
Editor – This post is part of a 10-part series:
- Reduce Complexity with Production-Grade Kubernetes
- How to Improve Resilience in Kubernetes with Advanced Traffic Management
- How to Improve Visibility in Kubernetes
- Six Ways to Secure Kubernetes Using Traffic Management Tools
- A Guide to Choosing an Ingress Controller, Part 1: Identify Your Requirements
- A Guide to Choosing an Ingress Controller, Part 2: Risks and Future-Proofing
- A Guide to Choosing an Ingress Controller, Part 3: Open Source vs. Default vs. Commercial
- A Guide to Choosing an Ingress Controller, Part 4: NGINX Ingress Controller Options
- How to Choose a Service Mesh
- Performance Testing NGINX Ingress Controllers in a Dynamic Kubernetes Cloud Environment (this post)
You can also download the complete set of blogs as a free eBook – Taking Kubernetes from Test to Production.
As more and more enterprises run containerized apps in production, Kubernetes continues to solidify its position as the standard tool for container orchestration. At the same time, demand for cloud computing has been pulled forward by a couple of years because work-at-home initiatives prompted by the COVID‑19 pandemic have accelerated the growth of Internet traffic. Companies are working rapidly to upgrade their infrastructure because their customers are experiencing major network outages and overloads.
To achieve the required level of performance in cloud‑based microservices environments, you need rapid, fully dynamic software that harnesses the scalability and performance of the next‑generation hyperscale data centers. Many organizations that use Kubernetes to manage containers depend on an NGINX‑based Ingress controller to deliver their apps to users.
In this blog we report the results of our performance testing on three NGINX Ingress controllers in a realistic multi‑cloud environment, measuring latency of client connections across the Internet:
- The NGINX Ingress Controller maintained by the Kubernetes community and based on NGINX Open Source. As in previous blogs, we refer to it here as the community Ingress controller. We tested version 0.34.1 using an image pulled from the Google Container Registry.
- NGINX Ingress Controller based on NGINX Open Source, version 1.8.0 maintained by NGINX.
- NGINX Ingress Controller based on NGINX Plus, version 1.8.0 maintained by NGINX.
Testing Protocol and Metrics Collected
We used the load‑generation program wrk2 to emulate a client, making continuous requests over HTTPS during a defined period. The Ingress controller under test – the community Ingress controller, NGINX Ingress Controller based on NGINX Open Source, or NGINX Ingress Controller based on NGINX Plus – forwarded requests to backend applications deployed in Kubernetes Pods and returned the response generated by the applications to the client. We generated a steady flow of client traffic to stress‑test the Ingress controllers, and collected the following performance metrics:
- Latency – The amount of time between the client generating a request and receiving the response. We report the latencies in a percentile distribution. For example, if there are 100 samples from latency tests, the value at the 99th percentile is the next-to-slowest latency of responses across the 100 test runs.
- Connection timeouts – TCP connections that are silently dropped or discarded because the Ingress controller fails to respond to requests within a certain time.
- Read errors – Attempts to read on a connection that fail because a socket from the Ingress controller is closed.
- Connection errors – TCP connections between the client and the Ingress controller that are not established.
Topology
For all tests, we used the wrk2 utility running on a client machine in AWS to generate requests. The AWS client connected to the external IP address of the Ingress controller, which was deployed as a Kubernetes DaemonSet on GKE-node-1 in a Google Kubernetes Engine (GKE) environment. The Ingress controller was configured for SSL termination (referencing a Kubernetes Secret) and Layer 7 routing, and exposed via a Kubernetes Service of Type LoadBalancer. The backend application ran as a Kubernetes Deployment on GKE-node-2.
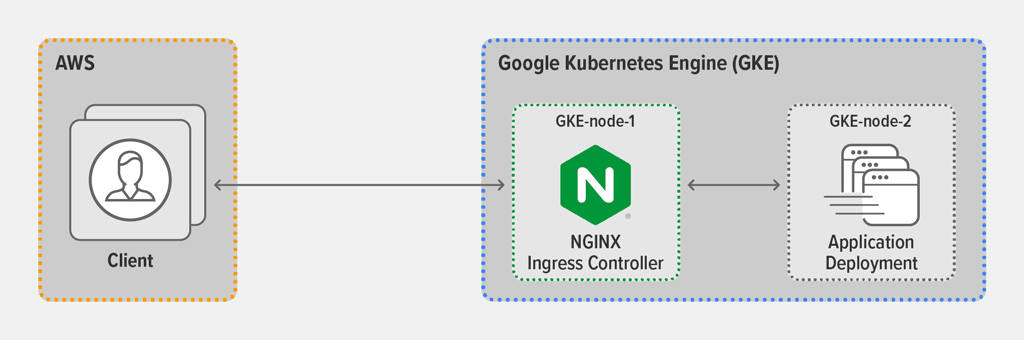
For full details about the cloud machine types and the software configurations, see the Appendix.
Testing Methodology
Client Deployment
We ran the following wrk2 (version 4.0.0) script on the AWS client machine. It spawns 2 wrk threads that together establish 1000 connections to the Ingress controller deployed in GKE. During each 3‑minute test run, the script generates 30,000 requests per second (RPS), which we consider a good simulation of the load on an Ingress controller in a production environment.
wrk -t2 -c1000 -d180s -L -R30000 https://app.example.com:443/where:
-t– Sets the number of threads (2)-c– Sets the number of TCP connections (1000)-d– Sets the duration of the test run in seconds (180, or 3 minutes)-L– Generates detailed latency percentile information for export to analysis tools-R– Sets the number of RPS (30,000)
For TLS encryption, we used RSA with a 2048‑bit key size and Perfect Forward Secrecy.
Each response from the back‑end application (accessed at https://app.example.com:443) consists of about 1 KB of basic server metadata, along with the 200 OK HTTP status code.
Back-End Application Deployment
We conducted test runs with both a static and dynamic deployment of the back‑end application.
In the static deployment, there were five Pod replicas, and no changes were applied using the Kubernetes API.
For the dynamic deployment, we used the following script to periodically scale the backend nginx deployment from five Pod replicas up to seven, and then back down to five. This emulates a dynamic Kubernetes environment and tests how effectively the Ingress controller adapts to endpoint changes.
while [ 1 -eq 1 ]
do
kubectl scale deployment nginx --replicas=5
sleep 12
kubectl scale deployment nginx --replicas=7
sleep 10
donePerformance Results
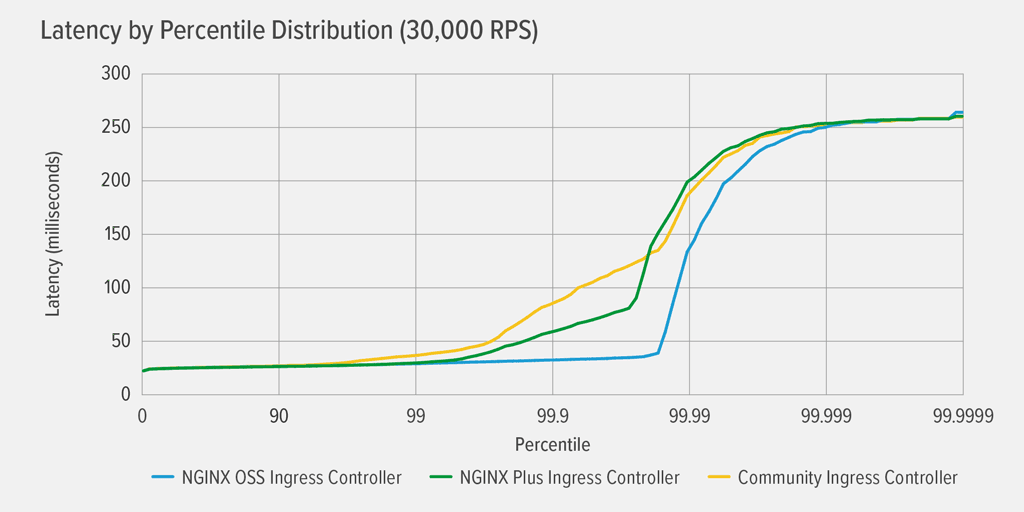
Latency Results for the Static Deployment
As indicated in the graph, all three Ingress controllers achieved similar performance with a static deployment of the back‑end application. This makes sense given that they are all based on NGINX Open Source and the static deployment doesn’t require reconfiguration from the Ingress controller.
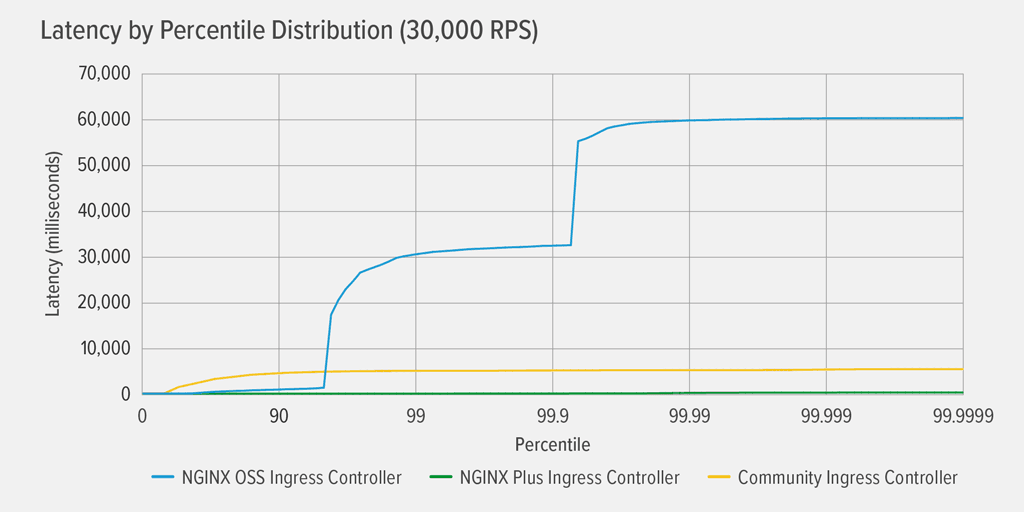
Latency Results for the Dynamic Deployment
The graph shows the latency incurred by each Ingress controller in a dynamic deployment where we periodically scaled the back‑end application from five replica Pods up to seven and back (see Back‑End Application Deployment for details).
It’s clear that only the NGINX Plus-based Ingress controller performs well in this environment, suffering virtually no latency all the way up to the 99.99th percentile. Both the community and NGINX Open Source‑based Ingress controllers experience noticeable latency at fairly low percentiles, though in a rather different pattern. For the community Ingress controller, latency climbs gently but steadily to the 99th percentile, where it levels off at about 5000ms (5 seconds). For the NGINX Open Source‑based Ingress controller, latency spikes dramatically to about 32 seconds by the 99th percentile, and again to 60 seconds by the 99.99th.
As we discuss further in Timeout and Error Results for the Dynamic Deployment, the latency experienced with the community and NGINX Open Source‑based Ingress controllers is caused by errors and timeouts that occur after the NGINX configuration is updated and reloaded in response to the changing endpoints for the back‑end application.
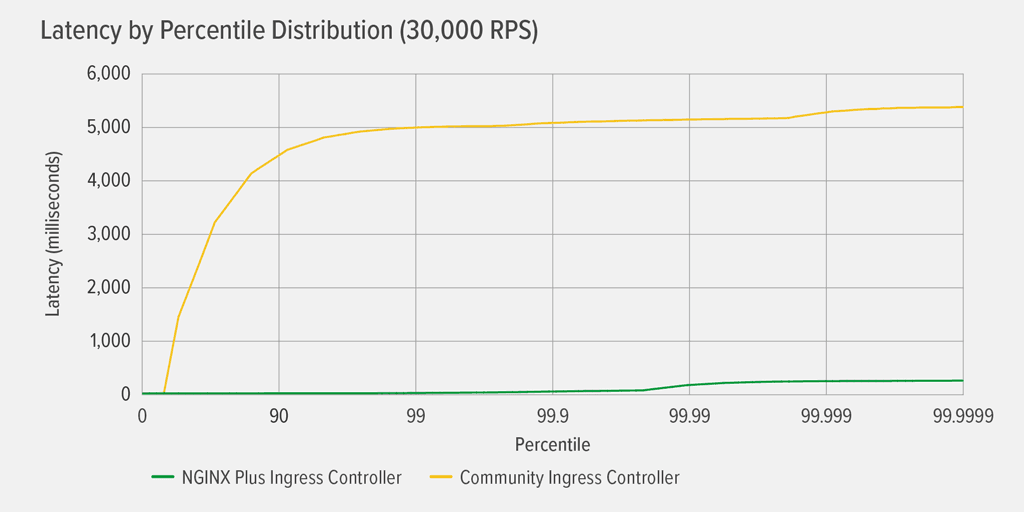
Here’s a finer‑grained view of the results for the community Ingress controller and the NGINX Plus-based Ingress controller in the same test condition as the previous graph. The NGINX Plus-based Ingress controller introduces virtually no latency until the 99.99th percentile, where it starts climbing towards 254ms at the 99.9999th percentile. The latency pattern for the community Ingress controller steadily grows to 5000ms latency at the 99th percentile, at which point latency levels off.
Timeout and Error Results for the Dynamic Deployment
This table shows the cause of the latency results in greater detail.
NGINX Open Source Community NGINX PlusConnection errors 33365 0 0Connection timeouts 309 8809 0Read errors 4650 0 0
With the NGINX Open Source‑based Ingress controller, the need to update and reload the NGINX configuration for every change to the back‑end application’s endpoints causes many connection errors, connection timeouts, and read errors. Connection/socket errors occur during the brief time it takes NGINX to reload, when clients try to connect to a socket that is no longer allocated to the NGINX process. Connection timeouts occur when clients have established a connection to the Ingress controller, but the backend endpoint is no longer available. Both errors and timeouts severely impact latency, with spikes to 32 seconds at the 99th percentile and again to 60 seconds by the 99.99th.
With the community Ingress controller, there were 8,809 connection timeouts due to the changes in endpoints as the back‑end application scaled up and down. The community Ingress controller uses Lua code to avoid configuration reloads when endpoints change. The results show that running a Lua handler inside NGINX to detect endpoint changes addresses some of the performance limitations of the NGINX Open Source‑based version, which result from its requirement to reload the configuration after each change to the endpoints. Nevertheless, connection timeouts still occur and result in significant latency at higher percentiles.
With the NGINX Plus-based Ingress controller there were no errors or timeouts – the dynamic environment had virtually no effect on performance. This is because it uses the NGINX Plus API to dynamically update the NGINX configuration when endpoints change. As mentioned, the highest latency was 254ms and it occurred only at the 99.9999 percentile.
Conclusion
The performance results show that to completely eliminate timeouts and errors in a dynamic Kubernetes cloud environment, the Ingress controller must dynamically adjust to changes in back‑end endpoints without event handlers or configuration reloads. Based on the results, we can say that the NGINX Plus API is the optimal solution for dynamically reconfiguring NGINX in a dynamic environment. In our tests only the NGINX Plus-based Ingress controller achieved the flawless performance in highly dynamic Kubernetes environments that you need to keep your users satisfied.
Appendix
Cloud Machine Specs
Machine Cloud Provider Machine TypeClient AWS m5a.4xlargeGKE-node-1 GCP e2-standard-32GKE-node-2 GCP e2-standard-32
Configuration for NGINX Open Source and NGINX Plus Ingress Controllers
Kubernetes Configuration
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx-ingress
namespace: nginx-ingress
spec:
selector:
matchLabels:
app: nginx-ingress
template:
metadata:
labels:
app: nginx-ingress
#annotations:
#prometheus.io/scrape: "true"
#prometheus.io/port: "9113"
spec:
serviceAccountName: nginx-ingress
nodeSelector:
kubernetes.io/hostname: gke-rawdata-cluster-default-pool-3ac53622-6nzr
hostNetwork: true
containers:
- image: gcr.io/nginx-demos/nap-ingress:edge
imagePullPolicy: Always
name: nginx-plus-ingress
ports:
- name: http
containerPort: 80
hostPort: 80
- name: https
containerPort: 443
hostPort: 443
- name: readiness-port
containerPort: 8081
#- name: prometheus
#containerPort: 9113
readinessProbe:
httpGet:
path: /nginx-ready
port: readiness-port
periodSeconds: 1
securityContext:
allowPrivilegeEscalation: true
runAsUser: 101 #nginx
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
env:
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
args:
- -nginx-plus
- -nginx-configmaps=$(POD_NAMESPACE)/nginx-config
- -default-server-tls-secret=$(POD_NAMESPACE)/default-server-secretNotes:
- This configuration is for NGINX Plus. References to
nginx‑pluswere adjusted as necessary in the configuration for NGINX Open Source. - NGINX App Protect is included in the image (
gcr.io/nginx-demos/nap-ingress:edge), but it was disabled (the-enable-app-protectflag was omitted).
ConfigMap
kind: ConfigMap
apiVersion: v1
metadata:
name: nginx-config
namespace: nginx-ingress
data:
worker-connections: "10000"
worker-rlimit-nofile: "10240"
keepalive: "100"
keepalive-requests: "100000000"Configuration for Community NGINX Ingress Controller
Kubernetes Configuration
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
helm.sh/chart: ingress-nginx-2.11.1
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/version: 0.34.1
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/component: controller
name: ingress-nginx-controller
namespace: ingress-nginx
spec:
selector:
matchLabels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/component: controller
template:
metadata:
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/component: controller
spec:
nodeSelector:
kubernetes.io/hostname: gke-rawdata-cluster-default-pool-3ac53622-6nzr
hostNetwork: true
containers:
- name: controller
image: us.gcr.io/k8s-artifacts-prod/ingress-nginx/controller:v0.34.1@sha256:0e072dddd1f7f8fc8909a2ca6f65e76c5f0d2fcfb8be47935ae3457e8bbceb20
imagePullPolicy: IfNotPresent
lifecycle:
preStop:
exec:
command:
- /wait-shutdown
args:
- /nginx-ingress-controller
- --election-id=ingress-controller-leader
- --ingress-class=nginx
- --configmap=$(POD_NAMESPACE)/ingress-nginx-controller
- --validating-webhook=:8443
- --validating-webhook-certificate=/usr/local/certificates/cert
- --validating-webhook-key=/usr/local/certificates/key
securityContext:
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
runAsUser: 101
allowPrivilegeEscalation: true
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
readinessProbe:
httpGet:
path: /healthz
port: 10254
scheme: HTTP
periodSeconds: 1
ports:
- name: http
containerPort: 80
protocol: TCP
- name: https
containerPort: 443
protocol: TCP
- name: webhook
containerPort: 8443
protocol: TCP
volumeMounts:
- name: webhook-cert
mountPath: /usr/local/certificates/
readOnly: true
serviceAccountName: ingress-nginx
terminationGracePeriodSeconds: 300
volumes:
- name: webhook-cert
secret:
secretName: ingress-nginx-admissionConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: ingress-nginx-controller
namespace: ingress-nginx
data:
max-worker-connections: "10000"
max-worker-open-files: "10204"
upstream-keepalive-connections: "100"
keep-alive-requests: "100000000"Configuration for Back-End App
Kubernetes Configuration
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
nodeSelector:
kubernetes.io/hostname: gke-rawdata-cluster-default-pool-3ac53622-t2dz
containers:
- name: nginx
image: nginx
ports:
- containerPort: 8080
volumeMounts:
- name: main-config-volume
mountPath: /etc/nginx
- name: app-config-volume
mountPath: /etc/nginx/conf.d
readinessProbe:
httpGet:
path: /healthz
port: 8080
periodSeconds: 3
volumes:
- name: main-config-volume
configMap:
name: main-conf
- name: app-config-volume
configMap:
name: app-conf
---ConfigMaps
apiVersion: v1
kind: ConfigMap
metadata:
name: main-conf
namespace: default
data:
nginx.conf: |+
user nginx;
worker_processes 16;
worker_rlimit_nofile 102400;
worker_cpu_affinity auto 1111111111111111;
error_log /var/log/nginx/error.log notice;
pid /var/run/nginx.pid;
events {
worker_connections 100000;
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
sendfile on;
tcp_nodelay on;
access_log off;
include /etc/nginx/conf.d/*.conf;
}
---
apiVersion: v1
kind: ConfigMap
metadata:
name: app-conf
namespace: default
data:
app.conf: "server {listen 8080;location / {default_type text/plain;expires -1;return 200 'Server address: $server_addr:$server_portnServer name:$hostnamenDate: $time_localnURI: $request_urinRequest ID: $request_idn';}location /healthz {return 200 'I am happy and healthy :)';}}"
---Service
apiVersion: v1
kind: Service
metadata:
name: app-svc
spec:
ports:
- port: 80
targetPort: 8080
protocol: TCP
name: http
selector:
app: nginx
---About the Author

Related Blog Posts

Automating Certificate Management in a Kubernetes Environment
Simplify cert management by providing unique, automatically renewed and updated certificates to your endpoints.

Secure Your API Gateway with NGINX App Protect WAF
As monoliths move to microservices, applications are developed faster than ever. Speed is necessary to stay competitive and APIs sit at the front of these rapid modernization efforts. But the popularity of APIs for application modernization has significant implications for app security.
How Do I Choose? API Gateway vs. Ingress Controller vs. Service Mesh
When you need an API gateway in Kubernetes, how do you choose among API gateway vs. Ingress controller vs. service mesh? We guide you through the decision, with sample scenarios for north-south and east-west API traffic, plus use cases where an API gateway is the right tool.
Deploying NGINX as an API Gateway, Part 2: Protecting Backend Services
In the second post in our API gateway series, Liam shows you how to batten down the hatches on your API services. You can use rate limiting, access restrictions, request size limits, and request body validation to frustrate illegitimate or overly burdensome requests.
New Joomla Exploit CVE-2015-8562
Read about the new zero day exploit in Joomla and see the NGINX configuration for how to apply a fix in NGINX or NGINX Plus.
Why Do I See “Welcome to nginx!” on My Favorite Website?
The ‘Welcome to NGINX!’ page is presented when NGINX web server software is installed on a computer but has not finished configuring