
Outages are expensive. Whether they’re ultimately the result of an attack or a failure in software or hardware isn’t that relevant. The costs per minute of downtime are increasing, thanks to the growing reliance on APIs and web apps of the modern, digital economy.
For some, those costs are staggering. It’s estimated that Amazon’s 40 minutes of downtime back in 2013cost them $2.64M. That’s $1100 per second for those disinclined to do the math. If you think that’s horrifying, consider Google, whose 5-minute downtime in the same year cost them $109K per minute (or $1816.67 per second) for a whopping total of $545K. For 5 minutes. Technically, if that was all they suffered, that’s the vaunted “5 9s” IT is tasked with achieving.
How often do outages happen? Too often, apparently. If you’ve never seen this one, take a gander at pingdom’s live outage map. It’s built from data culled from its over 700,000 global users. This morbidly fascinating map displays outages occurring in the past hour across the globe. The bright flashes depicting outages are a nice touch; really drives home the splash they make with users.
Which is to say an unwanted one.
The digital economy exacerbates this problem. Earlier this year an S3 outage at Amazon knocked out a whole spate of customers’ apps and web sites. But lest you pin this problem on public cloud providers, a quick dive into the site builtwith.com will quickly erase that belief. The percentages of sites taking advantage of CDNs and APIs is perhaps alarmingly high if you consider the dependency that incurs on someone else’s uptime. It’s hard to find a site that doesn’t rely on at least one external API or service, which increases the possibility of downtime because if that external service is down, so are you.
Basically, IT settled on “5 9s” because it is impossible to achieve 100% availability. The key today, when per second costs are skyrocketing thanks to the shift of the economy into the digital realm, is to minimize downtime. In other words, setting goals that require a low mean-time to resolution (MTTR), is just as critical – maybe more – than trying to eliminate downtime.
One of the key measures of “high performing organizations” in Puppet Labs’ 2016 State of DevOps Report is MTTR, defined as the time it takes to restore service when a service incident occurs (e.g. unplanned outage or service impairment). The highest performing organizations (based on the report’s assessment) take less than one hour while medium and low performing organizations take “less than one day”. “In other words” the report notes, “high performers had 24 times faster MTTR than low performers.”
You’ll note the question wasn’t “if” there is a service incident. It was “when” there is a service incident. The assumption is that an incident will occur, and thus the key is to minimize the time to resolution. A 2016 survey by IHS reported that “on average, survey respondents experience 5 downtime events per month, and 27 hours of downtime per month” cost the average mid-sized organization $1 and their larger counterparts up to $60M.
If we assume Murphy’s Law still presides over Moore and Conway, the answer is to try to minimize MTTR in order to reduce the time (and costs) associated with inevitable downtime.
That means visibility is critical, which means monitoring. Lots and lots of monitoring. But not just the website, or the web app, or the API – we need to monitor the full stack. From the network to the app services to the application itself. That’s something not everyone does, and when they do, they appear to do it inconsistently.
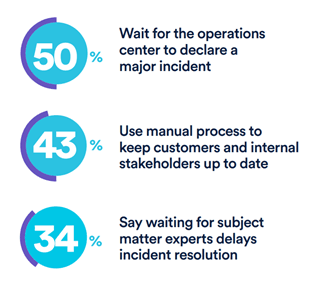
Consider the 2017 xMatters|Atlassian DevOps Maturity surveyin which 50% of respondents declared they “wait for operations to declare a major incident” before responding. A frightening 1/3 of companies “learn about service interruptions from their customers.”
In a digital economy, every second matters. Not just because it costs money but because it negatively impacts future revenues, as well. Decreasing brand value and trust with customers results in fewer purchases, users, and eventually stagnating growth. That’s not a direction organizations’ should going.
Monitoring is the first step to detecting issues that cause outages. But monitoring alone doesn’t help MTTR. Communication does. Alerting the relevant stakeholders as soon as possible and arming them with the information they need to troubleshoot the issue will assist in a faster time to resolution. That means sharing – one of the four key pillars of DevOps – is key to improving MTTR. Even if you aren’t embracing other aspects of DevOps at a corporate level yet, sharing is one you should consider elevating to a top level initiative. Whether it’s through ChatOps or e-mail, a mobile app or a dynamically updated wiki page, it’s imperative that the information gleaned through monitoring be shared widely across the organization.
A hiccup in a switch or server may seem innocuous, but left alone it might wind up knocking out half the services a critical app depends on. In the 2017 State of the Network study conducting by Viavi, 65% of network and systems administrators cite “determining whether problem is caused by network, system, or apps” as their number one challenge when troubleshooting application issues. Greater visibility and full-stack monitoring is one way to address this challenge, by ensuring that those responsible for finding the root cause have at hand as much information about the status and health of all components in the data path as possible.
Visibility is key to the future of IT. Without it, we can’t achieve the level of automation necessary to redress outages before they occur. Without visibility we can’t reduce MTTR in a meaningful way. Without it, we really can’t keep the business growing at a sustainable rate.
Visibility, like security, should be a first class citizen in the strategy stack driving IT forward. Because outages happen, and it is visibility that enables organizations to recover quickly and efficiently, with as little damage to their brand and bottom line as possible.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

A new path to technical excellence for F5 partners
Introducing F5 Partner Foundations, a structured learning curriculum to build F5 partner engineer expertise with a clear pathway to specialization.

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.