
Generative AI presents many opportunities within the context of operations and development but it also raises many challenges for those trying to incorporate generative AI in a security solution.
One such challenge is how to glean insights via LLMs (Large Language Models) on sensitive content not permitted to be shared with any third-party AI service, such as security policies used to protect applications and APIs against fraud and abuse.
A second challenge with LLMs is their tendency to hallucinate, especially when asked to analyze or generate content related to a subject on which the LLM has little knowledge. This is often the case for domain specific languages such as DEX. It is a purely functional, statically typed, and non-Turing-complete language that, while well-defined, is not widely used.
The first challenge, data privacy, initially sounds insurmountable. Security companies must take the privacy and security of all customer data—including policies—very seriously. Thus, though the use of an LLM to help uncover insights in policies would benefit both operational practices as well as customers, a solution is needed that can glean insights from the sensitive data without sharing this data with a third-party LLM, making it impossible for the LLM to process it. The second challenge (hallucinations) is one the entire industry is currently struggling to overcome, especially as it relates to answers regarding policies, configurations, and code.
While humans will see a program as a sequence of characters, the compiler sees things differently. To the compiler a DEX program is a type of data structure called an AST (Abstract Syntax Tree). This tree is a directed acyclic graph which means policies in question are well-suited to representation as a graph. Thus, the solution we found leverages a graph database (Neo4j) and employs a GPT agent to generate GraphQL queries against it. This approach neatly addresses the first challenge because we can use GraphQL to query a graph database containing the data while protecting its privacy from the third-party LLM.
The second challenge—hallucinations—is more difficult to overcome, but our approach also works here using multiple AI techniques to mitigate the risk. Furthermore, GraphQL is a widely used, well-documented query language with which most GPT models are familiar, and which can easily be syntactically verified using any number of tools. This reduces the likelihood of a hallucination and provides a way to ensure correctness before use.
What are AI Hallucinations?
AI hallucinations refer to instances where a generative AI produces output not based on actual data or patterns but is instead fabricated or distorted. These hallucinations often occur due to limitations or biases in the AI's training data, or when the AI is attempting to generate output for situations it hasn't encountered before. Hallucinations can manifest as fabricated or nonsensical content or conclusions that may not make logical sense or may not be true to the input data. For example, a text-generating AI might produce sentences that seem plausible but are ultimately nonsensical or unrelated to the provided context.
What is GraphQL?
GraphQL is an open-source query language for APIs (Application Programming Interfaces) and a server-side runtime for executing those queries by using a type system defined for data. It was developed by Meta (Facebook) and is designed to provide a more efficient, powerful, and flexible alternative to traditional RESTful APIs. GraphQL APIs are defined by a schema which specifies the types of data that can be queried or mutated. This strong typing enables better tooling, introspection, and validation.
Our Approach
Our approach to safely incorporating generative AI into security takes the form of a GPT agent. While the use of a well-documented language helps reduce the risk of a hallucination, we needed to find a way to limit the output space of our agent into a format that can be programmatically checked for errors while also not sending any sensitive data to OpenAI. Using GraphQL as the output space works well here as it is expressive enough to answer most questions while also being an abstraction that can be programmatically checked against a known schema.
While we have applied this approach to DEX, it will work for any sufficiently interconnected and relational data set such as: social networks, networks and infrastructure topologies, supply chains, and geospatial (mapping) data.

The PC-graph architecture consists of components to transform DEX into a graph representation. The resulting graph data is then stored in a Neo4j database. Output from a GPT agent can be submitted via API to a GraphQL Apollo server, which executes the query against the graph database.
Our agent uses GPT4 to respond to requests in natural language for information about policies written in DEX. The agent achieves this by understanding the pc-graph API and responding with an appropriate query or mutation that can then be reviewed and executed by the user.
In addition to the pc-graph API, our agent also understands the libraries used and some concepts about the DEX language. This information is carefully selected to be included in the context at runtime to provide optimal results.
One challenge this poses is the agent requires a large context to hold the relevant parts of the schema, as well as the supplementary material, such as the neo4j-graphQL documentation that includes additional types, queries, and mutations generated by the library. When using GPT4-8k we simply run out of room for adequate in-context learning. 32k context yields acceptable results, however, this also incurs additional cost. For example, we must send the GraphQL SDL (Schema Definition Language) on each request to OpenAI. This would not be an issue if we could finetune GPT4 conversational models with our schema, removing the need to include it in the context. However, this is not currently supported by OpenAI.
We have found three AI approaches that improve results from GPT4:
- Chain of Thought
- Chain of Thought (CoT) is an AI concept that simulates human-like thought processes, allowing systems to follow a logical sequence of ideas or concepts, similar to how humans connect thoughts in a chain-like fashion. This aids in natural language understanding, reasoning, and context comprehension. This technique produces the best results when applied to the state-of-the-art model GPT-4.
- Reflective AI
- Reflective AI, also known as self-aware AI or AI with reflective capabilities, refers to artificial intelligence systems that possess the ability to introspect and make decisions about their own actions and processes. This level of AI goes beyond traditional machine learning and basic decision-making capabilities, as it involves a higher degree of self-awareness and self-assessment. Reflexion, a framework for language agents with verbal reinforcement learning, “verbally reflects on task feedback signals, then maintains their own reflective text in an episodic memory buffer to induce better decision-making in subsequent trials."
- Dialoging with itself
- Dialog-enabled resolving agents (DERA) was presented as a method to iteratively improve output of LLMs by communicating feedback. The technique uses two agents: a researcher for information processing and a decider for final judgments. The interaction is framed as a dialogue between the agents and imbues the decider with autonomy to make judgements on the final output.
As a last step, we make use of tools that provide static syntax error checking for GraphQL queries to catch any possible hallucinations that have slipped past the initial mitigations.
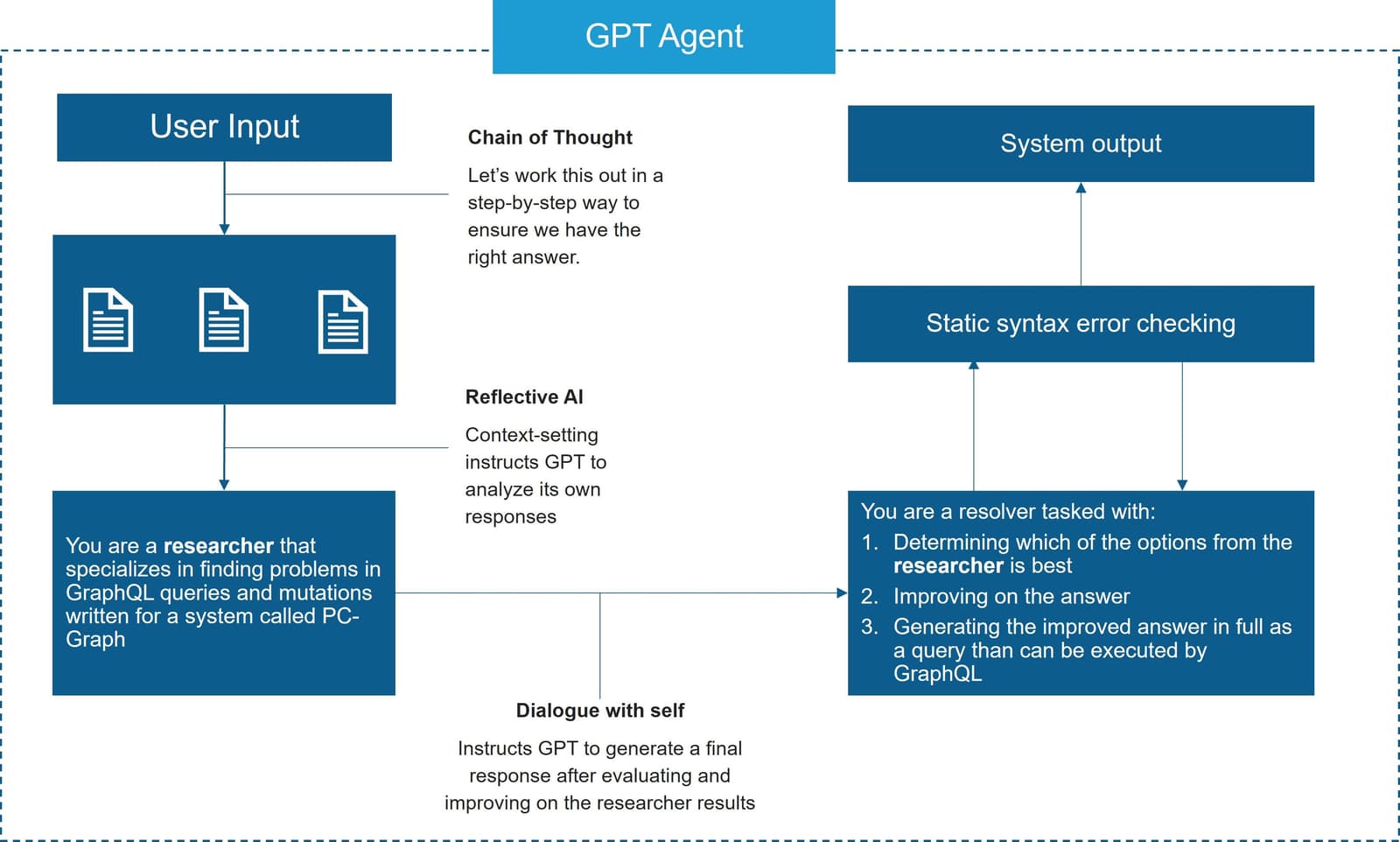
This design is further improved by initially generating three potential answers in the same prompt. This not only reduces the time and cost for a given prompt but also improves consistency as correct aspects of an answer are more likely to occur. Doing this we also have room for random variation in the interest of exploring unlikely but accurate options.
As a result of our approach we’ve been able to garner insights from policies without sharing private data. The quality and consistency of our query results have also improved remarkably with a notable reduction in hallucinations, particularly on tasks that involve constructing large or complex queries that include multiple filters and/or aggregate functions.
In a way we get to have our cake and eat it too; when forced to pick between a creative versus deterministic agent we simply do both.
About the Author
Related Blog Posts

Multicloud chaos ends at the Equinix Edge with F5 Distributed Cloud CE
Simplify multicloud security with Equinix and F5 Distributed Cloud CE. Centralize your perimeter, reduce costs, and enhance performance with edge-driven WAAP.

At the Intersection of Operational Data and Generative AI
Help your organization understand the impact of generative AI (GenAI) on its operational data practices, and learn how to better align GenAI technology adoption timelines with existing budgets, practices, and cultures.
Using AI for IT Automation Security
Learn how artificial intelligence and machine learning aid in mitigating cybersecurity threats to your IT automation processes.
Most Exciting Tech Trend in 2022: IT/OT Convergence
The line between operation and digital systems continues to blur as homes and businesses increase their reliance on connected devices, accelerating the convergence of IT and OT. While this trend of integration brings excitement, it also presents its own challenges and concerns to be considered.
Adaptive Applications are Data-Driven
There's a big difference between knowing something's wrong and knowing what to do about it. Only after monitoring the right elements can we discern the health of a user experience, deriving from the analysis of those measurements the relationships and patterns that can be inferred. Ultimately, the automation that will give rise to truly adaptive applications is based on measurements and our understanding of them.
Inserting App Services into Shifting App Architectures
Application architectures have evolved several times since the early days of computing, and it is no longer optimal to rely solely on a single, known data path to insert application services. Furthermore, because many of the emerging data paths are not as suitable for a proxy-based platform, we must look to the other potential points of insertion possible to scale and secure modern applications.