
Availability is serious business in an economy where applications are currency. Apps that don’t respond are summarily deleted and bad mouthed on the Internet with the speed and sarcasm of a negative Yelp review.
Since the earliest days of the Internet, organizations have sought to ensure applications (web sites, in the old days) were available 24x7x365. Because the Internet never sleeps, never takes vacation, and never calls in sick.
To serve that need (requirement, really), scalability rose as one of the first application services to provide for availability. The most visible – and well-understood – application service serving the needs of availability is load balancing.
There are many forms of load balancing, however, and scalability patterns you can implement using this core technology. Today, I’m going to highlight the top five scalability patterns in use that keep apps and the Internet online and available 24x7x365.
Global Server Load Balancing (GSLB)
GSLB is terribly misnamed. It was never really about server load balancing, it was about site availability. Today, that’s extending to mean app availability, as well.
GSLB is the means by which you ensure that if one data center (cloud or traditional) isn’t responding, you can find another. GSLB can be applied at the domain or host level. So you can use it to switch example.com between locations as well as api.example.com.
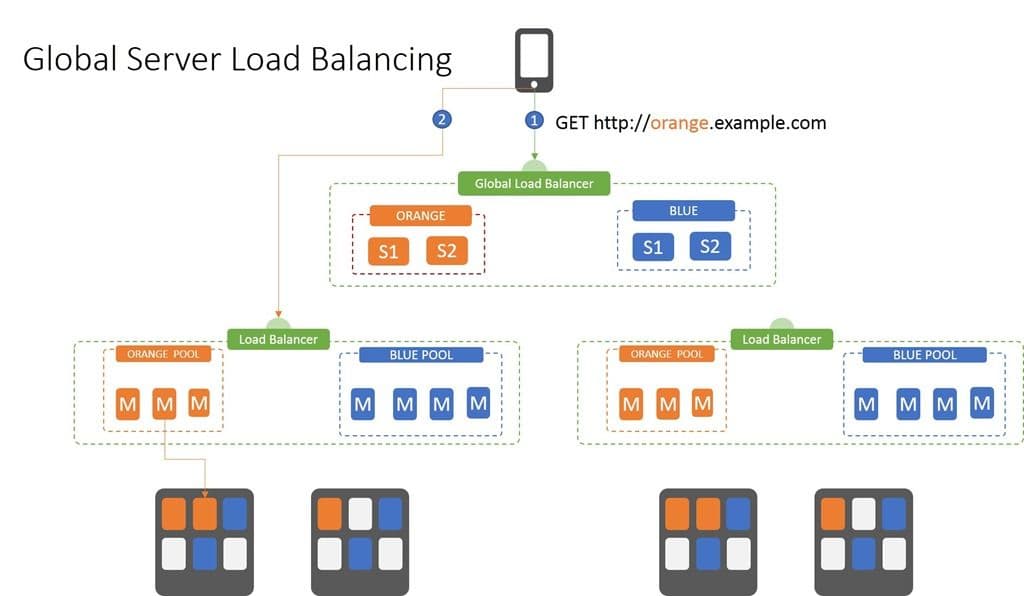
At its most basic, GSLB uses rudimentary, DNS-based load balancing. That means it’s got a list of IP addresses associated with a domain or host, and if the first one isn’t available, requests are directed to the second in the list – or third, or fourth, and so on.
There are two steps to this process:
- Ask the global load balancer for the appropriate IP address. This is the negative always associated with GSLB – if you’ve asked in the last 15 minutes or whatever the current TTL is for the IP address of cheese.com, you get the last response you received. So if that site went down in that time, you’re not going to get connected.
- Make the request to the IP address of the site returned by the GSLB inquiry. This often ends up being a local load balancer which uses its own algorithms and decision-making process to get the request to the appropriate resource.
There’s generally no intelligence to the decision made in step 1; it is strictly based on whether or not a given site is responding. Still, this is how you can use multiple locations – cloud, hosting provider, on-premises – to ensure availability. By strategically choosing locations in diverse geographical areas, you can avoid the impact of natural disasters or Internet outages.
But that’s more of a DR (disaster recovery) or BC (business continuity) scenario. There are others that take advantage of smarter GSLB application services such as geolocation and application performance. So if the app at Site A is performing poorly, maybe you want to send visitors to Site B until the issue is resolved. Or perhaps you want to direct users to the geographically closest location to help improve performance (because the speed of light is still a rule and distance matters to app performance).
Regardless of how the decision is made, the basic pattern remains the same: GLSB distributes requests across multiple, physically separated sites by returning the IP address of one of the available sites. Whether APIs or apps, GSLB is a top-level availability assurance pattern.
Plain Old Load Balancing (POLB)
Connection-based Availability
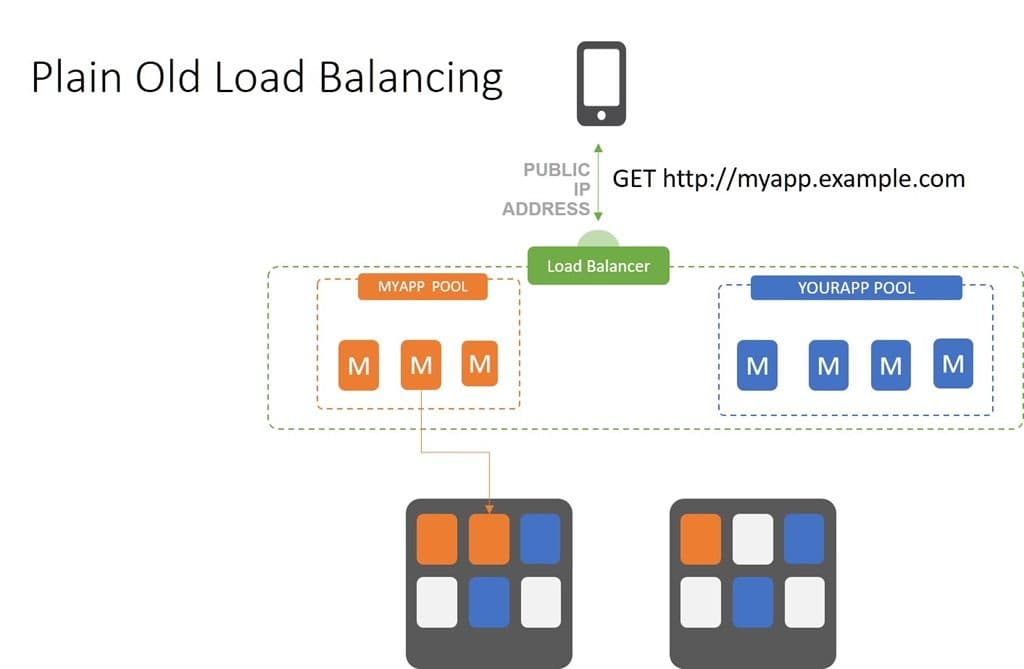
Plain Old Load Balancing (POLB) is a term I like to use to describe standard, TCP-based load balancing. Availability is achieved using this pattern simply by cloning apps and making sure a connection between the client (user, device) and the app can be made.
The load balancer (or proxy if you prefer) receives a connection request, selects an available app instance, and forwards the connection on. That’s the last time the load balancer gets actively involved. It’s like the ‘intro e-mail’ where you facilitate two colleagues meeting. You’re an active participant in the initial exchange, but are subsequently moved to the cc line and generally don’t engage further.
I use the term POLB because there’s nothing more than algorithms involved in the choice of how to direct requests. Unfortunately, there are a lot of things that can go wrong depending on the algorithm being used to distribute requests. For example, round robin doesn’t care about capacity or performance. It just selects “the next app” and off the request goes. Choosing “least connections” can quickly impact performance by loading up a resource, while others might be faster. The choice of algorithms becomes a critical component of maintaining availability.
POLB is the default method of load balancing inside container environments and for many cloud-native load balancing services.
Persistence
Sticky Sessions & SSL
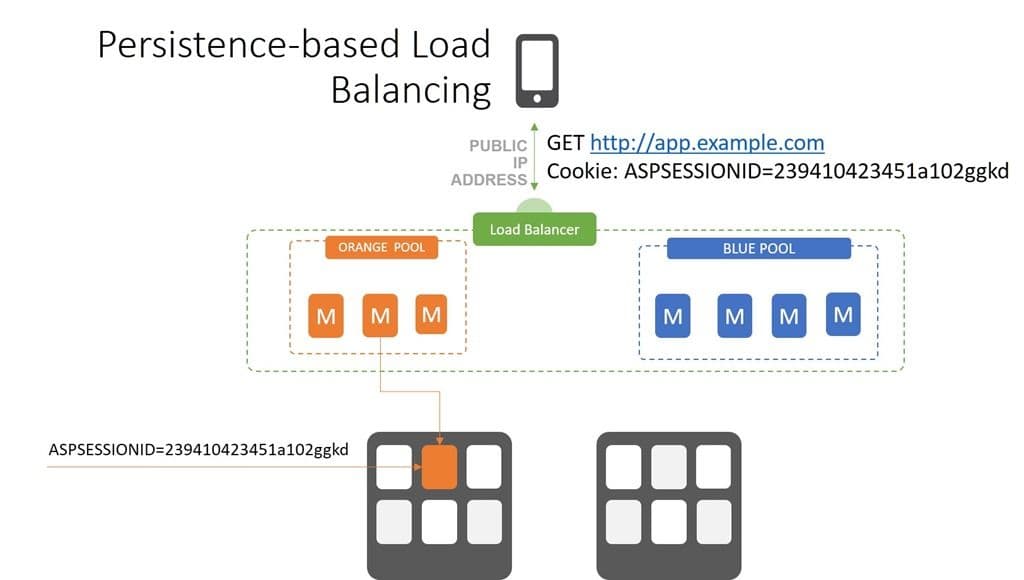
One of the realities of three-tier applications is that they are, as a general rule, stateful. That means they store information between requests and responses that is critical to the operation of the application. Your shopping cart, credentials, status, last page you visited, and which step in a process you’re on are all tidbits that are often stored as part of the “session”. The thing is that many apps developed using three-tier frameworks wound up storing that session on the application or web server, and not in a database. That meant that once you were hooked up to a server, you had to keep going back to that server to make sure all your information was available.
Load balancers implemented persistence in a variety of ways, the most popular being cookie-based. Session ids were stored in a cookie that were then used by the load balancer to make sure requests got to the right server, effectively bypassing an algorithmic selection process.
When the use of SSL/TLS became a critical requirement for shoppers to feel secure, the same issues cropped up. SSL/TLS enables a secure session between a client and a specific app server. To ensure both sides of the conversation could decrypt and use data exchanged over that connection, the load balancer had to be able to send client requests to the same server it started on. Using the same techniques as enables session-based persistence, load balancers were able to support SSL/TLS-based persistence.
Regardless of the specific type of persistence used, the pattern is the same. If there exists an indicator that a session has already been established, the load balancer honors the existing connection and ensures it remains for the duration of the user session. If there is not, the load balancer selects a resource based on its configuration and algorithms and makes the connection.
This has consequences on capacity planning when selecting a load balancing algorithm. Least connections is a good choice for this scenario as it ensures that no single resource will become overloaded with ongoing sessions while others sit idle. With other algorithms there is a likelihood that a single resource will wind up maintaining many user sessions at the same time, which has a negative impact on performance for all users directed to that server.
Host-Based Load Balancing
Virtual Servers
Host-based load balancing is one of the most common and ubiquitously supported scalability patterns. You might think you don’t need a load balancer to implement this one, as all web servers support the ability to masquerade as multiple hosts at the same time. But you do. While a web/app server can host multiple virtual servers, it doesn’t necessarily load balance across them. So you still need a load balancer to scale. The question is will the load balancer split out hosts or will you leave that up to the web/app server?
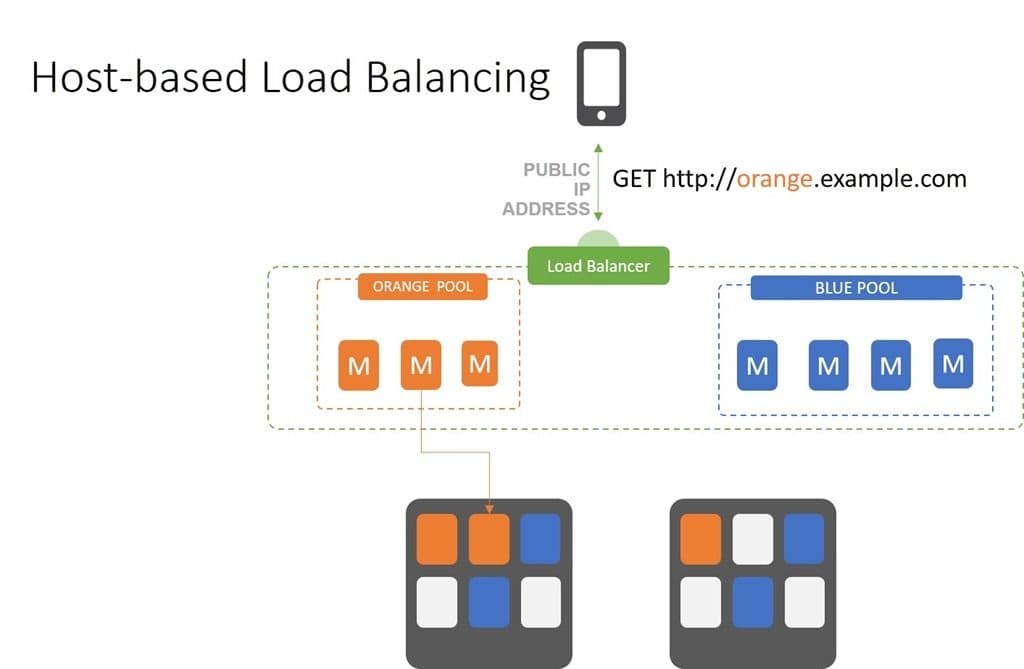
Whether using web/app server directives or an external load balancer, the flow remains the same. A request is made and received by the target (load balancer or web/app server). Target server then inspects the HTTP headers and finds the host value before directing the request to the appropriate virtual server.
The benefit of using a load balancer to split hosts is in its ability to enable isolation of domains based on host and scale them individually. This is more efficient and can reduce the number of servers (hardware and software) you need to scale an application. It further makes capacity planning easier as you can better predict what load each host server can handle at a given time.
That’s because invoking business logic is not the same in terms of compute required as that of requesting an image. Mixing and matching hosts in the same scalability domain makes for volatile load and unpredictable capacity. If you choose to use a load balancer to provide plain-old load balancing, then the web/app server is responsible for splitting out hosts and directing requests to the appropriate virtual server. Other disadvantages of this approach is one of a shared infrastructure nature, with version conflicts and patching as well as app updates potentially causing friction between virtual servers.
The growing adoption of containers and microservices is driving the use of host-based load balancing in the form of ingress controllers.
Route and Return
Layer 7 (HTTP) Load Balancing
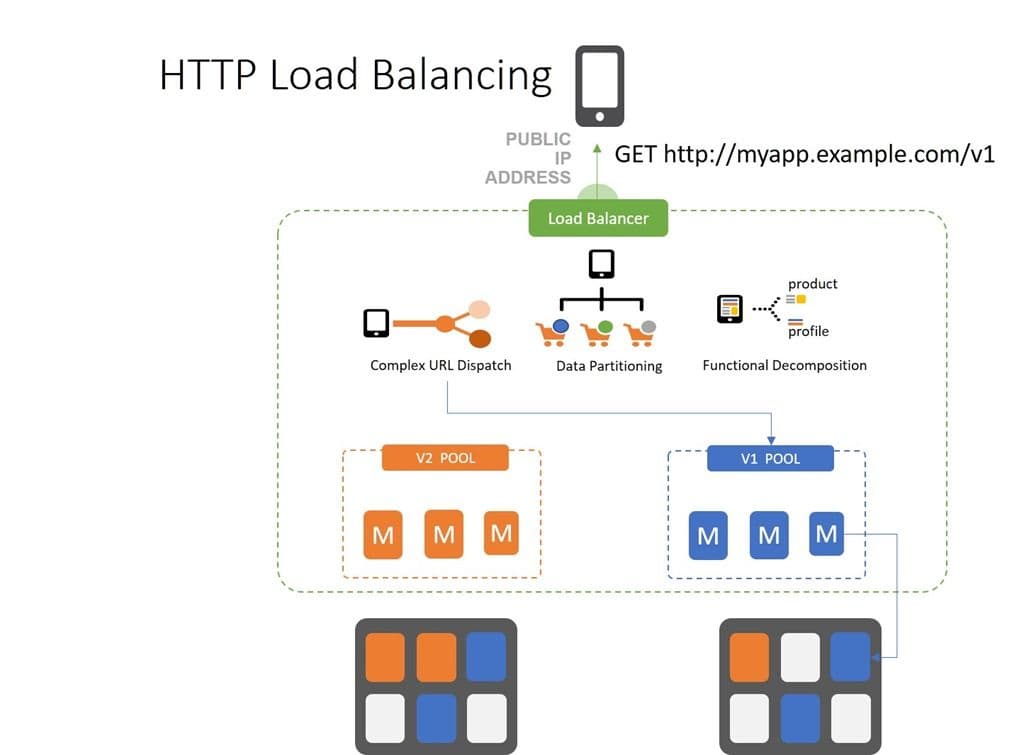
Layer 7 (HTTP) load balancing is my favorite thanks to the versatility (agility?) it offers. You can load balance requests based on anything HTTP – including the payload. Most folks (smartly, in my opinion) restrict their load balancing rules to what can be found in the HTTP header. That includes the host, the HTTP method, content-type, cookies, custom headers, and user-agent, among others.
HTTP load balancing is first about routing and then about load balancing. A typical HTTP load balancing pattern takes the form of route –> distribute. That means that first a decision is made as to which virtual server a request should be directed and then an algorithm selects a resource from the pool supporting that virtual server.
HTTP load balancing enables patterns like API versioning, where the API version is embedded in the URI (or in a custom HTTP header). The load balancer is able to separate out versions and ensure clients are sent to the correct back-end service for execution. This always graceful migration of clients in situations where you can’t force-upgrade.
This type of scalability pattern also supports other scalability patterns like functional decomposition and data partitioning. It’s the most robust, agile scalability pattern in the mix and allows for a vast array of options when scaling out apps and increasingly, microservices.
So to sum up, we’ve got five major scalability patterns, most of which can be (and often are) combined to enable the most efficient use resources and the greatest performance possible. Chances are if you aren’t using one of them now, you will be, so understanding their basic composition is a good foundation for building a scalable architecture no matter what kind of apps you’re using – or where you might have them deployed.
Scale on!
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

F5 joins the Dell AI Ecosystem Program to help enterprises operationalize AI
F5 joins the Dell AI Ecosystem Program to help enterprises deploy production AI with greater performance, security, and control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.