
For the most part, scaling apps and APIs are pretty much the same thing. Both require some sort of load balancer – usually a proxy – and are required to distribute requests across a pool of resources.
But there is a fairly significant difference between how those requests are distributed across resources. In the case of algorithms we’re really distributing load while in the case of architecture we’re directing load. Now, that might seem like a pedantic distinction best left to academia. The truth is that the choice between algorithms and architecture has a profound impact on scale and performance. As both are kind of the reason you use load balancing, the distinction becomes an important one.
Plain Old Load Balancing
Algorithmic-based load balancing can be referred to as just load balancing or, as I like to call it, Plain Old Load Balancing. This is the method of scale we’ve been using since before the turn of the century. Its age does not mean it should be abandoned; quite the contrary. In many situations, plain old load balancing is the best choice for balancing scale and performance.
Plain old algorithmic load balancing uses, as one might guess, algorithms in its decision making process. That means that distribution algorithms like round robin, least connections, fastest response, and their weighted equivalents are used to select a resource to respond to any given request.
This is a straight forward decision. Like the honey badger, algorithms don’t care about anything other than executing based on the data available. If there are five resources available, then one of those five will be selected based on the algorithm. Period.
Algorithmic-based load balancing is, as you might imagine, quite fast. It doesn’t take long using today’s processing power to execute the appropriate algorithm and make a decision. With the exception of round robin and certain weighted distribution algorithms, algorithms are stateful. That means they must keep track of variables like “how many connections are there right now to resource A, B, and C?” or “Which resource responded the fastest to their last request?” The load balancer must keep track of this information. This information can grow quite large and require more resources to manage in environments scaling traditional, monolithic applications that require multiple, long-lived connections.
Where plain old load balancing excels is in scaling microservices. That’s because each microservice has (or should have in an ideal architecture) one function. Scaling these services is easily achieved by employing a basic algorithm (usually round robin) because they are generally equivalent in capacity and performance. Because of the nature of microservices architectures, which may require multiple service calls to fulfill a single user request, fast decisions are a must. That makes basic algorithmic-based load balancing a good choice for such environments.
The basic rule of thumb is this: if you are scaling simple services with a limited set of functions, all of which are generally equivalent in terms of performance, then plain old load balancing will suffice. This is what you see inside container environments and why so much of the native scaling capabilities are based on simple algorithms.
For other applications and situations, you will need to look to architectural-based load balancing.
HTTP Load Balancing
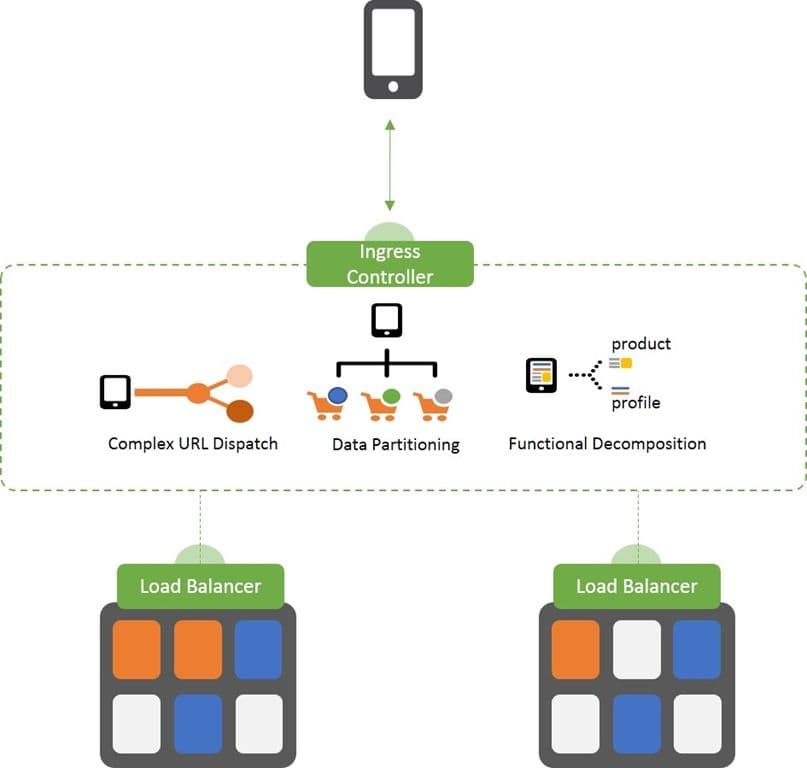
Architectural-based load balancing is the art (yes, art not science) of using a load balancer to slice and dice requests in a way that matches the architecture of the application it is scaling. Architectural-based load balancing is more about directing traffic than it is distributing it. That’s because it takes advantage of Layer 7 (usually HTTP) to decide where a given request needs to go, and why we tend to call it HTTP load balancing (amongst other more esoteric (and networking-focused) terms).
The ability to direct requests is increasingly important in a world exposed by APIs and built on microservices. That’s because you need to be able to direct API requests based on version, use host names or URI paths to dispatch requests to specific microservices, or to functionality decompose an application.

Most organizations want to expose a consistent API that’s easy to use. Whether that’s to encourage citizen developers to create new applications that use the API or to enable partners to easily connect and integrate, a consistent, simple API is imperative to ensuring adoption.
But APIs are often messy in reality. They are backed by multiple services (often microservices) and may be distributed across locations. They are rarely confined to a single service. Complicated matters, they are more frequently updated than previous generations of apps, and not reliably backward compatible. Too, mobile apps may make use of both old and new resources – sharing images with web apps and using the same APIs as everyone else.
To scale these “apps” and APIs requires an architectural approach to load balancing. You need to direct traffic before you distribute it, which means using a layer 7 (HTTP) capable load balancer to implement architectural patterns like URL dispatch, data partitioning, and functional decomposition. Each of these patterns is architectural in nature, and requires a greater affinity toward the application or API design than is true of traditional apps.
HTTP load balancing is increasingly important in the quest to scale apps while balancing efficiency with agility, as well as supporting APIs.
Scalability Requires Both
Rarely will you see only one type of scale in the real world. That’s because organizations increasingly deliver a robust set of applications that span decades of development, app architectures, platforms, and technologies. Very few organizations can boast support for only “modern” applications (unless modern includes anything not running on a mainframe).
Thus, you are likely to see – and use – both algorithmic and architectural load balancing to scale a variety of applications. That’s why understanding the difference is important, because using one when the other is more appropriate can result in poor performance and/or outages, neither of which is good for users, business, or you, for that matter.
You will increasingly see the two approaches combined to scale modern applications. Sometimes the two will actually exist as a single service designed to scale the logical (the API) and the physical (the actual service behind the API). Application Delivery Controllers (ADC) are usually the platform on which a combined approach is implemented because they are able to perform both with the same alacrity.
Sometimes these are performed by two different systems. For example, in containerized environments an ingress controller is responsible for architectural load balancing while internal, native services are generally responsible for scale using algorithmic load balancing.
Regardless of implementation and deployment details, the reality is that both algorithmic and architectural-based approaches to load balancing have a role to play in scaling apps and APIs. The key to maximizing their strengths to your advantage is to match the load balancing to the application architecture.
Scale on.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

A new path to technical excellence for F5 partners
Introducing F5 Partner Foundations, a structured learning curriculum to build F5 partner engineer expertise with a clear pathway to specialization.

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.