
The payoffs of a well-constructed data architecture go beyond operational process. The benefits extend into strategic operational efficiencies, deeper business insights, and the ability to reach adjacent business opportunities, all executed in a more agile manner.
The Food Delivery Application, revisited, 6 months later...
In a previous article, we introduced a hypothetical food ordering and delivery service, and presented several key day-to-day operation workflows: the customer ordering process, the pickup and food delivery workflow, and payment processing. We explored how an intentional data strategy around the key data inputs to the workflows result in more robust and agile-scalable business processes.
In this article, I would like to expand beyond day-to-day operational efficiency, and demonstrate the longer-term, more strategic benefits of data architecture design aforethought. Fast-forwarding our initial scenario by 6 months, assuming our application has been successful, business leaders have now identified some new and emerging opportunities. They are now asking the technologists how quickly and easily the underlying systems can adjust and adapt to some specific opportunities and related challenges:
- The service growth is accelerating, and the business would like to expand to additional cities.
- As part of the expansion, the service would like to enter the highly lucrative California market, which adds incremental data governance requirements.
- Delivery times have been creeping up, often as a result of unanticipated spikes in demand. Can the technology help with that issue?
- The company is facing competition from emerging startups, and some restaurants have talked about moving to a competing service. Can we demonstrate added value for our suppliers (restaurants) to help retain them?
The four example challenges listed can be decomposed into two broad categories:
One, tune and improve the efficiency of key day-to-day ("tactical") business processes.
Two, create new insights that generate longer-term ("strategic") value to the company directly or indirectly, via the company’s customers.
The first two new challenges—territory expansion and associated compliance requirements—are around tactical business processes, and therefore more operational in nature. The last two challenges are more strategic in nature.
Let’s first look at the tactical and operational concerns.
Operational Efficiency Improvements
With geographic expansion into additional cities, we may encounter a few different issues. One potential issue, for the delivery workflow, is that there might be a disambiguation issue with street addresses—the same address (e.g., “100 Main St.”) may exist in multiple cities. Another possible issue is that different cities may span time zones; if that was not considered, then a pickup at 6:00 p.m. MDT may be an hour late in delivery to a neighboring PDT city (at 6:30 p.m. PDT). The data architecture described in our previous article incorporated the idea of a "normalized"—globally unique—representation for data elements, addressing both potential issues, thus allowing the application to implicitly accommodate these additional requirements.
The second tactical concern is compliance with additional data governance requirements for the state of California. The full set of concerns around California’s Consumer Privacy Act (CCPA) is an entire set of articles on its own, but one aspect is around being able to collect all data for a customer, annotated with when it was collected, along with the data source. As previously discussed, building a data architecture framework that allows the primary data ingestion pipeline to add metadata annotations—such as timestamps—to be added allow additional data governance requirements to be met simply, and with minimal incremental effort.
Strategic Value
In addition to the business value generated by improvements to the company’s day-to-day, tactical workflows and processes, another benefit—arguably a more important one—is the strategic value of being able to both tilt the existing playing field and also open up new playing fields in which to participate.
Reimagining Operational Workflows for Adaptive Applications
One class of strategic benefit is the ability to "tilt the field" by changing the blueprint of key operational workflows. This goes beyond simply optimizing them, into reimagining them. A robust, forward-looking data architecture enables agile and efficient exploitation the key capabilities—aggregation and data analytics—required to address the aforementioned challenge of delivery time degradation caused by demand variability, using dynamic pricing.
More specifically, because of the forethought given to the data architecture, it:
- Persists the timestamp of each order and delivery, using a consistent syntax and semantics, even across multiple database tables
- Keeps a historical record of both pickup and delivery locations, again using a consistent syntax and semantics
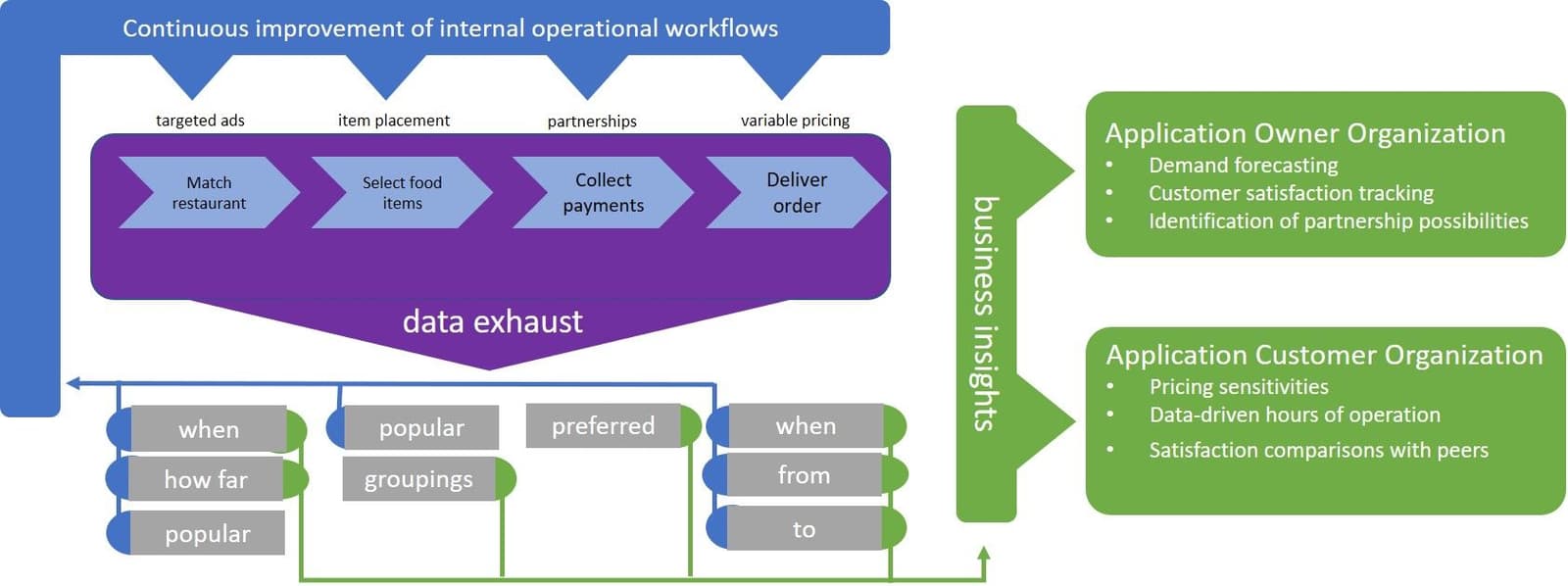
As a result, the data from two different workflows—ordering and delivery—can be correlated, categorized, and aggregated. In addition, the flexible metadata architecture can be leveraged to annotate the collated data with enriched contextual information for analysis. Consider the overall delivery latency—the time from the order is taken until the food is delivered. The latency can be computed by correlating across the ordering and delivery workflows. Additionally, because the geolocation data representation across the two workflows also uses consistent syntax and semantics, the delivery latency computations and correlations can be segregated by location, such as by zip code. Thus, by virtue of aforethought in the data strategy, we can more easily create a dataset of the overall delivery latency, at a per hour, per zip-code granularity. Finally, by taking advantage of our flexible metadata approach, the hourly statistics can be annotated with additional contextual information, such as traffic conditions and precipitation totals.
At this point, we have rich information to feed into an analytics pipeline, which can then use predictive AI methods to recognize patterns correlated with increased overall delivery time, and even anticipate such conditions in the future.
As a final step in this story, we can picture the business now reimagining the delivery workflow as a supply-and-demand problem, using pricing to match supply to demand. A specific example is to allow the delivery driver’s compensation to be adjusted by time and location, either via a fixed schedule, or dynamically, based on real-time conditions. This "closes-the-loop" in the data cycle, by leveraging data to take actionable steps (price adjustments) to address a business concern (managing overall delivery latency), and using closed loop feedback (dynamic price adjustments, depending on observed latency) to make the workflow be "adaptive."
Creating Directly Monetizable Business Value from Data
A different type of value from data is to use it to "open up new playing fields," creating business value which can be monetized via a direct benefit to customers. One example is mentioned in our 6-months later scenario: providing value to our supplier-side partners, the restaurants. A solution to the business need to provide insight for our application’s customers is to once again leverage data collected by our application’s operational workflows—this time as the raw material for extracting business insights for our customers & partners. These business insights can take various forms; some examples are:
- An early prediction of heavier than normal demand, so that the partner can prepare accordingly.
- Insights into their pricing of specific menu items, both to understand demand sensitivity, and to compare their pricing against the collection of their peer restaurants.
- Quantifiable inputs to assist the restaurant’s more strategic planning, such as the predicted revenue impact of increasing or shrinking their operating hours.
Discovery of these business insights is enabled not merely by the presence of a large data store, but the data strategy that annotates the collected data in a structured way, using a consistent metadata vocabulary.
Zooming into one specific business insight story, consider how menu pricing insights might be determined. Starting with the raw materials—the operationally collected data from the ordering workflow—the value of the metadata-annotated data strategy becomes readily apparent. Specifically, not only is the price of an item at a specific restaurant recorded, but related metadata is also kept. Consider the additional descriptive attributes of a food item, such as portion size, the food "type" (e.g., "soft drink" or "hamburger"), and special "enhancements" (e.g., "includes side dish" or "spicy"). If the data architecture decorates the food items data with metadata for these attributes, using a consistent metadata tag vocabulary (e.g., "portion ounces," "food class," "enhancements"), and a normalized set of metadata values, then the food items information can be compared across restaurants. For example, if all that is known from the code database is that the "Burger Basement" has a Man Cave Burger and the "Heart Attack Grill" has the Double Bypass Burger, there is no basis for a meaningful comparison. However, if we add a metadata annotation vocabulary, we can perform comparisons and analytics—the system would understand the two items are comparable because they are both of the "food class" of "hamburger." Additionally, the analytics can also the other metadata fields to normalize the portion size (i.e., the "Man Cave" may be 8 ounces and the "Double Bypass" may be 12 ounces). Finally, the use a standard space of "enhancement" values, such as "includes cheese" can also be used to do additional adjustments based on secondary similarities and/or differences. Once again, forethought given to the data architecture—this time around the metadata strategy—has allowed the business to quickly deliver on new business opportunities by simply leveraging the data exhaust of existing workflows.
Summary
Most business leaders are keenly aware that their success depends on planning their critical operational workflows, along with visibility into execution of those workflows. Good business leaders also understand that the ability to generate those insights quickly and efficiently, and to then take actions—both internally and externally facing—based on those insights is key to their continued success.
As technologists, we are asked to build solutions that enable those business goals of continuous operational efficiency improvement, and business agility. Sadly, the engineers too often focus on the data processing software elements of the solution, and not enough of the data architecture itself. This often results in significant effort, and time-to-deploy delays in the improvement of internal workflows and the rollout of new derivative customer offerings. As this article demonstrates, up-front attention paid to the data architecture—the data vocabulary, representations, and metadata strategy—is the technological foundation for an agile and robust data-driven business.
About the Author
Related Blog Posts

Multicloud chaos ends at the Equinix Edge with F5 Distributed Cloud CE
Simplify multicloud security with Equinix and F5 Distributed Cloud CE. Centralize your perimeter, reduce costs, and enhance performance with edge-driven WAAP.

At the Intersection of Operational Data and Generative AI
Help your organization understand the impact of generative AI (GenAI) on its operational data practices, and learn how to better align GenAI technology adoption timelines with existing budgets, practices, and cultures.
Using AI for IT Automation Security
Learn how artificial intelligence and machine learning aid in mitigating cybersecurity threats to your IT automation processes.
Most Exciting Tech Trend in 2022: IT/OT Convergence
The line between operation and digital systems continues to blur as homes and businesses increase their reliance on connected devices, accelerating the convergence of IT and OT. While this trend of integration brings excitement, it also presents its own challenges and concerns to be considered.
Adaptive Applications are Data-Driven
There's a big difference between knowing something's wrong and knowing what to do about it. Only after monitoring the right elements can we discern the health of a user experience, deriving from the analysis of those measurements the relationships and patterns that can be inferred. Ultimately, the automation that will give rise to truly adaptive applications is based on measurements and our understanding of them.
Inserting App Services into Shifting App Architectures
Application architectures have evolved several times since the early days of computing, and it is no longer optimal to rely solely on a single, known data path to insert application services. Furthermore, because many of the emerging data paths are not as suitable for a proxy-based platform, we must look to the other potential points of insertion possible to scale and secure modern applications.