
You can hardly turn around these days without someone mentioning their DevOps-supporting toolchain. Everyone’s got one (yes, even us) and all of them are enabled by the (other) API economy. According to Wikipedia, a DevOps toolchain is: “a set or combination of tools that aid in the delivery, development, and management of applications throughout the software development lifecycle, as coordinated by an organization that uses DevOps practices.”

Now, that focuses mainly on the app, but there’s also the production side of the house – where software generally spends a good deal of its life (one hopes, at least). The same definition works for that, too, with the caveat that its focus (based on my perspective) is on the “provisioning, configuration, and management of network and app services throughout the app lifecycle, as coordinated by an organization that uses DevOps practices.” In the context of traditional DevOps, this focus expands the “release” phase in the cycle, and covers “release related activities” that include provisioning and deployment of software into production. That necessarily includes (or should include) the network and app services required to enable safe, secure application deliver to target users.
The thing is that no single vendor or open source project contains all the tools necessary to achieve the utopian dream of continuous deployment (that’s the production side of the house, by the way). In fact, some of the same tools used on the app dev side of the wall are used on the production side, as well. Increasingly, we see cross-over between the two worlds which is a good sign for “devops” in general, as it shows some normalization between what are traditional two very entrenched organizations with little in common but the app.
So you might use Puppet or Chef in combination with VMware and Cisco to automate a full stack of network and app services to support the need of an app for security, identity, and scale. You’ve created the applicable templates and scripts required to do that and verified they’re correct, perhaps using Postman and its scripting capabilities to test against virtual infrastructure in the lab. You’ve decided that git is a good choice as a repository for configuration artifacts because app dev already uses it and can provide guidance and maybe even hold a training session or two. And you might even go further and start building an app (or standing up an OpenStack implementation) to orchestrate the process and provide for self-service of individual services. You’re essentially defining the deployment toolchain.
And that’s where the Weakest Link Axiom starts rearing its ugly head. You’re familiar with the premise: a chain is only as as its weakest link. “Strong” is emphasized here because we can replace it with other characteristics like “reliable” or “secure” or “scalable” and the axiom remains as true. This is important because as you start to define the toolchain that will support continuous deployment, each “link” in that chain can become a point of failure, where security or scale or availability is compromised.
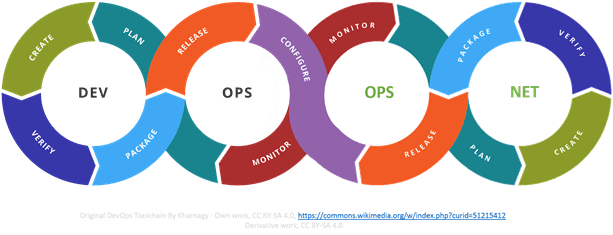
Just as planning, verification, and monitoring are critical links in the DevOps toolchain, so must they be in the NetOps toolchain. This is especially important for monitoring, where apps and infrastructure (network and app services) cross paths the most in production environments. It is through monitoring (visibility) that a comprehensive view of everything from business transactions to individual requests and responses can be understood in the event of a failure.
Configuration also necessarily joins the toolchains together, as the configuration of network and app services can be (and often is) peculiar to a given application.
While the packaging and release mechanisms may leverage similar tools, they are separate concerns that often display great disparity in terms of needs. Because network and app services may be deployed on shared infrastructure, tools that assume a single system approach may not be appropriate for NetOps. Conversely, the use of templates is increasingly common for quickly deploying standardized services in production, but are rarely applicable in DevOps, where applications display a high degree of uniqueness.
Regardless, both toolchains share a common thread – that of the weakness of one link infecting the entire chain. Even if you’re relying on mostly manual-driven deployments that take advantage of scripts, there is still a toolchain that represents the overall process of delivery and deployment. People can, and are, links in the toolchains that deliver and deploy software today. And it is the case that when a critical link is missing – because Bob is out with the latest flu – the process breaks down. The toolchain fails to deliver (or deploy).
It’s important as you continue to move ahead with your internal digital transformation that you recognize the importance of the DevOps and NetOps toolchains and don’t overlook any of the links that comprise it. Failure to pay attention to just one of the links as we make headway on the goal of continuous deployment will weaken the entire chain. As business comes more and more to rely on these interlinked chains, a weak link breaks more than just a process, it breaks the business, too.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

F5 joins the Dell AI Ecosystem Program to help enterprises operationalize AI
F5 joins the Dell AI Ecosystem Program to help enterprises deploy production AI with greater performance, security, and control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.