Construyendo microservicios: Comunicación entre procesos en una arquitectura de microservicios

Editor – Esta serie de siete artículos ya está completa:
- Introducción a los microservicios
- Construyendo microservicios: Uso de una API Gateway
- Construyendo microservicios: Comunicación entre procesos en una arquitectura de microservicios (este artículo)
- Descubrimiento de servicios en una arquitectura de microservicios
- Gestión de datos basada en eventos para microservicios
- Elección de una estrategia de implementación de microservicios
- Refactorización de un monolito en microservicios
También puede descargar el conjunto completo de artículos, además de información sobre la implementación de microservicios utilizando NGINX Plus, como un libro electrónico: Microservicios: Desde el diseño hasta la implementación . Además, consulte la nueva página de Soluciones de Microservicios .
Este es el tercer artículo de nuestra serie sobre la creación de aplicaciones con una arquitectura de microservicios. El primer artículo presenta el patrón de Arquitectura de Microservicios , lo compara con el patrón de Arquitectura Monolítica y analiza los beneficios y desventajas de usar microservicios. El segundo artículo describe cómo los clientes de una aplicación se comunican con los microservicios a través de un intermediario conocido como API Gateway . En este artículo, analizamos cómo se comunican entre sí los servicios dentro de un sistema. El cuarto artículo explora el problema estrechamente relacionado del descubrimiento de servicios.
INTRODUCCIÓN
En una aplicación monolítica, los componentes se invocan entre sí mediante llamadas a métodos o funciones a nivel de lenguaje. Por el contrario, una aplicación basada en microservicios es un sistema distribuido que se ejecuta en varias máquinas. Cada instancia de servicio suele ser un proceso. En consecuencia, como muestra el siguiente diagrama, los servicios deben interactuar utilizando un mecanismo de comunicación entre procesos (IPC).
Más adelante analizaremos tecnologías de IPC específicas, pero primero exploremos varias cuestiones de diseño.
Estilos de interacción
Al seleccionar un mecanismo de IPC para un servicio, es útil pensar primero en cómo interactúan los servicios. Hay una variedad de estilos de interacción cliente⇔servicio. Se pueden clasificar en dos dimensiones. La primera dimensión es si la interacción es de uno a uno o de uno a muchos:
- Uno a uno: cada solicitud de cliente es procesada por exactamente una instancia de servicio.
- Uno a muchos: cada solicitud es procesada por múltiples instancias de servicio.
La segunda dimensión es si la interacción es sincrónica o asincrónica:
- Sincrónico: el cliente espera una respuesta oportuna del servicio e incluso podría bloquearse mientras espera.
- Asíncrono: el cliente no se bloquea mientras espera una respuesta y la respuesta, si la hay, no necesariamente se envía de inmediato.
La siguiente tabla muestra los distintos estilos de interacción.
| Cara a cara | Uno a muchos | |
|---|---|---|
| Sincrónico | Solicitud/respuesta | — |
| Asincrónico | Notificación | Publicar/suscribirse |
| Solicitud/respuesta asíncrona | Respuestas de publicación/asincrónicas |
Existen los siguientes tipos de interacciones uno a uno:
- Solicitud/respuesta: un cliente realiza una solicitud a un servicio y espera una respuesta. El cliente espera que la respuesta llegue de manera oportuna. En una aplicación basada en subprocesos, el subproceso que realiza la solicitud podría incluso bloquearse mientras espera.
- Notificación (también conocida como solicitud unidireccional): un cliente envía una solicitud a un servicio, pero no se espera ni envía ninguna respuesta.
- Solicitud/respuesta asincrónica: un cliente envía una solicitud a un servicio, que responde de forma asincrónica. El cliente no se bloquea mientras espera y está diseñado con el supuesto de que la respuesta podría no llegar por un tiempo.
Existen los siguientes tipos de interacciones de uno a muchos:
- Publicar/suscribirse: un cliente publica un mensaje de notificación, que es consumido por cero o más servicios interesados.
- Respuestas de publicación/asincrónicas: un cliente publica un mensaje de solicitud y luego espera una cierta cantidad de tiempo para recibir respuestas de los servicios interesados.
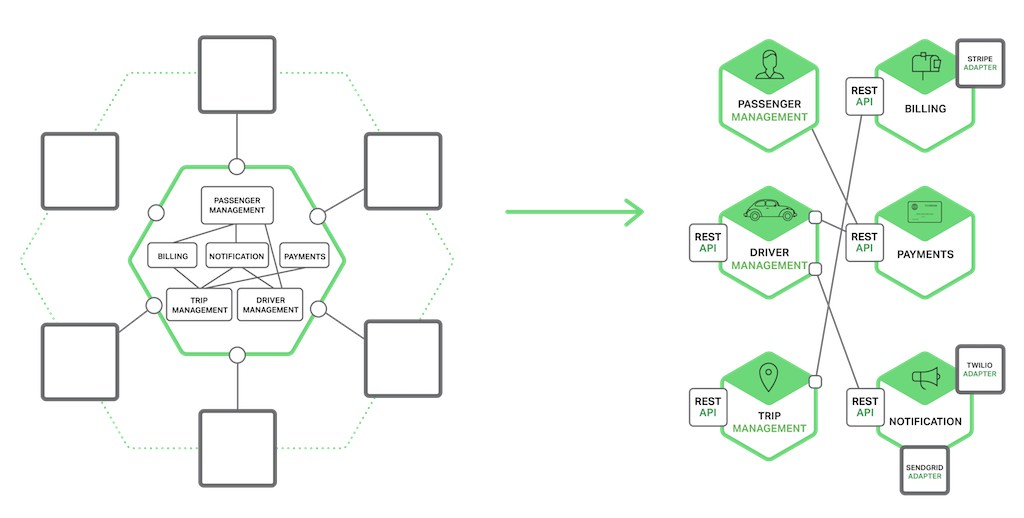
Cada servicio normalmente utiliza una combinación de estos estilos de interacción. Para algunos servicios, un único mecanismo de IPC es suficiente. Es posible que otros servicios necesiten utilizar una combinación de mecanismos de IPC. El siguiente diagrama muestra cómo los servicios en una aplicación de solicitud de taxis podrían interactuar cuando el usuario solicita un viaje.

Los servicios utilizan una combinación de notificaciones, solicitud/respuesta y publicación/suscripción. Por ejemplo, el teléfono inteligente del pasajero envía una notificación al servicio de gestión de viajes para solicitar una recogida. El servicio de Gestión de viajes verifica que la cuenta del pasajero esté activa mediante una solicitud/respuesta para invocar el Servicio de Pasajeros. Luego, el servicio de gestión de viajes crea el viaje y utiliza la función de publicación/suscripción para notificar a otros servicios, incluido el despachador, que ubica un conductor disponible.
Ahora que hemos analizado los estilos de interacción, veamos cómo definir las API.
Definición de API
La API de un servicio es un contrato entre el servicio y sus clientes. Independientemente del mecanismo de IPC que elija, es importante definir con precisión la API de un servicio utilizando algún tipo de lenguaje de definición de interfaz (IDL). Incluso existen buenos argumentos a favor de utilizar un enfoque API-first para definir servicios. Comienza el desarrollo de un servicio escribiendo la definición de la interfaz y revisándola con los desarrolladores del cliente. Solo después de iterar sobre la definición de API se puede implementar el servicio. Realizar este diseño por adelantado aumenta sus posibilidades de crear un servicio que satisfaga las necesidades de sus clientes.
Como verá más adelante en este artículo, la naturaleza de la definición de API depende del mecanismo de IPC que esté utilizando. Si utiliza mensajería, la API consta de los canales de mensajes y los tipos de mensajes. Si utiliza HTTP, la API consta de las URL y los formatos de solicitud y respuesta. Más adelante describiremos algunos IDL con más detalle.
API en evolución
La API de un servicio cambia invariablemente con el tiempo. En una aplicación monolítica, normalmente es sencillo cambiar la API y actualizar todos los llamadores. En una aplicación basada en microservicios es mucho más difícil, incluso si todos los consumidores de su API son otros servicios en la misma aplicación. Generalmente no es posible obligar a todos los clientes a actualizarse al mismo tiempo que el servicio. Además, probablemente implementará de manera incremental nuevas versiones de un servicio, de modo que tanto las versiones antiguas como las nuevas del servicio se ejecuten simultáneamente. Es importante tener una estrategia para abordar estos problemas.
La forma de gestionar un cambio de API depende del tamaño del cambio. Algunos cambios son menores y compatibles con la versión anterior. Podría, por ejemplo, agregar atributos a las solicitudes o respuestas. Tiene sentido diseñar clientes y servicios de manera que observen el principio de robustez . Los clientes que utilizan una API antigua deben seguir trabajando con la nueva versión del servicio. El servicio proporciona valores predeterminados para los atributos de solicitud faltantes y los clientes ignoran cualquier atributo de respuesta adicional. Es importante utilizar un mecanismo de IPC y un formato de mensajería que le permita evolucionar fácilmente sus API.
Sin embargo, a veces es necesario realizar cambios importantes e incompatibles en una API. Dado que no se puede obligar a los clientes a actualizar inmediatamente, un servicio debe ser compatible con versiones anteriores de la API durante un tiempo. Si está utilizando un mecanismo basado en HTTP, como REST, un enfoque es incorporar el número de versión en la URL. Cada instancia de servicio podría manejar múltiples versiones simultáneamente. Como alternativa, puede implementar diferentes instancias que manejen cada una una versión particular.
Manejo de fallos parciales
Consideremos, por ejemplo, el escenario de Detalles del producto de ese artículo. Imaginemos que el Servicio de Recomendaciones no responde. Una implementación ingenua de un cliente podría bloquearse indefinidamente esperando una respuesta. Esto no sólo daría como resultado una mala experiencia de usuario, sino que en muchas aplicaciones consumiría un recurso valioso como un hilo. Con el tiempo, el tiempo de ejecución se quedaría sin subprocesos y dejaría de responder, como se muestra en la siguiente figura.

Para evitar este problema, es esencial que diseñe sus servicios para manejar fallas parciales.
Una buena manera de acercarse a nosotros es la descrita por Netflix . Las estrategias para afrontar fallos parciales incluyen:
- Tiempos de espera de red: nunca bloquee indefinidamente y siempre use tiempos de espera cuando espere una respuesta. El uso de tiempos de espera garantiza que los recursos nunca queden bloqueados indefinidamente.
- Limitar la cantidad de solicitudes pendientes: imponer un límite superior a la cantidad de solicitudes pendientes que un cliente puede tener con un servicio en particular. Si se ha alcanzado el límite, probablemente no tenga sentido realizar solicitudes adicionales y esos intentos deben fallar inmediatamente.
- Patrón de disyuntor : realiza un seguimiento del número de solicitudes exitosas y fallidas. Si la tasa de error excede un umbral configurado, dispare el disyuntor para que los intentos posteriores fallen inmediatamente. Si fallan una gran cantidad de solicitudes, eso sugiere que el servicio no está disponible y que enviar solicitudes no tiene sentido. Después de un período de espera, el cliente debe volver a intentarlo y, si tiene éxito, cerrar el disyuntor.
- Proporcionar alternativas: ejecute la lógica de alternativa cuando falla una solicitud. Por ejemplo, devolver datos almacenados en caché o un valor predeterminado, como un conjunto vacío de recomendaciones.
Netflix Hystrix es una biblioteca de código abierto que implementa estos y otros patrones. Si está utilizando la JVM, definitivamente debería considerar usar Hystrix. Y, si se ejecuta en un entorno que no sea JVM, debe utilizar una biblioteca equivalente.
Tecnologías IPC
Hay muchas tecnologías de IPC diferentes para elegir. Los servicios pueden utilizar mecanismos de comunicación sincrónicos basados en solicitud/respuesta, como REST basado en HTTP o Thrift. Alternativamente, pueden utilizar mecanismos de comunicación asincrónicos basados en mensajes, como AMQP o STOMP. También hay una variedad de diferentes formatos de mensajes. Los servicios pueden utilizar formatos basados en texto legibles por humanos, como JSON o XML. Alternativamente, pueden utilizar un formato binario (que es más eficiente) como Avro o Protocol Buffers. Más adelante veremos los mecanismos de IPC sincrónicos, pero primero analicemos los mecanismos de IPC asincrónicos.
Comunicación asincrónica basada en mensajes
Al utilizar mensajería, los procesos se comunican intercambiando mensajes de forma asincrónica. Un cliente realiza una solicitud a un servicio enviándole un mensaje. Si se espera que el servicio responda, lo hace enviando un mensaje separado al cliente. Como la comunicación es asincrónica, el cliente no se bloquea esperando una respuesta. En cambio, se escribe al cliente asumiendo que la respuesta no será inmediata.
Un mensaje consta de encabezados (metadatos como el remitente) y un cuerpo del mensaje. Los mensajes se intercambian a través de canales . Cualquier número de productores puede enviar mensajes a un canal. De manera similar, cualquier número de consumidores puede recibir mensajes de un canal. Hay dos tipos de canales: punto a punto y publicación-suscripción . Un canal punto a punto envía un mensaje a exactamente uno de los consumidores que está leyendo desde el canal. Los servicios utilizan canales punto a punto para los estilos de interacción uno a uno descritos anteriormente. Un canal de publicación-suscripción envía cada mensaje a todos los consumidores asociados. Los servicios utilizan canales de publicación-suscripción para los estilos de interacción de uno a muchos descritos anteriormente.
El siguiente diagrama muestra cómo la aplicación de solicitud de taxis podría utilizar canales de publicación-suscripción.
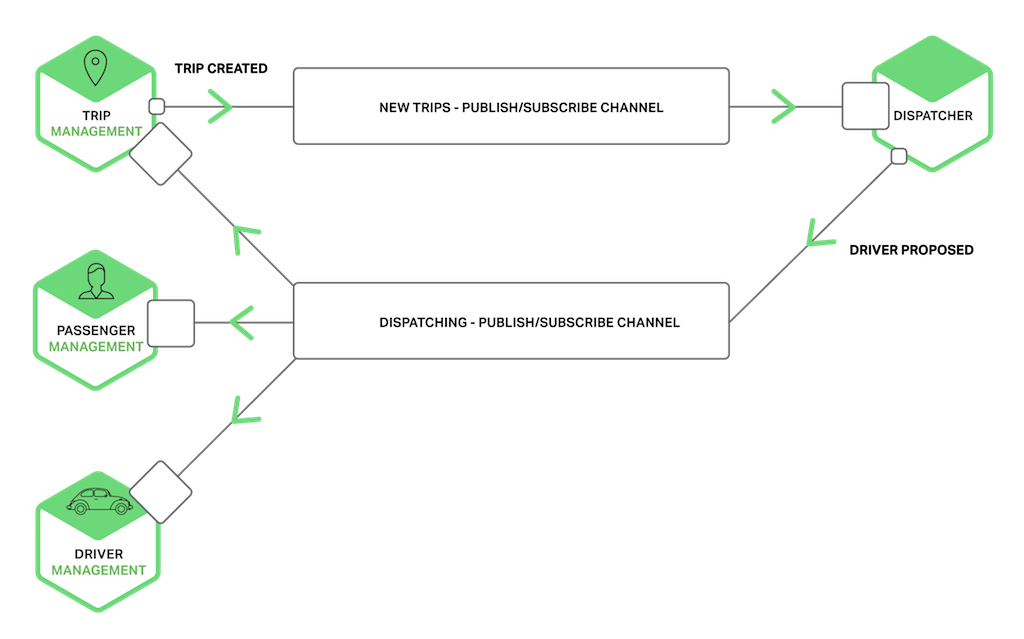
El servicio de Gestión de viajes notifica a los servicios interesados, como el Despachador, acerca de un nuevo Viaje escribiendo un mensaje de Viaje creado en un canal de publicación-suscripción. El despachador encuentra un conductor disponible y notifica a otros servicios escribiendo un mensaje de Conductor propuesto en un canal de publicación-suscripción.
Hay muchos sistemas de mensajería para elegir. Debe elegir uno que admita una variedad de lenguajes de programación. Algunos sistemas de mensajería admiten protocolos estándar como AMQP y STOMP. Otros sistemas de mensajería tienen protocolos propietarios pero documentados. Hay una gran cantidad de sistemas de mensajería de código abierto para elegir, incluidos RabbitMQ , Apache Kafka , Apache ActiveMQ y NSQ . A un alto nivel, todos admiten algún tipo de mensajes y canales. Todos ellos se esfuerzan por ser confiables, de alto rendimiento y escalables. Sin embargo, existen diferencias significativas en los detalles del modelo de mensajería de cada broker.
El uso de la mensajería tiene muchas ventajas:
- Desacopla al cliente del servicio: un cliente realiza una solicitud simplemente enviando un mensaje al canal apropiado. El cliente desconoce completamente las instancias del servicio. No es necesario utilizar un mecanismo de descubrimiento para determinar la ubicación de una instancia de servicio.
- Almacenamiento en búfer de mensajes: con un protocolo de solicitud/respuesta sincrónica, como HTTP, tanto el cliente como el servicio deben estar disponibles mientras dure el intercambio. Por el contrario, un agente de mensajes pone en cola los mensajes escritos en un canal hasta que el consumidor pueda procesarlos. Esto significa, por ejemplo, que una tienda en línea puede aceptar pedidos de clientes incluso cuando el sistema de cumplimiento de pedidos sea lento o no esté disponible. Los mensajes de pedido simplemente se ponen en cola.
- Interacciones flexibles entre el cliente y el servicio: la mensajería admite todos los estilos de interacción descritos anteriormente.
- Comunicación explícita entre procesos: los mecanismos basados en RPC intentan hacer que invocar un servicio remoto parezca lo mismo que llamar a un servicio local. Sin embargo, debido a las leyes de la física y la posibilidad de fallo parcial, en realidad son bastante diferentes. Los mensajes hacen que estas diferencias sean muy explícitas para que los desarrolladores no caigan en una falsa sensación de seguridad.
Sin embargo, el uso de la mensajería tiene algunas desventajas:
- Complejidad operativa adicional: el sistema de mensajería es otro componente del sistema que debe instalarse, configurarse y operarse. Es esencial que el agente de mensajes tenga alta disponibilidad; de lo contrario, la confiabilidad del sistema se verá afectada.
- Complejidad de implementar la interacción basada en solicitud/respuesta: la interacción de estilo solicitud/respuesta requiere cierto trabajo para implementarla. Cada mensaje de solicitud debe contener un identificador de canal de respuesta y un identificador de correlación. El servicio escribe un mensaje de respuesta que contiene el ID de correlación al canal de respuesta. El cliente utiliza el ID de correlación para hacer coincidir la respuesta con la solicitud. A menudo es más fácil utilizar un mecanismo IPC que admita directamente la solicitud/respuesta.
Ahora que hemos visto el uso de IPC basado en mensajería, examinemos el IPC basado en solicitud/respuesta.
IPC síncrono, solicitud/respuesta
Cuando se utiliza un mecanismo de IPC sincrónico basado en solicitud/respuesta, un cliente envía una solicitud a un servicio. El servicio procesa la solicitud y envía una respuesta. En muchos clientes, el hilo que realiza la solicitud se bloquea mientras espera una respuesta. Otros clientes pueden usar código de cliente asincrónico, controlado por eventos, que quizás esté encapsulado por Futures o Rx Observables. Sin embargo, a diferencia de lo que ocurre cuando se utiliza la mensajería, el cliente asume que la respuesta llegará de manera oportuna. Hay numerosos protocolos para elegir. Dos protocolos populares son REST y Thrift. Primero echemos un vistazo a REST.
DESCANSAR
Hoy en día está de moda desarrollar APIs al estilo RESTful . REST es un mecanismo de IPC que (casi siempre) utiliza HTTP. Un concepto clave en REST es un recurso, que normalmente representa un objeto comercial como un Cliente o Producto, o una colección de objetos comerciales. REST utiliza los verbos HTTP para manipular recursos, a los que se hace referencia mediante una URL. Por ejemplo, una solicitud GET devuelve la representación de un recurso, que podría tener la forma de un documento XML o un objeto JSON. Una solicitud POST crea un nuevo recurso y una solicitud PUT actualiza un recurso. Para citar a Roy Fielding, el creador de REST:
El siguiente diagrama muestra una de las formas en que la aplicación de solicitud de taxis podría utilizar REST.
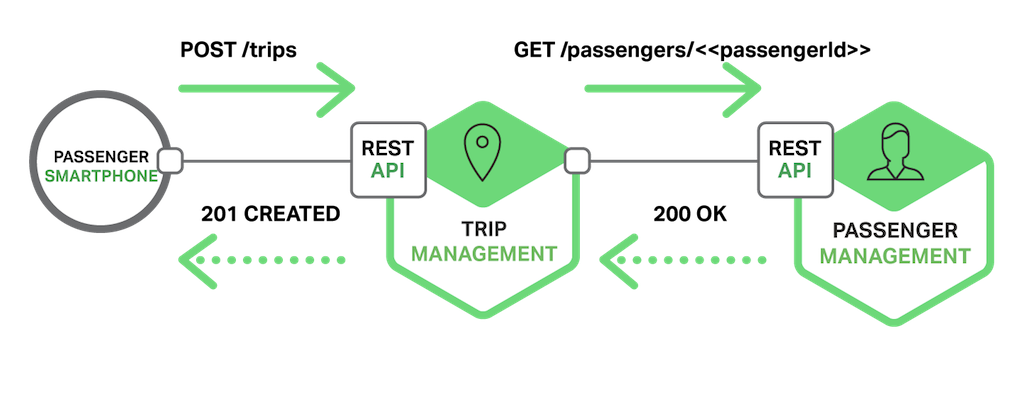
El teléfono inteligente del pasajero solicita un viaje realizando una solicitud POST al recurso /trips del servicio de Gestión de Viajes. Este servicio gestiona la solicitud enviando una solicitud GET de información sobre el pasajero al servicio de Gestión de Pasajeros. Después de verificar que el pasajero está autorizado para crear un viaje, el servicio de Gestión de Viajes crea el viaje y devuelve un201 respuesta al teléfono inteligente.
Muchos desarrolladores afirman que sus API basadas en HTTP son RESTful. Sin embargo, como describe Fielding en esta entrada del blog , no todos lo son realmente. Leonard Richardson (sin relación) define un modelo de madurez muy útil para REST que consta de los siguientes niveles.
- Nivel 0: los clientes de una API de nivel 0 invocan el servicio realizando solicitudes HTTP
POSTa su único punto final URL. Cada solicitud especifica la acción a realizar, el objetivo de la acción (por ejemplo, el objeto comercial) y cualquier parámetro. - Nivel 1: una API de nivel 1 admite la idea de recursos. Para realizar una acción en un recurso, un cliente realiza una solicitud
POSTque especifica la acción a realizar y cualquier parámetro. - Nivel 2: una API de nivel 2 utiliza verbos HTTP para realizar acciones:
GETpara recuperar,POSTpara crear yPUTpara actualizar. Los parámetros de consulta de la solicitud y el cuerpo, si los hay, especifican los parámetros de la acción. Esto permite que los servicios aprovechen la infraestructura web, como el almacenamiento en caché para solicitudesGET. - Nivel 3 – El diseño de una API de nivel 3 se basa en el principio terriblemente llamado HATEOAS (hipertexto como motor del estado de la aplicación ). La idea básica es que la representación de un recurso devuelto por una solicitud
GETcontiene vínculos para realizar las acciones permitidas en ese recurso. Por ejemplo, un cliente puede cancelar un pedido utilizando un enlace en la representación del pedido devuelta en respuesta a la solicitudGETenviada para recuperar el pedido. Los beneficios de HATEOAS incluyen no tener que cablear las URL en el código del cliente. Otro beneficio es que, debido a que la representación de un recurso contiene enlaces para las acciones permitidas, el cliente no tiene que adivinar qué acciones se pueden realizar en un recurso en su estado actual.
Existen numerosos beneficios al utilizar un protocolo basado en HTTP:
- HTTP es simple y familiar.
- Puede probar una API HTTP desde un navegador usando una extensión como Postman o desde la línea de comando usando
curl(asumiendo que se usa JSON o algún otro formato de texto). - Admite directamente la comunicación de tipo solicitud/respuesta.
- El protocolo HTTP es, por supuesto, compatible con firewalls.
- No requiere un intermediario, lo que simplifica la arquitectura del sistema.
El uso de HTTP presenta algunas desventajas:
- Solo admite directamente el estilo de interacción solicitud/respuesta. Puede utilizar HTTP para las notificaciones, pero el servidor siempre debe enviar una respuesta HTTP.
- Dado que el cliente y el servicio se comunican directamente (sin un intermediario que almacene los mensajes), ambos deben estar en ejecución mientras dure el intercambio.
- El cliente debe conocer la ubicación (es decir, la URL) de cada instancia de servicio. Como se describe en el artículo anterior sobre API Gateway , este es un problema no trivial en una aplicación moderna. Los clientes deben utilizar un mecanismo de descubrimiento de servicios para localizar instancias de servicio.
La comunidad de desarrolladores ha redescubierto recientemente el valor de un lenguaje de definición de interfaz para las API RESTful. Hay algunas opciones, incluidas RAML y Swagger . Algunos IDL como Swagger le permiten definir el formato de los mensajes de solicitud y respuesta. Otros, como RAML, requieren el uso de una especificación separada, como JSON Schema . Además de describir las API, los IDL suelen tener herramientas que generan stubs de cliente y esqueletos de servidor a partir de una definición de interfaz.
Ahorro
Apache Thrift es una alternativa interesante a REST. Es un marco para escribir clientes y servidores RPC en varios lenguajes. Thrift proporciona un IDL estilo C para definir sus API. Utilice el compilador Thrift para generar stubs del lado del cliente y esqueletos del lado del servidor. El compilador genera código para una variedad de lenguajes, incluidos C++, Java, Python, PHP, Ruby, Erlang y Node.js.
Una interfaz Thrift consta de uno o más servicios. Una definición de servicio es análoga a una interfaz Java. Es una colección de métodos fuertemente tipados. Los métodos Thrift pueden devolver un valor (posiblemente nulo) o pueden definirse como unidireccionales. Los métodos que devuelven un valor implementan el estilo de interacción solicitud/respuesta. El cliente espera una respuesta y podría lanzar una excepción. Los métodos unidireccionales corresponden al estilo de notificación de interacción. El servidor no envía una respuesta.
Thrift admite varios formatos de mensajes: JSON, binario y binario compacto. El binario es más eficiente que JSON porque es más rápido de decodificar. Y, como sugiere su nombre, el binario compacto es un formato que ahorra espacio. JSON es, por supuesto, amigable para humanos y navegadores. Thrift también le ofrece una variedad de protocolos de transporte, incluidos TCP y HTTP. Es probable que el protocolo TCP sin formato sea más eficiente que el protocolo HTTP. Sin embargo, HTTP es compatible con firewalls, navegadores y humanos.
Formatos de mensajes
Ahora que hemos analizado HTTP y Thrift, examinemos la cuestión de los formatos de los mensajes. Si está utilizando un sistema de mensajería o REST, puede elegir el formato de su mensaje. Es posible que otros mecanismos de IPC, como Thrift, solo admitan una pequeña cantidad de formatos de mensajes, quizás solo uno. En cualquier caso, es importante utilizar un formato de mensaje en varios idiomas. Incluso si hoy escribes tus microservicios en un solo lenguaje, es probable que utilices otros lenguajes en el futuro.
Hay dos tipos principales de formatos de mensajes: texto y binario. Los ejemplos de formatos basados en texto incluyen JSON y XML. Una ventaja de estos formatos es que no sólo son legibles para los humanos, sino que también se describen por sí mismos. En JSON, los atributos de un objeto están representados por una colección de pares nombre-valor. De manera similar, en XML los atributos se representan mediante elementos y valores nombrados. Esto permite que el consumidor de un mensaje seleccione los valores que le interesan e ignore el resto. En consecuencia, cambios menores en el formato del mensaje pueden ser fácilmente compatibles con versiones anteriores.
La estructura de los documentos XML se especifica mediante un esquema XML . Con el tiempo, la comunidad de desarrolladores se ha dado cuenta de que JSON también necesita un mecanismo similar. Una opción es utilizar el esquema JSON , ya sea de forma independiente o como parte de un IDL como Swagger.
Una desventaja de utilizar un formato de mensajes basado en texto es que los mensajes tienden a ser extensos, especialmente XML. Dado que los mensajes son autodescriptivos, cada mensaje contiene el nombre de los atributos además de sus valores. Otro inconveniente es la sobrecarga que supone analizar el texto. Por lo tanto, es posible que quieras considerar el uso de un formato binario.
Hay varios formatos binarios para elegir. Si está utilizando Thrift RPC, puede utilizar Thrift binario. Si puede elegir el formato del mensaje, las opciones populares incluyen Protocol Buffers y Apache Avro . Ambos formatos proporcionan un IDL escrito para definir la estructura de sus mensajes. Sin embargo, una diferencia es que Protocol Buffers utiliza campos etiquetados, mientras que un consumidor de Avro necesita conocer el esquema para interpretar los mensajes. Como resultado, la evolución de la API es más fácil con Protocol Buffers que con Avro. Esta publicación de blog es una excelente comparación de Thrift, Protocol Buffers y Avro.
resumen
Los microservicios deben comunicarse utilizando un mecanismo de comunicación entre procesos. Al diseñar cómo se comunicarán sus servicios, debe considerar varias cuestiones: cómo interactúan los servicios, cómo especificar la API para cada servicio, cómo evolucionar las API y cómo manejar fallas parciales. Hay dos tipos de mecanismos de IPC que los microservicios pueden utilizar: mensajería asincrónica y solicitud/respuesta sincrónica. En el próximo artículo de la serie, analizaremos el problema del descubrimiento de servicios en una arquitectura de microservicios.
Editor – Esta serie de siete artículos ya está completa:
- Introducción a los microservicios
- Construyendo microservicios: Uso de una API Gateway
- Construyendo microservicios: Comunicación entre procesos en una arquitectura de microservicios (este artículo)
- Descubrimiento de servicios en una arquitectura de microservicios
- Gestión de datos basada en eventos para microservicios
- Elección de una estrategia de implementación de microservicios
- Refactorización de un monolito en microservicios
También puede descargar el conjunto completo de artículos, además de información sobre la implementación de microservicios utilizando NGINX Plus, como un libro electrónico: Microservicios: Desde el diseño hasta la implementación .
El bloguero invitado Chris Richardson es el fundador del CloudFoundry.com original, una de las primeras PaaS (plataforma como servicio) de Java para Amazon EC2. Ahora asesora a organizaciones para mejorar la forma en que desarrollan e implementan aplicaciones. También escribe periódicamente sobre microservicios en http://microservices.io .
"Esta publicación de blog puede hacer referencia a productos que ya no están disponibles o que ya no reciben soporte. Para obtener la información más actualizada sobre los productos y soluciones F5 NGINX disponibles, explore nuestra familia de productos NGINX . NGINX ahora es parte de F5. Todos los enlaces anteriores de NGINX.com redirigirán a contenido similar de NGINX en F5.com.