
This blog is first in a series of blogs that cover various aspects of what it took for us to build and operate our SaaS service:
- Control plane for distributed Kubernetes PaaS
- Global service mesh for distributed applications
- Platform security for distributed infrastructure, apps, and data
- Application and network security of distributed clusters
- Observability across a globally distributed platform
- Operations & SRE of a globally distributed platform
- Golang service framework for distributed microservices
As we described in our earlier blog, our customers are building complex and diverse sets of business solutions — like smart manufacturing, video forensics for public safety, algorithmic trading, telco 5G networks — and thus we need to deliver an always-on, connected, and reliable experience for these applications and their end-users.
Since these applications could be running in multiple clusters across cloud providers or customers’ edge locations, our platform team had to build a distributed control plane and a PaaS service to deploy, secure, and operate multiple multi-tenant Kubernetes clusters. This distributed control plane has delivered many operational, scaling, and performance benefits that we will cover in our presentation (video link) — e.g. how to manage thousands of edge K8s clusters with GitOps — and also as a separate blog post in the coming weeks.
TL;DR (Summary)
- We could not find a simple to use solution in the market that could solve the problem of deploying, securing, and operating multiple application clusters that are distributed across cloud providers, private clouds or multiple edge locations.
- We could not find a robust Kubernetes distribution or PaaS (eg. OpenShift, Cloud Foundry, etc) that provided a comprehensive set of security and operational services needed for distributed clusters — for example PKI-based identity, RBAC and user-access management, secrets and key management across cloud providers, multi-cluster service mesh, observability and audit logs, or application and network security.
- Anthos (Google), Azure Arc (Microsoft), and Rancher are multi-cluster management stations and packaging of multiple different services; our analysis was that these would not have solved the operational, scaling, security, and multi-tenancy requirements that we had for application and infrastructure services across multiple clusters.
- We had to build our own distributed control plane for our managed PaaS that is built on top of Kubernetes. We started with vanilla Kubernetes and then made significant changes to deliver platform services needed by our DevOps and SRE teams. In addition, we had to build a control plane to manage large numbers of distributed clusters and deliver multi-tenancy across heterogeneous infrastructure (in edge, our network, and multiple cloud providers).
Kubernetes for App Management: Why & How
We chose Kubernetes (K8s) to be the core of our platform for managing distributed applications as it provides a rich set of functionality without being overly prescriptive — giving us flexibility on innovating on things that we believe matter to our customers. We used this as a foundation on which to start building our service and with the growing popularity of K8s, it is also easier to find developers and operators who are familiar with it.
That said, deploying and managing a large number of production-grade Kubernetes clusters across a hybrid environment (multiple clouds, network POPs, and edge locations) is not very easy as there are no out-of-the-box solutions for Kubernetes that can:
- Harmonize heterogeneous infrastructure resources with automated clustering, scaling, and zero-touch provisioning; this was especially painful at the edge and in our network PoPs
- Provide high-performance and reliable connectivity across disparate locations — especially when crossing cloud providers and coming from edge locations
- Solve the security problem of data-in-transit, data-at-rest, secrets, keys and network…all backed by a uniform PKI identity that works across edge, network and cloud
- Provide true multi-tenancy — tenant isolation and security guarantees — with the ability to run production and development workloads for internal and customer needs on the same clusters
- Provide observability and operations across distributed clusters that ties into centralized policy and intent, without the need for building complex logs and metrics collection
After several proofs-of-concept with multiple cloud providers and open-source platforms like GKE, AKS, EKS, and RKE as well as OpenShift and Cloud Foundry — we realized that none of them could meet all of the five requirements above. As a result, we decided to build our own PaaS — starting with “vanilla” Kubernetes and made several additions — for identity, networking, security, multi-tenancy, logging, metrics, etc. While we use Kubernetes to meet our internal needs, we had to make some hard decisions like not exposing these Kubernetes clusters directly to our internal users and/or customers to run their workloads (more on that later, as multi-tenancy was a key objective for us).
In addition to multiple new features that we needed to add, there was also a need to run our workloads/services alongside customer workloads in many locations across the edge, our network, and public/private clouds. This meant that we had to build additional capabilities to manage multiple clusters in multiple environments…all connected using our global network and our distributed application gateways to provide zero-trust and application-level connectivity across these clusters.
The Hard Part: Multi-Tenancy and Multi-Cluster for Kubernetes
Building and operating applications running in a single Kubernetes cluster is a non-trivial task, even if consuming a cloud provider-managed cluster. This is why it is common for DevOps and SRE teams to minimize their overhead and not deal with the complexities of many clusters. It is quite common to see teams build one large Kubernetes cluster and put all types of resources within the same cluster. While this seems great because they can simplify operations and run the cluster for maximal compute efficiency and cost, this is not the best idea for several reasons. First, the needs for production workloads are very different from dev-test and from staging — unstable development workloads can potentially cause problems for more stable production workloads.
In addition to the needs of varied workloads, K8s security and isolation limitations is another driver for multi-cluster. A typical approach to solve for K8s security and resource isolation is to spin-up independent clusters for each tenant using a multi-tenant model. While this may be feasible to do in the cloud, it is not possible at the edge to run multiple clusters. Edge sites have compute and storage resource limitations and constrained network bandwidth to send logs and metrics for each additional cluster to the central cloud.
To deal with the problem of multiple Kubernetes clusters, we evaluated Rancher for centralized management of our Kubernetes clusters (when we started, Anthos and Azure Arc did not exist) and KubeFed. The two approaches available at that time were (and still the same situation today):
- Multi-cluster management (eg. Rancher) from a central console would have given us the ability to deploy multiple clusters in any location and perform lifecycle management operations like upgrades, rollback, etc. Some of these systems also gave the ability to address an individual cluster with automation for configuration and deployment of applications
- Another approach is to deploy a Kubernetes cluster federation (KubeFed) control plane and it can make multiple physical clusters look like one cluster. This project was just getting started at the time we looked and even today is only in alpha stage.
After the recent announcement of GCP Anthos and Azure Arc, we re-evaluated our original decision to build a distributed control plane and the conclusion was that even these two new offerings could not have solved two critical problems with distributed clusters. These two key capabilities that we needed for our platform were:
- Managing multiple clusters as-a-fleet to solve the problem of performing operations across all or a logical group of clusters — operations like configuration, deployment, metrics, etc. This is critical as we want to reduce operations overhead for our SRE teams, improve debug-ability for our DevOps, and improve the scalability of our system
- Ability to carve up an individual physical Kubernetes cluster for multi-tenancy without needing to spin up physical clusters — this is especially critical in resource-constrained environments where we don’t want to add new physical clusters just for multi-tenancy
To solve these two problems, we had to come up with a new technique — distributed control plane — to solve the operational overhead of “multiple” clusters and provide an equivalent of “multiple clusters” for multi-tenancy in resource-constrained environments.
Distributed Control Plane: How We Achieved Multi-Cluster Kubernetes
Our platform team decided to build a distributed control plane for Kubernetes that exposes Kubernetes APIs for our team’s use, however, these APIs are coming from “virtual” clusters that only exist in our control plane — a virtual K8s (vK8s) API server for a virtual K8s cluster (as shown in Figure 1). This control plane maps the intent of the user to multiple physical Kubernetes clusters running in our edge, our network POPs, and public cloud locations. These physical clusters are only accessible to our distributed control plane, and not to any individual tenant/user.

This control plane provides each tenant with one or more “virtual” application clusters where they can deploy their application(s) and based on configuration, the control plane will replicate and manage it across multiple physical Kubernetes clusters. In addition to configuration and deployment operations, monitoring operations also follows this “virtual” cluster without the need to build tooling to collect and dissect data from multiple physical clusters.
Let’s take a sample UI application called productpage, where user intent is to run it distributed across 3 locations — pa2-par, ny8-nyc and ams9-ams with 2 replicas in each of them. As the user creates a vK8s object and attaches it to a virtual cluster, which immediately provisions a vK8s API server that can be used with standard kubectl.
As the next step, the user downloads the kubeconfig for this virtual cluster and creates standard yaml to describe a K8s deployment for productpage.
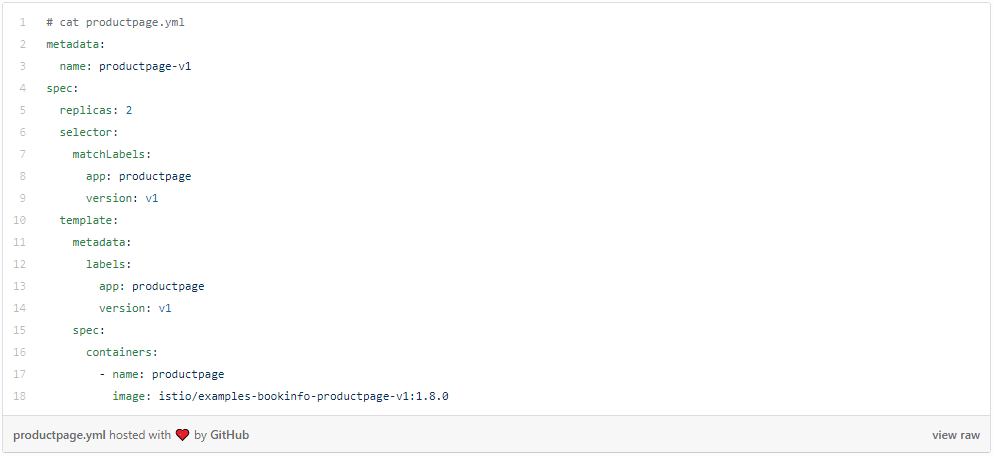
Following the creation of deployment spec, the user can proceed to create a deployment on this virtual cluster:

Now if the user checks his deployment he sees 6 replicas has been started with 2 in each location (pa2-par, ny8-nyc and ams9-ams).

The following output shows 2 pods running in each location with mapping to particular physical node
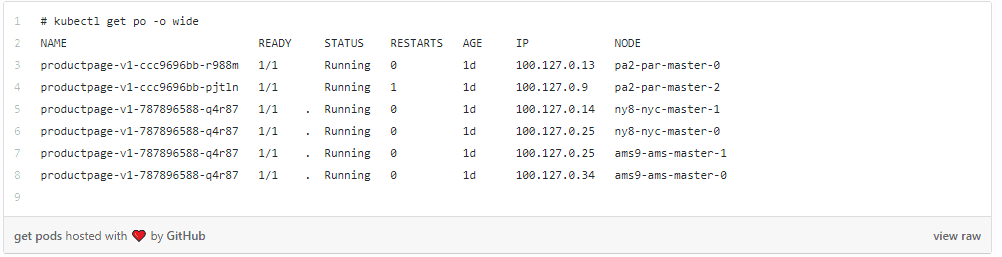
This simple example demonstrates how trivial it is to get multi-cluster replication of any app in minutes without any installation and management burden. In addition to mapping the intent, the distributed control plane also delivers observability for the virtual cluster and not on an individual cluster basis.
Distributed Control and Centralized Management for Multi-Tenancy
As you can see in Figure 2, our centralized management plane is running across two public cloud providers (one region each) — one in AWS and one in Azure (for redundancy). This management plane allows our SRE to create tenants with hard multi-tenancy — e.g. a development team working on our VoltMesh service can be a tenant and a customer solutions team working on customer POCs can be its own tenant with its own set of users.

Each of these tenants can create many namespaces and assign a group of users to collaborate on these namespaces. These namespaces are not Kubernetes namespaces — they are an isolation boundary in our platform with RBAC rules and IAM policies for users.
When a user within a namespace wants to create an application cluster, they create a vK8s object and that in-turn creates a vK8s API server in our management plane. Using this vK8s object, the user can create deployments, stateful sets, PVCs, etc and the control plane will ensure that these operations happen on one or many physical clusters, based on sites that are associated with the vK8s object.
Since each tenant and user is using standard K8s operations without any modifications, it allows the system to be compatible with a number of tools that are popular with operators — e.g. Spinnaker, Helm, Jenkins, etc.
Gains Realized from a Distributed Control Plane
The big advantage of a distributed control plane is that it has solved the operational overhead for our SRE and DevOps teams. They can now perform operations (configuration, deployment, monitoring, policy, etc) across a virtual cluster and the control plane will automatically map it across multiple physical clusters. In addition to operational simplification for multiple clusters, the control plane has also solved the security and isolation problem for multi-tenancy.
This distributed control plane has also improved the productivity of developers that want to add new features to our platform — they don’t have to build new automation every time they add new features that impact configuration or operations across multiple clusters. They use the intent-based configuration model and the control plane knows what needs to be done. In addition, they can continue to interact with this distributed and multiple cluster object — virtual kubernetes — using kubectl and not yet another CLI.
After running this in our dev-test, staging, and production environments for more than a year now, we realized that this globally distributed control plane (running in our network POPs) also provides significant scale, performance and reliability advantages — something that we had not completely imagined during our early days. We will cover this finding in our upcoming KubeCon presentation and as a separate blog post in the coming weeks.
To be continued…
This series of blogs will cover various aspects of what it took for us to build and operate our globally-distributed SaaS service with many application clusters in the public cloud, our private network PoPs, and edge sites. Next up is Global Service Mesh for Distributed Apps…
About the Author
Related Blog Posts

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

F5 joins the Dell AI Ecosystem Program to help enterprises operationalize AI
F5 joins the Dell AI Ecosystem Program to help enterprises deploy production AI with greater performance, security, and control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.