
What Is High Availability?
High availability (HA) refers to a system’s ability to operate continuously – without downtime or failure – usually by using built‑in failover mechanisms. High availability systems are designed to operate without fail even in the case of unexpected events.
Why High Availability Is Important
The main goal of HA is to avoid downtime, which is the period of time when a system, service, application, cloud service, or feature is either unavailable or not functioning properly. Downtime results in lost revenue, decreased productivity, and damage to a company’s reputation. This makes HA important for:
- Business continuity – HA ensures critical systems, features, and functions are always running as expected. HA systems recover quickly from failure so organizations can continue serving customers as expected (preferably without a noticeable outage).
- Improved user experience – Fast and reliable systems help maintain customer satisfaction and avoid the negative impacts of lost revenue, compromised data, and lost productivity.
- Competitive advantage – High levels of availability help organizations differentiate themselves as providing faster and more reliable services than the competition. This demonstrates a commitment to overall quality and customer satisfaction.
Types of High Availability
There are several types of HA, which can be classified based on the level of redundancy needed, the type of failure tolerance required, and the kind of system that is being protected. The most common types of HA include:
- Active-passive – A backup system is kept in a passive or standby mode, and only becomes active if the primary system fails. This method of failover protection sometimes requires manual intervention to switch to the backup system.
- Active-active – Multiple systems actively run and share the workload. If one system fails, other systems automatically pick up the workload. This type of HA requires more complex configuration and coordination among the systems but offers improved performance and scalability than a manual option.
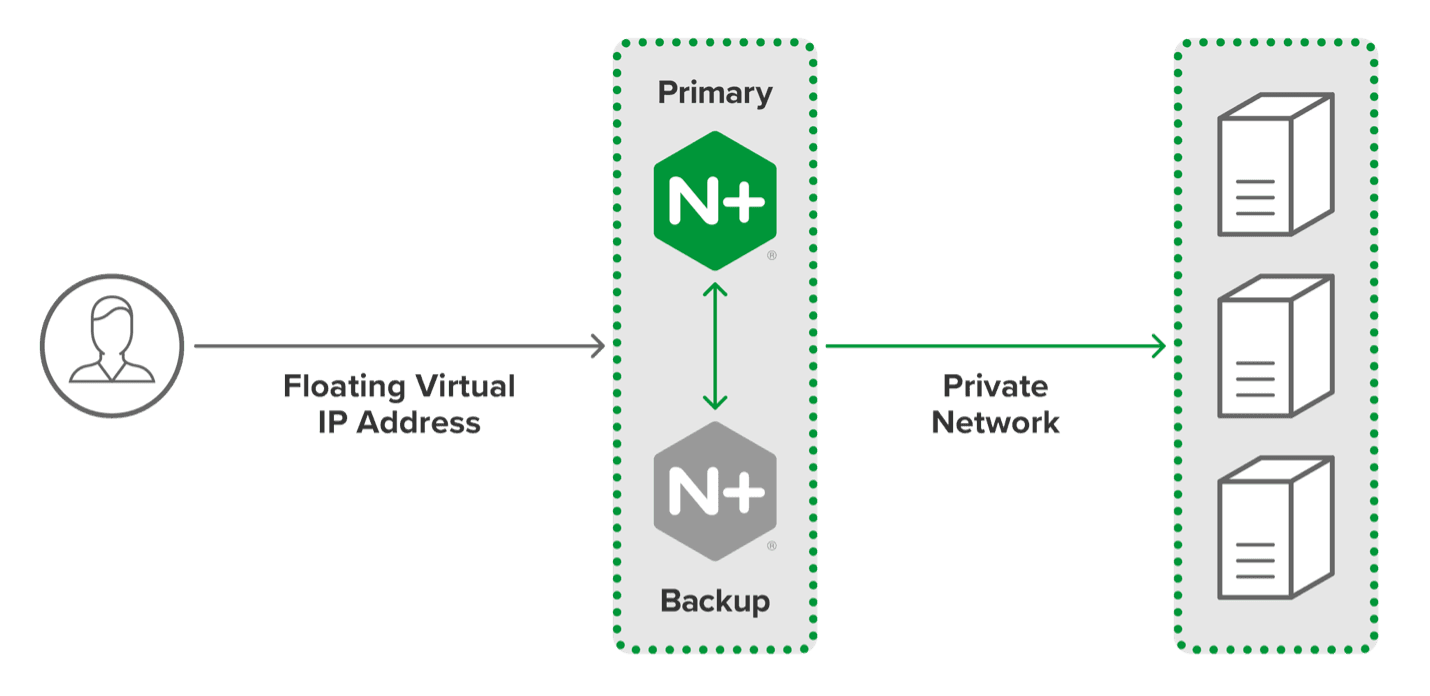
This diagram shows an active-passive HA cluster of two NGINX Plus servers. NGINX also supports active-active and other HA configurations.
How Is High Availability Implemented?
Redundancy and failover mechanisms prevent single points of failure such that the failure of a component doesn’t disturb the operation of the overall system, application, or feature. Common mechanisms include:
- Redundant components – Deploy multiple servers, network connections, storage systems, and power supplies within the system. If one component fails, another takes over without disruption.
- Monitoring and alerts – Constantly monitor performance and availability. When an outage or other problem is detected, an alert is generated. System administrators can quickly identify and resolve any issues, reducing the risk of downtime.
- Load balancing – One or more specialized servers intercept requests intended for a group of (backend) systems, distributing traffic among them for optimum performance. If one backend system fails, the load balancers automatically redirect incoming requests to the other systems.
- Failover mechanisms – Deploy active-passive or active-active configurations or failover clustering to ensure that one system fails, another system can take over with minimal disruption.
- Backup and recovery systems – Ensure data and applications can be quickly restored in case of failure. The systems can be hybrid, in different locations, cloud-based, or quickly brought online after a failure.
How to Support High Availability
The services and resources your need to deploy to provide HA depend on the type of system, the type of HA, and your organization’s specific requirements specific. Supporting elements include:
- Technical support – The first line of defense for organizations that need help with their HA systems. Dedicated support personnel can assist in troubleshooting, diagnosing, and resolving issues. They can also provide guidance on best practices for maintaining high levels of availability.
- Maintenance and upgrades – To remain operational and secure, HA systems must be regularly maintained and run the latest versions of software available.
- Disaster recovery planning – Critical for organizations that need to restore systems quickly. Predetermined and documented procedures mean system administrators don’t need to remember or come up with solutions during emergencies.
- Documentation and training – Helps system administrators understand how to manage their HA systems. The documentation may include best practices, tutorials, and training sessions.
Best Practices: High Availability
Following best practices improves operational performance and minimizes costly downtime. These common best practices can be tailored to the systems, locations, and desired outcomes of an organization.
- Incorporate redundancy – Every level of the system, from hardware components to network connections, is reinforced so if one component fails, the system still operates as expected.
- Load balance traffic – By distributing incoming requests across multiple systems, you enable the still-operational systems to take over when one system fails.
- Monitor performance and availability – Continuous monitorization and alerts reduce the time it takes to identify and resolve issues.
- Frequently test and validate failover mechanisms – Routine testing to determine whether failover mechanisms are still able to reliably take over a function in the event of a disruption.
- Backup and recovery procedures – Ensure that data and applications can be quickly restored in the event of failure.
- Regularly upgrade and maintain systems – This keeps applications and systems operational and secure.
- Train personnel – Regular tests and reinforcement of procedures need to be standard operating procedure, especially for individuals and teams responsible for HA.
- Consider cloud solutions – Cloud storage and disaster recovery mean systems can continue to operate regardless of the location of failure.
- Monitor security – Implement measures that prevent data breaches or access to systems by bad actors or unauthorized users.