of the ones we’ll cover. Likewise control over sensitive data is typically lowest with this model, where the public internet is usually used to connect with the service, and the external SaaS vendor is less likely to be able to address stringent regulatory compliance concerns.
Well Suited For
- Time to Market: Rapid prototyping, MVP releases.
- Organizations without significant in-house AI inferencing expertise/experience.
- Applications without significant or stringent data security/governance needs.
Strengths
- Short time to market: Simple operational model can lead to short integration times.
- Focused service providers are well equipped to deal with inference scaling challenges.
- Doesn’t require investment in specialized hardware or personnel.
Challenges
- Latency and connectivity concerns relative to services collocated with app workloads.
- Data privacy, governance, and security concerns are reliant on (or may be incompatible with) an external SaaS provider.
- Operating expense cost at larger scales may be higher than self-hosting models.
- Custom model hosting and model customization services may not be supported.
Cloud Managed Pattern
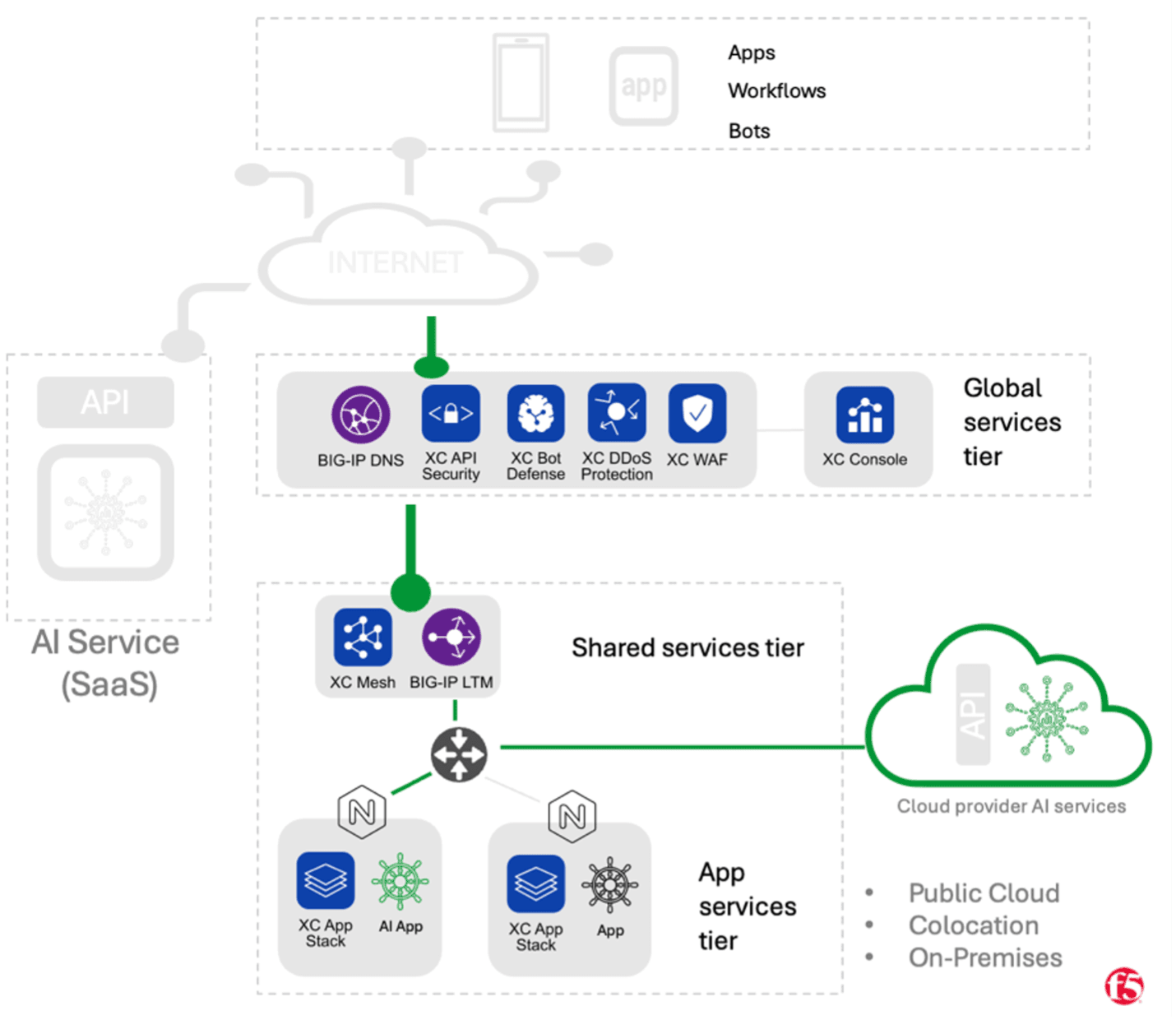
In this pattern, organizations leverage managed services provided by public cloud providers (for example, Azure OpenAI, Google Vertex, AWS Bedrock). As with the first pattern, the operational burden for deploying, scaling, and maintaining the AI models falls on the Cloud Provider rather than the consuming organization. The major difference between this pattern and the SaaS pattern above, is that in this case the inference API endpoints are generally accessible via private networks, and AI consumer workloads can be collocated with the AI Model service (e.g., same zone, region). As a result, the data typically doesn’t transit the public internet, latency is likely to be lower, and mechanisms for connecting to these services are similar to those for other cloud provider managed services (i.e., service accounts, access policies, network ACLs). Organizations leveraging multi-cloud networking may be able to realize some of these same benefits even in cases where workloads and AI inference services are hosted in different clouds.
Well Suited For
- Organizations with existing public cloud investments.
- Applications running in, or connecting to, other cloud managed services.
Strengths
- Many organizations are already familiar with connecting their workloads to other cloud provider managed services (e.g., databases, object stores, etc.).
- The operational and infrastructure burden for running and scaling models lands primarily on the cloud provider.
- Latency concerns and some data privacy concerns may be easier to address.
Challenges
- Multi/Hybrid cloud applications require additional effort to connect and secure.
- Lack of uniformity across cloud managed services and APIs may lead to vendor lock-in.
- Organizations without an extensive public cloud presence may face difficulties.
- Operational expense cost at larger scales may be higher than self-hosting models.
- Custom model hosting and model customization services may not be supported.
Self-Managed Pattern
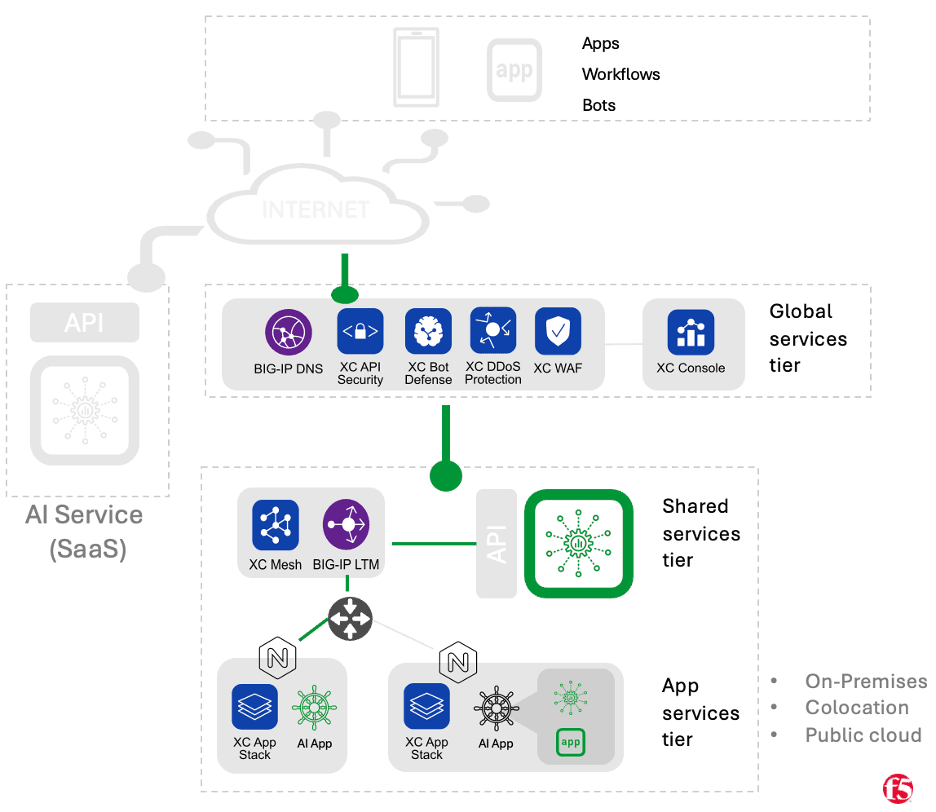
For the self-managed model, we’ll first discuss the case where AI model inference is run as a centralized “shared service,” then examine the case where no centralized service exists, and operational concerns are left up to individual application teams.
Self-Managed, Shared Service
In the “Shared Service” variant of the Self-Managed pattern, an organization may have dedicated team(s) responsible for maintaining inference infrastructure, the models that run on it, the APIs used to connect to it, and all operational aspects of the inference service lifecycle. As with the other patterns, AI application workloads would consume inference services through API calls. The model serving infrastructure might run in private data centers, public cloud, or at a colocation facility. The teams responsible for operating the inference service may take advantage of self-hosted machine learning platforms (such as Anyscale Ray or MLFlow). Alternatively, they might rely on more narrowly focused inference serving tools like Hugging Face’s Text Generation Inference server or software developed in-house. With self-managed inference, organizations are limited to using models that either they’ve trained themselves or are available to run locally (so proprietary models from a SaaS oriented service may not be an option).
Well Suited For
- Mature organizations with extensive infrastructure management experience.
- Organizations with heavy inference requirements that justify the TCO of a self-managed service.
- Applications with the most stringent data privacy and compliance requirements.
Strengths
- Organizations are in complete control of all aspects of the inference service.
- Data privacy challenges are typically easiest to address with self-hosted models.
- Cost at large scale may be more efficient than cloud managed or SaaS based inference services.
Challenges
- Organizations are in complete control of all aspects of the inference service (large infrastructure and staffing investments are likely to be required, along with ongoing maintenance, development, scalability concerns).
- Not typically cost effective for organizations with minimal inferencing needs and minimal data privacy concerns.
- No access to closed / proprietary models that may be available as SaaS or cloud managed services.
Self-Managed, Not A Shared Service
Organizations without a central team responsible for running AI inference services for applications to consume is the other variant of the Self-Managed pattern. In this version, individual application teams might run their models on the same infrastructure that’s been allocated to them for the application workload. They may choose to access those models via API or consume them directly in an “offline” fashion. With this pattern, developers may be able to realize some of the same benefits as the “Shared Service” self-managed model at a smaller scale.
Well Suited For
- Applications requiring batch processing and offline inference.
- Organizations with very light inference consumption, but strict data privacy and compliance requirements.
Strengths
- Most flexible for application developers, allowing a wide range of possibilities for integration with workloads.
- Can achieve data privacy and latency targets at small scale.
- May be more cost effective than the other models discussed in some cases (such as single team with heavy consumption requirements).
Challenges
- The operational burden for the model lifecycle is placed on individual application teams.
- Fails to take advantage of economies of scale as an organization’s consumption of AI inference grows (lack of consistency, inefficient resource utilization, etc.)
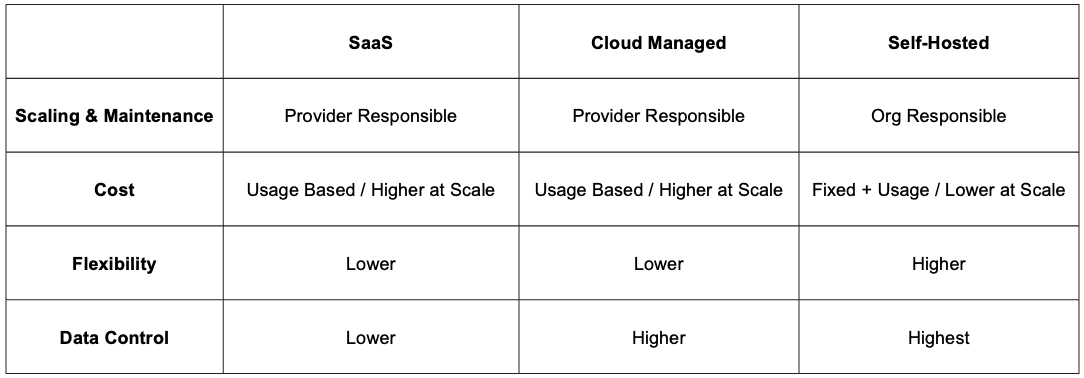
Summary Of Pattern Tradeoffs
Securing AI Apps and Model Inference Services
At their core, AI applications are a lot like any other modern app. They’re built with a mix of user-facing and backend components, often rely on external data stores, make heavy use of API calls, etc. These applications inherit the same security challenges common to all modern apps and need the same protections applied in the same manner (e.g., AuthNZ, DDoS protections, WAF, secure development practices, etc.). However, AI apps, and especially those leveraging generative AI, are also subject to a number of unique concerns that may not apply to other applications (for example, see OWASP Top 10 For LLMs). The generally unpredictable nature of these models can lead to novel problems, especially in use cases where the models are given significant agency.
Fortunately, due to the heavy reliance on API-driven interactions with AI model inference in the patterns discussed above, many organizations are already well positioned to implement these new security measures. For example, an API gateway that’s providing traditional rate limiting, authentication, authorization, and traffic management functionality might be extended to support token-based rate limits to help with cost control (either outbound at the app level to a SaaS/provider managed service or inbound RBAC authorization as a protection in front of a self-managed inference service). Likewise, infrastructure that’s currently performing traditional Web Application Firewall (WAF) services like checking for SQL injection or XSS, might be a logical place to add protections against prompt injection and similar attacks. Most modern observability practices are directly applicable to API-driven AI inference specific use cases, and teams should be able to make good use of existing tooling and practices in this space.
Conclusion
While the buzz surrounding AI powered applications and inference services is certainly new, the foundational principles at play when deploying and securing them have been around for a long time. Organizations will need to weigh tradeoffs as they determine how best to leverage AI capabilities, much as they do when consuming any other technology; based on their specific use cases, available resources, and long-term goals. Similarly, even though AI (and particularly generative AI) use cases do present some novel security challenges, the needs they share with other modern applications and the heavy reliance on API driven model interaction presents a great opportunity to use and extend existing patterns, practices, and tooling. Whether self-hosted or managed service, ensuring developers have access to a secure, scalable, performant solution that meets your specific business requirements is critical to maximizing the value and impact of your AI investments.
About the Author
Related Blog Posts

Multicloud chaos ends at the Equinix Edge with F5 Distributed Cloud CE
Simplify multicloud security with Equinix and F5 Distributed Cloud CE. Centralize your perimeter, reduce costs, and enhance performance with edge-driven WAAP.

At the Intersection of Operational Data and Generative AI
Help your organization understand the impact of generative AI (GenAI) on its operational data practices, and learn how to better align GenAI technology adoption timelines with existing budgets, practices, and cultures.
Using AI for IT Automation Security
Learn how artificial intelligence and machine learning aid in mitigating cybersecurity threats to your IT automation processes.
Most Exciting Tech Trend in 2022: IT/OT Convergence
The line between operation and digital systems continues to blur as homes and businesses increase their reliance on connected devices, accelerating the convergence of IT and OT. While this trend of integration brings excitement, it also presents its own challenges and concerns to be considered.
Adaptive Applications are Data-Driven
There's a big difference between knowing something's wrong and knowing what to do about it. Only after monitoring the right elements can we discern the health of a user experience, deriving from the analysis of those measurements the relationships and patterns that can be inferred. Ultimately, the automation that will give rise to truly adaptive applications is based on measurements and our understanding of them.
Inserting App Services into Shifting App Architectures
Application architectures have evolved several times since the early days of computing, and it is no longer optimal to rely solely on a single, known data path to insert application services. Furthermore, because many of the emerging data paths are not as suitable for a proxy-based platform, we must look to the other potential points of insertion possible to scale and secure modern applications.