
Background
In two previous articles we have focused on considerations for data-driven design; and specifically, around how business data represents latent business value. The key message has been that a structured data architecture is the technical foundation that enables extracting that inherent value. However, those articles focused on introducing the relevant topics at the conceptual level. Today, I would like to demonstrate the concepts in the context of a more tangible and relatable example; a story about how one might think about architecting an application consistent with a data-first mindset.
But First—Why Should I Care?
Before jumping straight to the story, though, let’s recap why data is more important today than it has been in the past. Collecting and storing data has historically been done by many businesses, primarily for its own sake, for reasons of governance, such as auditing and compliance. As such, data collection and storage has historically been viewed as a sort of “tax” on business operations, with little perceived direct operational business value.
What has changed now is the fuller appreciation that the collected data can be mined to optimize business processes and improve customer experience. For example, according to a recent survey of digital retail businesses, these two goals—upgrading the business processes and the customer experience—were the primary drivers of digital transformation for 57% of all surveyed businesses. The critical observation, the essence of “why it matters,” is that data-driven workflows impact the business in both externally-facing domains (such as for customer experience) and in the internally-facing domains, for core business processes. This is why a thoughtful and deliberate data strategy is fundamental to enabling the quality and cost-effectiveness of the most important business workflows. Further, when the workflows are instrumented to transmit their observed data exhaust to a data collection and analysis infrastructure, the workflows themselves can be continuously analyzed and improved, resulting in constantly adaptive and optimized business workflows.
As a side note, these same businesses’ most serious anxiety around digital transformation was ensuring the cybersecurity of these same digital processes—which, as it turns out, is another area where this same data telemetry and analysis approach has a key role to play—though I will save that for another article.
The Application: Restaurant Ordering & Delivery
Moving on to our thought experiment, I have chosen a story that many of us can probably relate to in today’s Coronavirus-adapted lifestyle—an application that provides an online service for restaurant food ordering and delivery. The meals are ordered online from a customer-specified restaurant, and the user can choose to have the order be picked up by the customer directly, or to have the service perform the delivery as well.
In this story, we will play the role of the Application Owner. In that role, we need to address many different concerns, which we will divide into two buckets—first, required operational activities, and, second, forward-looking strategic concerns.
The first set—required operational activities—include concerns such as:
- Finding and characterizing restaurants including their location and operating hours
- Collating data on menu items and prices
- Informing restaurants of orders
- Processing payments
- Keeping data on availability of human resources to pick up and deliver orders
- Tracking order readiness and delivery status
The second set of concerns are less day-to-day operational, but no less important. These issues—if thought about up-front—will enable the business to be agile, adaptive, and continuously improving. Examples of these sorts of concerns are:
- How can demand be forecasted? This could simply be aggregate demand by time-of-day/week, or could be finer grain, such as per-restaurant.
- What sort of tools, processes, or workflows provide business insights for my suppliers (restaurants)?
- How can pricing—for either the food or for delivery—be dynamically adjusted?
- Assuming my application is hosted in the public cloud, how can my operational infrastructure costs be optimized?
This is, of course, a subset of the full richness of concerns we would have, but even this smaller set suffices to enable a good discussion that highlights the importance of structured data architecture in support of an extensible data processing pipeline.
Data Architecture or Data Pipeline/Chicken or the Egg
In our imagined role of an Application Owner, as we consider our overall data strategy, we can start by enumerating our business workflows, identifying the data processing needs of each. An example is the workflow that locates nearby open restaurants, and then presents menu selections and item prices for each—it would need to filter restaurants by location and business hours, and then look up menu selections for a specifically selected restaurant, perhaps also filtered by the availability of delivery drivers. And we could do this for each workflow—payment processing, matching drivers with deliveries, and so on.
Or, equally reasonably, we might instead start our considerations with the basic data “atoms”—the data building blocks that are needed. We would identify and enumerate the important data atoms, paying particular attention to having uniform representation and consistent semantics of those data atoms along with any metadata vocabulary needed in support of our business workflows. Examples of data atoms in our sample application would include: location data for restaurants, customers, and drivers; food items needed for menus and invoices; time, used for filtering and tracking quality of delivery; and payment information, associated with customer and driver payments workflows.
Which of these two potential jumping off points—the workflows’ data processing pipeline, or, alternately, the data “atoms”—to use to for our data strategy is a chicken-or-egg question. Both perspectives are useful, and more importantly, are interdependent. We cannot reason about the data processing pipeline without thinking about the underlying data atoms, nor can we develop the data architecture without considering the needs of the processing pipeline. That said, however—in general, I would recommend an approach where one makes a first pass across the workflows to enumerate the data atoms, but then approaches the structured design of the data architecture before doing the detailed design of the data pipeline. This is because the workflows are more dynamic; workflows get added and modified as the business evolves, while the underlying data has more history and inertia—and therefore the data architecture benefits more from forethought.
Applying a Holistic Data Architecture and Pipeline Approach to Concrete Examples
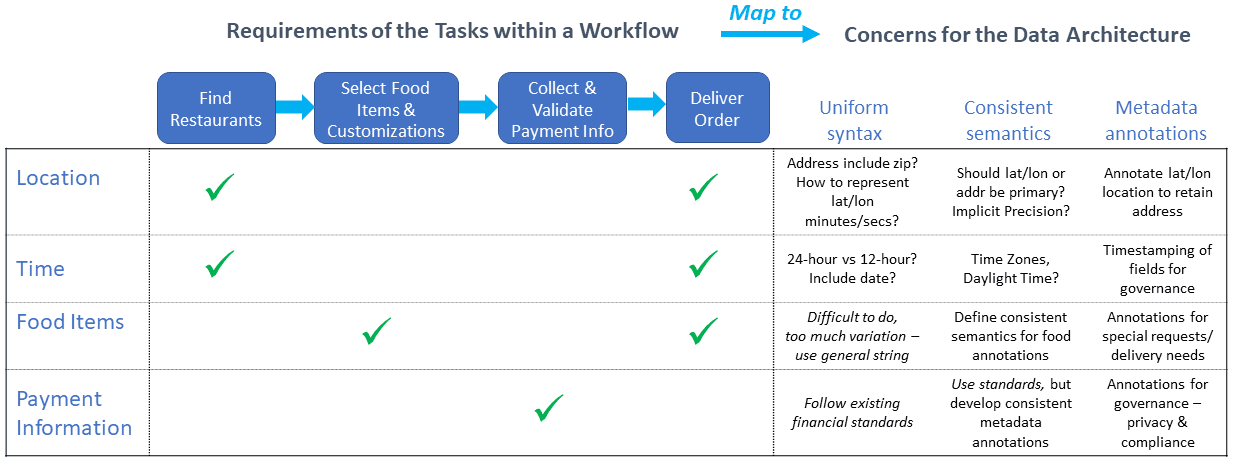
Going back to our example, let us assume that, as an Application Owner, we have a fairly developed view of the key business-critical workflows and the data atoms that are needed to support them. Earlier in this discussion, we had identified a few of the foundational data elements needed for our workflows: location, time, food items, and payment information. And, to recap from earlier articles, the data architecture should enable 3 key objectives: uniformity of syntax, consistency of semantics, and a metadata vocabulary for reasoning about and governing the data. So now, we can apply these principles to discuss data architecture considerations for the specific data atoms enumerated in today’s example.
Zooming in on the location data atom, consider each of the 3 key data architecture objectives.
- First, what is the uniform data representation syntax?
An initial thought may be to represent location by street address, since that is how restaurants and customers typically represent their location. However, consider the location needs for tracking drivers doing delivery—they are often in motion, perhaps on a major highway or at a location that is not well described by a street address. Instead, a latitude and longitude specification may be a better way to represent location for that workflow, and this format would still work for restaurant and customer locations. But because drivers must typically navigate to a restaurant or a customer location, there must still be a way to relate a driver’s (lat/lon) location to a customer’s (street address) location. Therefore, a more considered choice may be to normalize all location data at latitude & longitude (the required “canonical” representation), but with the ability to convert street addresses to lat/lon when the street address is first provided (an “ingestion” workflow). - The second consideration is that of consistent semantics.
Assuming location is normalized as lat/lon, this is relatively straightforward, because this is a well-established standard with unambiguous interpretation. However, another aspect of consistent semantics is around precision—the implied exactness of the data. Given GPS and mapping data will have an implicitly limited accuracy, we may choose to specify the location with either a constant precision (e.g., such to the nearest arc-second, roughly 100 feet) or with variable precision, depending on the quality of the data source. If we choose the latter for flexibility, we must annotate—using metadata, described next—the precision of each location data instance. - The third goal of the data architecture is to have the capability to annotate and enrich the collected data elements.
In the case of location, this may include the precision of the data, as mentioned previously. In addition, though, we may also want to annotate the location with a street address for human-friendliness, and especially so that ingested address data can be preserved. This is especially important for cases where multiple street addresses may map to the same lat/lon, such as an apartment complex. Yet another enrichment may be a timestamp for when the location data field was collected, which may be relevant for a driver in motion where location data becomes stale quickly.
We have only talked about the requirements for location and could now walk through a similar exercise for each of the other data fields. However, rather than enumerating all the areas of concerns for each of the data atoms, I will instead highlight a few notable observations:
- Regarding the Time data atom: The representation of a time value is notoriously tricky. It may vary, both syntactically (e.g., 24-hour format vs. 12-hour plus AM/PM) and semantically (e.g., the concept of time zones & variation across observation of daylight time). Therefore, the representation of time will likely need to be canonicalized (such as by normalizing to GMT, or seconds “since epoch” for Unix/Linux users).
- Food Item data instances can be quite varied, with unique needs. Because they data atoms are often freeform, a canonical metadata vocabulary is more useful than attempting uniform syntax. Some metadata fields would be for per-item static properties, such as “needs to remain cold,” or “contains nuts,” but other metadata fields would be required for per-instance (per-order) food item information, such as “spiciness level” or “preferred condiments.” In either case, the design goal requires uniform syntax and consistent semantics for the metadata fields, so they can be shared across the full inventory of menu items.
- Other key considerations are data compliance and governance. One aspect is data retention policy, where some fields—such as a customer’s IP address or a driver’s location history—can be persisted only for a short period of time. Another common consideration is that some fields may have security or privacy constraints; an example is payment information. Metadata augmentation is a solution for both cases. Metadata should be used to annotate an IP address or location value with a data expiration time for data retention. In the case of payment information, metadata can be used to convey security requirements—such as the need for encryption of data at rest, or to specify geolocation constraints of the persistent data store.
While this example has still only skimmed the surface, it has highlighted many of the concerns associated with real-world scenarios. In the real world, however, the process of thinking through the data strategy would not end here but would be iterative and ongoing. As the data elements are fed into the data processing pipelines that embody business workflows, iterative adjustments and enhancements would be made to the data architecture. As existing workflows are enhanced and new workflows added, we would discover additional data architecture requirements for existing data atoms along with new data atoms.
Closing Thoughts
Although this example has been streamlined for brevity, it still demonstrates the key principles around mapping workflows to their data architecture implications. The process always begins by considering the business needs—the customer experience and the business processes required to meet those needs. The business processes, in turn, define the elements of a business vocabulary. At the next level of specificity, the processes map to a data pipeline, which leverages a data vocabulary.
The key principle is that the robust data architecture—one that defines syntax, semantics, and annotations—builds a foundation that allows the data pipeline to be efficiently enhanced and new workflows to be readily added. At the business layer abstraction, this means that existing business processes can easily be modified, and new or emerging business processes can be quickly brought online. Conversely, failure to make considered decisions in any of these areas—data vocabulary, data architecture framework, or linking these back to the business needs—will ultimately lead to a brittle and fragile system, one that will not be agile to new business requirements.
About the Author
Related Blog Posts

Multicloud chaos ends at the Equinix Edge with F5 Distributed Cloud CE
Simplify multicloud security with Equinix and F5 Distributed Cloud CE. Centralize your perimeter, reduce costs, and enhance performance with edge-driven WAAP.

At the Intersection of Operational Data and Generative AI
Help your organization understand the impact of generative AI (GenAI) on its operational data practices, and learn how to better align GenAI technology adoption timelines with existing budgets, practices, and cultures.
Using AI for IT Automation Security
Learn how artificial intelligence and machine learning aid in mitigating cybersecurity threats to your IT automation processes.
Most Exciting Tech Trend in 2022: IT/OT Convergence
The line between operation and digital systems continues to blur as homes and businesses increase their reliance on connected devices, accelerating the convergence of IT and OT. While this trend of integration brings excitement, it also presents its own challenges and concerns to be considered.
Adaptive Applications are Data-Driven
There's a big difference between knowing something's wrong and knowing what to do about it. Only after monitoring the right elements can we discern the health of a user experience, deriving from the analysis of those measurements the relationships and patterns that can be inferred. Ultimately, the automation that will give rise to truly adaptive applications is based on measurements and our understanding of them.
Inserting App Services into Shifting App Architectures
Application architectures have evolved several times since the early days of computing, and it is no longer optimal to rely solely on a single, known data path to insert application services. Furthermore, because many of the emerging data paths are not as suitable for a proxy-based platform, we must look to the other potential points of insertion possible to scale and secure modern applications.