
Zero trust is a popular topic in cybersecurity circles these days, but I still receive odd looks whenever I bring up the concept of assume breach as a key part of the zero trust mindset. I assume the reason for this reaction stems from one of two possible concerns. First some security practitioners may interpret this as a terribly pessimistic view of the world; their internalization of “assume breach” being along the lines of, “So, you’re saying we’re all doomed. Well then, let’s just throw our hands up and stop even trying.” Others, perhaps the more prideful ones, may have an attitude of, “Well, your stuff might get breached, but my security is rock solid, and there’s no way the bad guys will get in past my defenses.”
My intent is neither of these extremes, but rather an emphasis on internalizing the reality of operating in a digital world, namely that breaches will occur, and therefore can, and should, be factored into any security system’s design. This is not a novel concept, and we should take inspiration from the wisdom gleaned from generations of artisans and trade workers that have embraced this.

Plumbers, electricians, and other professionals who operate in the physical world have long internalized the true essence of “assume breach.” Because they are tasked with creating solutions that must be robust in tangible environments, they implicitly accept and incorporate the simple fact that failures occur within the scope of their work. They also understand that failures are not an indictment of their skills, nor a reason to forgo their services. Rather, it is only the most skilled who, understanding that their creations will eventually fail, incorporate learnings from past failures and are able to anticipate likely future failures.
I recently dealt with such a failure; a sewage line in my house became clogged in the middle of a drainage path. The house is more than 30 years old, so a failure—a breach—should not be a surprise. After all, the likelihood of breach for any system over an extended period of time approaches 100%.
That’s the point. Anticipating a failure over time is just as true for an application security solution as it is for my plumbing system. Further, assuming “my plumbing system will never fail” is no more appropriate as a household maintenance strategy than “my cyber defenses will never be breached.”
Therefore, the plumber’s—and the cybersecurity practitioner’s—mindset should encompass how to deal with the failure, i.e., the breach, that will eventually occur.
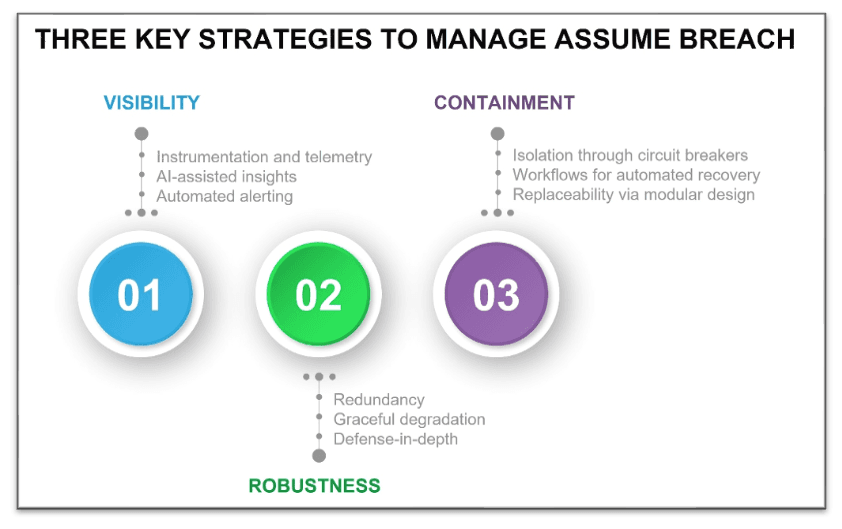
Three Key Strategic Components of Assume Breach
An effective strategy for dealing with failure of systems—physical or cyber—usually has three components.
- Visibility. Ensure sufficient visibility to enable detection of a failure as soon as possible. A plumbing leak in a bathroom drain, left unchecked, will result in rot and mildew or mold in the subfloor beneath, which may take months or years to be noticed. Or one might notice water dripping from the ceiling of the space under a second story bathroom after an underfloor water pan has overflowed and the drywall has saturated. In either of these scenarios, the first detection of the problem is some time after the initial failure and after additional secondary damage has occurred. The first tenet of assuming failure/breach must be to provide clear indicators of possible compromise as soon after the failure as possible, ideally even providing active notification for likely failures. For example, basements that rely on sump pumps for water removal typically have sensors that alarm when the water level exceeds a preset threshold. In other situations, where proactive alerting is not feasible for all likely failure modes, routine maintenance checks are performed—for example, inspection of water heaters on a semi-annual basis. In cybersecurity, this means the application security architecture must include a considered and tested telemetry strategy that factors in the most important failure modes that provides timely visibility into any possible breaches. In practice, telemetry should be streamed to analysis and notifications tools using AISecOps practices, and also simultaneously persisted into data stores for later use. AI and alerting tools should be used to improve efficacy and provide context to humans and ensure a timely response. Persisted data should be used to learn from and help inform additional robustness going forward.
- Robustness. Solutions must include the means to bypass or reduce the duration of a failure. The patterns common for robustness in this context are (a) graceful degradation or (b) redundancy, with the choice depending on the viability of operating with a degraded component. Some systems like hot water heaters can have both. For example, my water heater uses a pump-fed recirculation system to always have hot water primed for use. But if the pump fails, I will still get hot water, but will need to wait a bit longer for it. On the other hand, the failure of a heating coil sensor—where the heating element does not shut off—can lead to a catastrophic failure, so redundancy, in the form of a pressure relief valve, is used. Robustness should be considered at multiple system scopes. For example, at the scope of just the drain line, a plumber working on a commercial-grade solution might install a pair of redundant disposal lines, so the failure of either line would not render the drain unusable. On the other hand, an architect operating the system level of abstraction could design redundancy at the system level, such as adding a second sink or toilet nearby, which would also have the benefit of addressing more failure modes than only clogged drain lines. Certainly, redundancy is a common practice in cybersecurity, as many security devices are deployed in either active/standby (full redundancy) or active/active (graceful degradation) mode. However, the cybersecurity world differs a bit from the physical one. First, the fact that the cybersecurity world has active attackers, with intent and intelligence, means that failures rarely result from natural causes. A second more significant difference is that of scale. Because software is virtual, not physical, it follows the “write once, deploy many” paradigm. While this is a wonderful property for scaling, it also implies that a code vulnerability in a core software component will likely affect all the instances of that code in the system. As such the cybersecurity solution for robustness is based also on avoiding single points—and single classes of elements—of failure; a strategy sometimes referred to as “defense-in-depth.” Multi-factor authentication is a great example of this idea in practice. The failure mode (the means to compromise) for each factor is different, and the compromise of either factor alone will not compromise the system overall.
- Containment. It is critical to restrict the impact—the blast zone—of a failure. Just as we accept that failures, or breaches, will occur, we must also accept that we will not be able to entirely avoid single points of failure or build in redundancy for each functional requirement. Consequently, the architect should also consider how to minimize the impact of a failure, using both effort and consequence as two important metrics of goodness. For example, a plumber may add strategically located cleanout ports to drainage lines to reduce time to remediate. For more catastrophic failures, a contractor might choose PVC over galvanized drain lines to make it easier to patch a leak in the line, reducing effort for remediation. A common household plumbing practice is the inclusion of shutoff valves to limit the consequence of a (detected) failure, thus preventing secondary damage to vanities and floors. In the cybersecurity world, the analogous concepts are isolation, maintainability, and modularity. Isolation is about minimizing collateral damage or stopping the bleeding; a good practice is to have infrastructure that can act as a circuit breaker, using technologies such as microsegmentation. Maintainability means that, where possible, enabling a quick, low-effort path from compromised back to non-compromised; for example, a restart of a workload compromised to memory overflow attacks could be an effective (albeit incomplete) mitigation method. Modularity is the practice of building systems that allow comparable functional components to be swapped easily, so that in cases where maintenance is not possible or sufficient, the effort required for remediation is minimized.
These are some of the best practices I have learned around dealing with breaches, though I certainly don’t claim that there aren’t others. What matters more is that the developers and security professionals tasked with protecting applications understand that escapes will occur, and breaches will inevitably happen. In that light, how we plan for and deal with those failures is just as important and deserves as much deliberate thought as what we do to minimize the frequency of those failures.
Ultimately, we will be judged not only by how often breaches occur, but also how well we react to those breaches when they inevitably do occur.
About the Author
Related Blog Posts

Multicloud chaos ends at the Equinix Edge with F5 Distributed Cloud CE
Simplify multicloud security with Equinix and F5 Distributed Cloud CE. Centralize your perimeter, reduce costs, and enhance performance with edge-driven WAAP.

At the Intersection of Operational Data and Generative AI
Help your organization understand the impact of generative AI (GenAI) on its operational data practices, and learn how to better align GenAI technology adoption timelines with existing budgets, practices, and cultures.
Using AI for IT Automation Security
Learn how artificial intelligence and machine learning aid in mitigating cybersecurity threats to your IT automation processes.
Most Exciting Tech Trend in 2022: IT/OT Convergence
The line between operation and digital systems continues to blur as homes and businesses increase their reliance on connected devices, accelerating the convergence of IT and OT. While this trend of integration brings excitement, it also presents its own challenges and concerns to be considered.
Adaptive Applications are Data-Driven
There's a big difference between knowing something's wrong and knowing what to do about it. Only after monitoring the right elements can we discern the health of a user experience, deriving from the analysis of those measurements the relationships and patterns that can be inferred. Ultimately, the automation that will give rise to truly adaptive applications is based on measurements and our understanding of them.
Inserting App Services into Shifting App Architectures
Application architectures have evolved several times since the early days of computing, and it is no longer optimal to rely solely on a single, known data path to insert application services. Furthermore, because many of the emerging data paths are not as suitable for a proxy-based platform, we must look to the other potential points of insertion possible to scale and secure modern applications.