
Every survey on generative AI—including our own—points to one inescapable conclusion: data immaturity is going to get in the way of fully realizing the potential of generative AI.
When we asked about challenges to AI adoption, the top response with 56% of respondents was “data immaturity.”
A quick look around the industry validates that data immaturity is a serious obstacle on the AI adoption path.
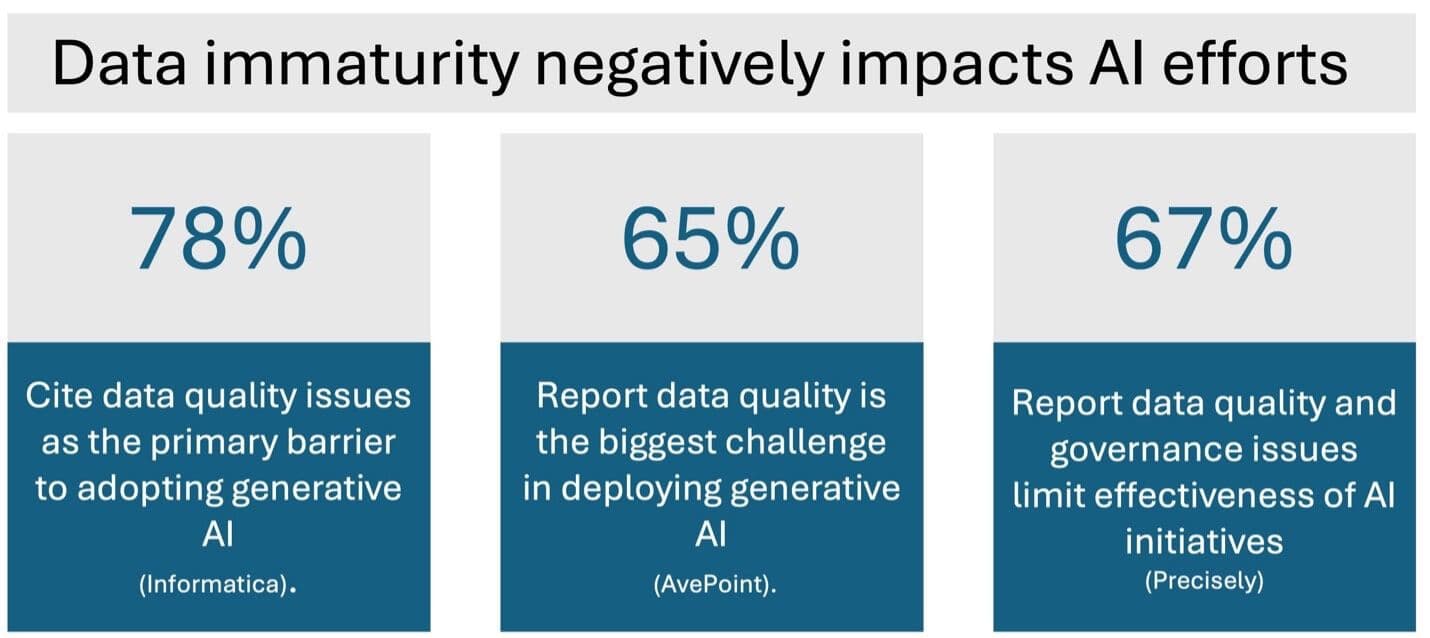
There is industry agreement that data immaturity is negatively impacting AI efforts.
What is data immaturity?
Data immaturity, in the context of AI, refers to an organization’s underdeveloped or inadequate data practices, which limit its ability to leverage AI effectively. It encompasses issues with data quality, accessibility, governance, and infrastructure such as:
- Poor data quality: Inconsistent, incomplete, or outdated data leads to unreliable AI outcomes.
- Limited data availability: Data silos across departments hinder access and comprehensive analysis, limiting insights.
- Weak data governance: Lack of policies on data ownership, compliance, and security introduces risks and restricts AI usage.
- Inadequate data infrastructure: Insufficient tools and infrastructure impede data processing and AI model training at scale.
- Unclear data strategy: Lack of a clear strategy results in uncoordinated initiatives and limited focus on valuable data for AI.
Data immaturity prevents organizations from harnessing the full potential of AI because high-quality, well-managed, and accessible data is foundational for developing reliable and effective AI systems. Organizations looking to overcome data immaturity often start by building a data strategy, implementing data governance policies, investing in data infrastructure, and enhancing data literacy across teams.
The impact on AI adoption
We went through all that to get to the real point of this post: data immaturity is a drag on AI adoption. Adoption is already slowing because organizations have, for the most part, already picked the low-hanging generative AI fruit (chatbots, assistants, co-pilots) and are running into data immaturity issues as they try to move toward the more valuable use cases such as workflow automation. Organizations that fail to prioritize data maturity will struggle to unlock these more advanced AI capabilities.
Data immaturity leads to a lack of trust in analysis and predictability of execution. That puts a damper on any plans to leverage AI in a more autonomous manner—whether for business or operational process automation. A 2023 study by MIT Sloan Management Review highlights that organizations with mature data management practices are 60% more likely to succeed in workflow automation than those with immature data practices. Data immaturity limits the predictive accuracy and reliability of AI, which are crucial for autonomous functions where decisions are made without human intervention.
Organizations must—and that’s the RFC MUST—get their data houses in order before they will be able to truly take advantage of AI’s potential to optimize workflows and free up valuable time for humans to focus on strategy and design, tasks for which most AI is not yet well suited.
Overcoming data immaturity
Addressing data immaturity is crucial for enabling advanced AI capabilities. Key steps include:
- Develop a clear data strategy
Align data collection, management, and quality standards with organizational goals to ensure data supports AI projects effectively. - Implement robust data governance
Establish policies for data ownership, compliance, security, and privacy to improve data quality and build trust in AI insights. - Invest in scalable data infrastructure
Adopt modern infrastructure, such as cloud storage and data pipelines, to support efficient processing and scalable AI training. - Enhance data quality standards
Set standards for data accuracy, consistency, and completeness, with regular monitoring and cleaning. - Promote data literacy and collaboration
Foster a culture of data literacy and teamwork between data and business units to improve data accessibility and impact.
By adopting these practices, organizations can establish a solid data foundation for AI, leading to optimized workflows, reduced risks, and more time for strategic tasks.
Data maturity is not just a technical necessity; it’s a strategic advantage that empowers organizations to unlock the full potential of AI. By overcoming data immaturity, organizations can transition from basic AI applications to more transformative, value-driven use cases, ultimately positioning themselves for long-term success in an AI-driven future.
To learn more, see our 2024 Digital Enterprise Maturity Index Report.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

Multicloud chaos ends at the Equinix Edge with F5 Distributed Cloud CE
Simplify multicloud security with Equinix and F5 Distributed Cloud CE. Centralize your perimeter, reduce costs, and enhance performance with edge-driven WAAP.

At the Intersection of Operational Data and Generative AI
Help your organization understand the impact of generative AI (GenAI) on its operational data practices, and learn how to better align GenAI technology adoption timelines with existing budgets, practices, and cultures.
Using AI for IT Automation Security
Learn how artificial intelligence and machine learning aid in mitigating cybersecurity threats to your IT automation processes.
Most Exciting Tech Trend in 2022: IT/OT Convergence
The line between operation and digital systems continues to blur as homes and businesses increase their reliance on connected devices, accelerating the convergence of IT and OT. While this trend of integration brings excitement, it also presents its own challenges and concerns to be considered.
Adaptive Applications are Data-Driven
There's a big difference between knowing something's wrong and knowing what to do about it. Only after monitoring the right elements can we discern the health of a user experience, deriving from the analysis of those measurements the relationships and patterns that can be inferred. Ultimately, the automation that will give rise to truly adaptive applications is based on measurements and our understanding of them.
Inserting App Services into Shifting App Architectures
Application architectures have evolved several times since the early days of computing, and it is no longer optimal to rely solely on a single, known data path to insert application services. Furthermore, because many of the emerging data paths are not as suitable for a proxy-based platform, we must look to the other potential points of insertion possible to scale and secure modern applications.