
For years, network segmentation has been the linchpin that facilitates threat isolation, quality of service differentiation, incident response and analysis, compliance auditing, and many other key interoperability functions. Yet, as we extol zero trust principles and, in a rush, to deploy AI, have we neglected this core element of network infrastructure that serves as the bedrock for modern cybersecurity and service operations?
Earlier in our AI factory series, we defined an AI factory as a massive storage, networking, and computing investment serving high-volume, high-performance training and inference requirements. To realize the return on this investment, AI factories dynamically schedule the use of high-value graphics processing units (GPUs) and compute to perform this training and inference. Scheduling GPUs requires architecting multiple “tenants” of AI services per AI cluster. This raises an issue that many operations teams don’t see coming until it is often too late.
Aligning AI factory cluster resources with network segmentation
Within an AI cluster, we can logically segment resources with a tenant context, allowing for tenant quotas, resource consumption limits, host system security, and management role-based access control (RBAC). However, tenant contexts are not exposed with the basic network services providing AI cluster traffic ingress and egress with the rest of the AI factory network. Without this context, the bedrock of cybersecurity in the data center, network segmentation is blind. Typical methods to expose the necessary tenant contexts either significantly rob the AI factory of high-value compute or slow networking paths beneath required limits for service latency, bandwidth, or concurrency. We face false choices between efficiently utilizing high-value AI factory resources and proper tenant integration with the network.
In public cloud infrastructures, orchestrated multi-tenant network designs are the foundation of all services in a cloud region and implemented with virtual private clouds (VPC). This virtualized network segmentation is key for security and resource metering. Public cloud providers maintain this function with teams of network software developers and specialized networking hardware, including SmartNICs and data processing units (DPUs). AI factory clusters in public clouds are designed to take advantage of the underlying infrastructure VPC network orchestration. The cost to maintain VPCs is quite substantial, but it is core to the public cloud business model.
The question arises: How does an organization maximize its AI factory investment and dynamically schedule GPUs and compute without the same level of investment as a public cloud provider?
The industry’s first stop along this journey was to use server virtualization to create virtual machines (VMs). VMs utilize hardware pass-through to connect to segmented data center networks. Simply place all the virtual machines on the same VLANs, and we continue with operations as normal if we are only concerned about a single tenant in a single AI cluster.
VMs can also address GPU segmenting as GPU vendors support ways to subdivide GPU devices into sets of cores and memory, and then assign to specific virtual machines. However, segmenting GPU devices is not dynamic and requires a restart of the VM. Additionally, this design limits the ability to create a pool of GPU resources that can be metered across many tenants. These are significant drawbacks to this solution.
Aligning network segmentation with multi-tenant AI factory clusters
What happens to our AI factory clusters when they can no longer serve one tenant? The problem shifts to the data center. In AI factory clusters, by default, all network traffic egressing into the data center gets source network address translated (SNATed) to an individual cluster node IP address that the containerized workload that issues the network request happens to be running, effectively masking the true source. The traffic is then sourced from a network segment on which that node was deployed. For a multi-tenant cluster, this means we lose tenant context, and we get a mixed river of egress traffic from multiple tenants that’s impossible to sort out, secure, troubleshoot, or audit.
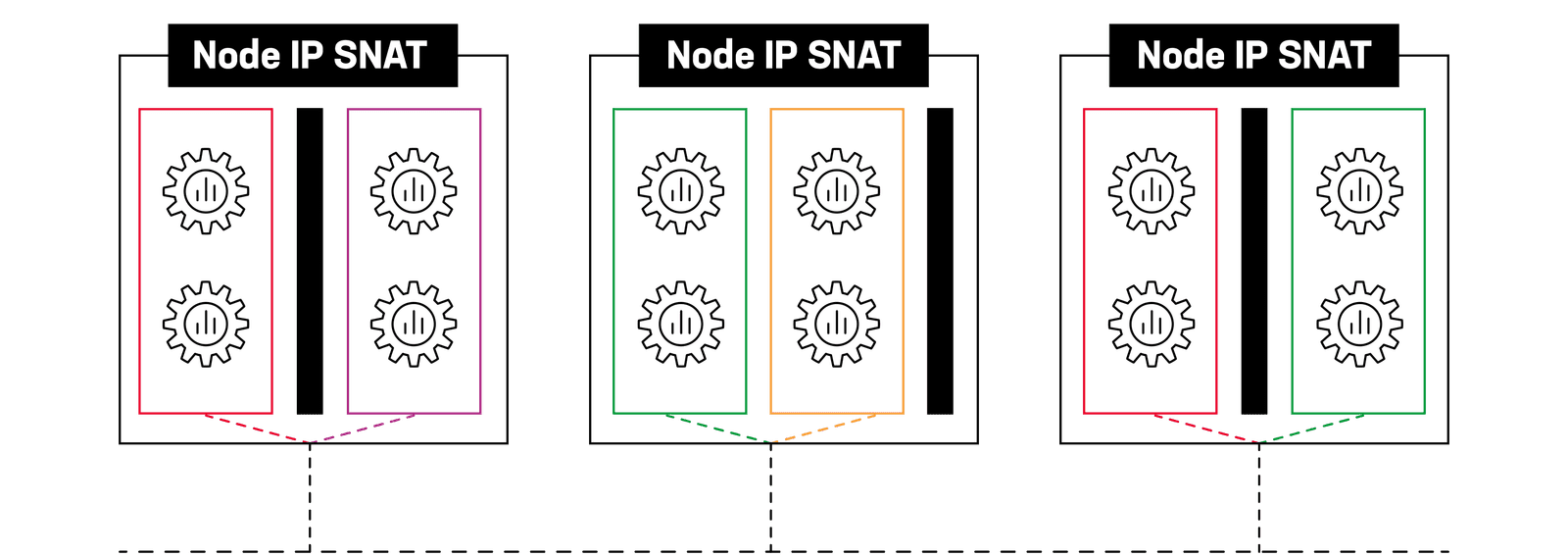
By default, cluster tenant context is lost on egress.
This problem is intensified when ingress traffic is included. While ingress traffic might be easier to manage as it is directed from an already segmented data center, how does one correlate a single tenant’s ingress traffic to its egress traffic? The answer revolves around retrieval-augmented generation (RAG) and agentic services, which communicate heavily to acquire outside data and utilize outside services. This becomes a cross-team effort with platform engineers and NetOps identifying an issue for a customer or attempting to pass security audits.
Enterprises may ask, “Why can’t we just use software-defined networking (SDN) overlay technology, and build out VPC networks like hyperscalers do?” This is certainly possible, but shifts the costs to maintaining SDN VPC networks over existing data center infrastructure. If Layer 2 (e.g., VxLAN) segmentation is desired, the orchestration of tunnels with top of rack switching and provisioning of those switches to match network segmentation becomes the problem. This is why hyperscalers chose SmartNICs and shifted to host-to-host level orchestration, leaving data center networks fast and unintelligent.
Most organizations don’t have the network programming talent or desire to own such complex host level orchestration, or they simply can’t lose the backbone networking visibility required for quality of service. Proposed routing solutions, Layer 3 (e.g., IP), to these problems have led network teams down the path of making every single AI cluster node a dynamic routing (BGP) peer to the data center with multiple route-reflectors trying to provide basic IP subnet tenancy. This, too, exposes operators to very complex routing issues and security audits and has resulted in regionwide outages.
Cluster aware orchestrated network segmentation for AI factories
AI factories must plan for a network feature rich, programable, secure, low latency solution that is scalable in both bandwidth and concurrency. Tenant contexts at Layer 2 (e.g., VLANs, VxLAN) and Layer 3 (e.g., Subnets, IPSEC interfaces) must be presented from within a cluster out to the AI factory network. Observability metrics, logs, and debugging tools must be available to NetOps.
Traditionally, many of these application tenancy and visibility solutions are provided by F5 BIG-IP. F5 BIG-IP Container Ingress Services (CIS) dynamically discovers Kubernetes services and exposes them to data centers as virtual servers, a configuration object BIG-IP administrators will be familiar with from configuring them to present physical servers and virtual machines. While BIG-IP does provide much of the requirements we are looking for in a solution, it does not manage egress traffic from the AI cluster into the AI factory network, which is needed for maintaining segmentation.
To address this issue, we designed F5 BIG-IP Next for Kubernetes, a solution for multi-tenant compute clusters built on top of our next-generation platform BIG-IP Next.
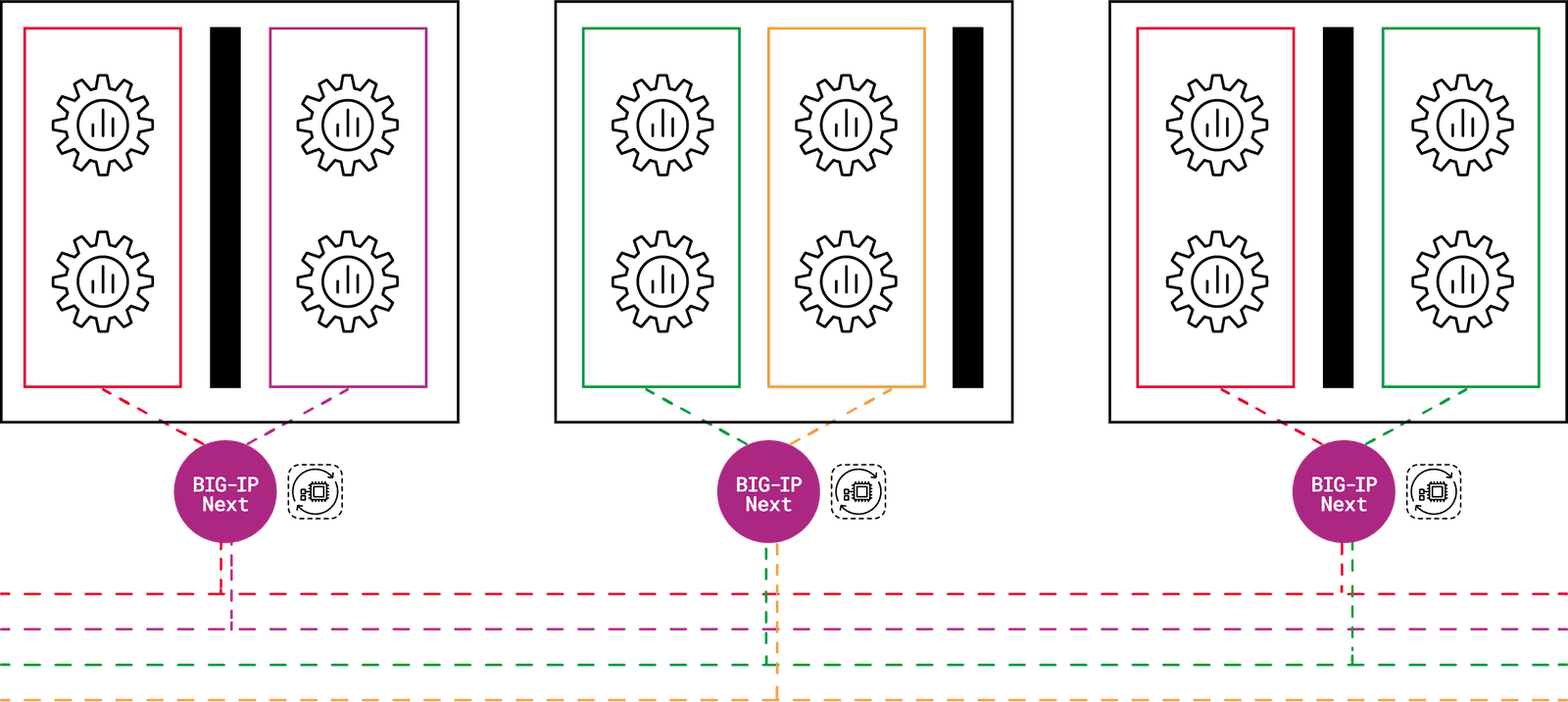
BIG-IP Next for Kubernetes enables NetOps to associate cluster tenants to network segments.
BIG-IP Next for Kubernetes is completely managed through the Kubernetes control plane and supports Kubernetes management authentication, RBAC for all declared resources, recognizes Kubernetes tenancy through namespaces to support the required network segmentation for both ingress and egress traffic. This is key for orchestration-first architectures like AI factories.
BIG-IP Next for Kubernetes provides a simplified way for NetOps to declare the mappings between Kubernetes namespaces and network segments. Dynamic route peering between the AI factory network and BIG-IP Next instances uses familiar route configuration syntax. NetOps teams have the unique ability to securely troubleshoot live network streams for cluster ingress and egress. SecOps teams gain per cluster tenant ingress and egress firewall access control lists (ACLs), distributed denial-of-service (DDoS), and IPS capabilities.
For the platform engineering teams, BIG-IP Next for Kubernetes unburdens compute resources by offloading network functions such as data ingress and egress traffic processing as well as Source NAT and firewalling. This helps with operational costs, while keeping services available and efficient.
BIG-IP Next for Kubernetes also supports Kubernetes Gateway API, the first community ingress API modeled for specific organizational roles in NetOps, platform engineering, DevOps, and MLOps. Through the Gateway API, BIG-IP Next for Kubernetes extends typical Layer 4 port based or Layer 7 HTTP(S) route ingress services to a suite for DevOps/MLOps, namely TCPRoute, UDPRoute, HTTPRoute, TLSRoute, and GRPCRoute—all of which are controlled through the same CI/CD automation in major AI frameworks.
From a management perspective, BIG-IP Next for Kubernetes keeps NetOps, SecOps, platform engineering, DevOps, and MLOps all working together effectively through Kubernetes API declarations. It is everything you expect from BIG-IP, but through the Kubernetes lens while supporting network segmentation.
The rise of the DPU
Data processing units (DPU) have gained exponential traction within AI factories. Defined in an earlier blog post within our AI factory series, a DPU is a programmable processor designed to handle vast data movement and processing via hardware acceleration at network line rate. Through product innovation at F5 and collaboration with NVIDIA, we released BIG-IP Next for Kubernetes to offload data flows for ingress and egress traffic while supporting network segmentation, as well as security functions by deploying to the NVIDIA BlueField-3 DPUs using NVIDIA’s DOCA APIs. This maximizes the investment in an AI factory by ensuring AI clusters are “data fed.”
AI factories powered by F5
When investing in AI factories, ensuring the infrastructure is optimized, efficient, and scalable is non-negotiable. F5 BIG-IP Next for Kubernetes deployed on NVIDIA BlueField-3 DPUs provides the network segmentation required for dynamic GPU and compute scheduling while delivering high-performance scalability to maximize the return on AI investments. To learn more, contact F5 to connect with your F5 account manager and solutions engineer or architect.
Interested in learning more about AI factories? Explore others within our AI factory blog series:
- What is an AI Factory? ›
- Retrieval-Augmented Generation (RAG) for AI Factories ›
- Optimize Traffic Management for AI Factory Data Ingest ›
- Optimally Connecting Edge Data Sources to AI Factories ›
- Multicloud Scalability and Flexibility Support AI Factories ›
- The Power and Meaning of the NVIDIA BlueField DPU for AI Factories ›
- API Protection for AI Factories: The First Step to AI Security ›
- AI Factories Produce the Most Modern of Modern Apps: AI Apps ›
About the Author

Related Blog Posts

A new path to technical excellence for F5 partners
Introducing F5 Partner Foundations, a structured learning curriculum to build F5 partner engineer expertise with a clear pathway to specialization.

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.