
Scaling containers is more than just slapping a proxy in front of a service and walking away. There’s more to scale than just distribution, and in the fast-paced world of containers there are five distinct capabilities required to ensure scale: retries, circuit breakers, discovery, distribution, and monitoring.
In this post on the art of scaling containers, we’ll dig into monitoring.
Monitoring
Monitoring. In an era where everything seems to be listening and/or watching everything from how fast we drive to what’s in our refrigerator, the word leaves a bad taste in a lot of mouths. We can – and often do – use the word ‘visibility’ instead, but that semantic sophistry doesn’t change what we’re doing – we’re watching, closely.
Everything about scale relies on monitoring; on knowing the state of the resources across which you are distributing requests. Sending a request to a ‘dead zone’ because the resource has crashed or was recently shut down is akin to turning onto a dead-end street with no outlets. It’s a waste of time.
Monitoring comes in many flavors. There’s the “can I reach you” monitoring of a ping at the network layer. There’s the “are you home” monitoring of a TCP connection. And there’s the “are you answering the door” of an HTTP request. Then there’s the “have you had your coffee yet” monitoring that determines whether the service is answering correctly or not.
Along with just checking in on the health and execution of a service comes performance monitoring. How fast did the service answer is critical if you’re distributing requests based on response times. Sudden changes in performance can indicate problems, which means it’s historically significant data that also needs to be monitored.
There’s active monitoring (let me send you a real request!), synthetic monitoring (let me send you a pretend request), and passive monitoring (I’m just going to sit here and watch what happens to a real request). Each has pros and cons, and all are valid methods of monitoring. The key is that the proxy is able to determine status – is it up? is it down? has it left the building along with Elvis?
Reachability, availability, and performance are all aspects of monitoring and necessary to ensure scalability. Which means it’s not just about monitoring, it’s about making sure the load balancing proxies have up-to-date information regarding the status of each resource to which it might direct a request.
If you think about the nature of containers and the propensity to pair them with a microservice-based architecture, you can see that monitoring quickly becomes a nightmarish proposition. That’s because the most popular model of load balancing inside container environments are forward (and sidecar) proxies. Both require every node know about the health and well-being of every resource to which it might need to send a request. That means monitoring just about every resource.
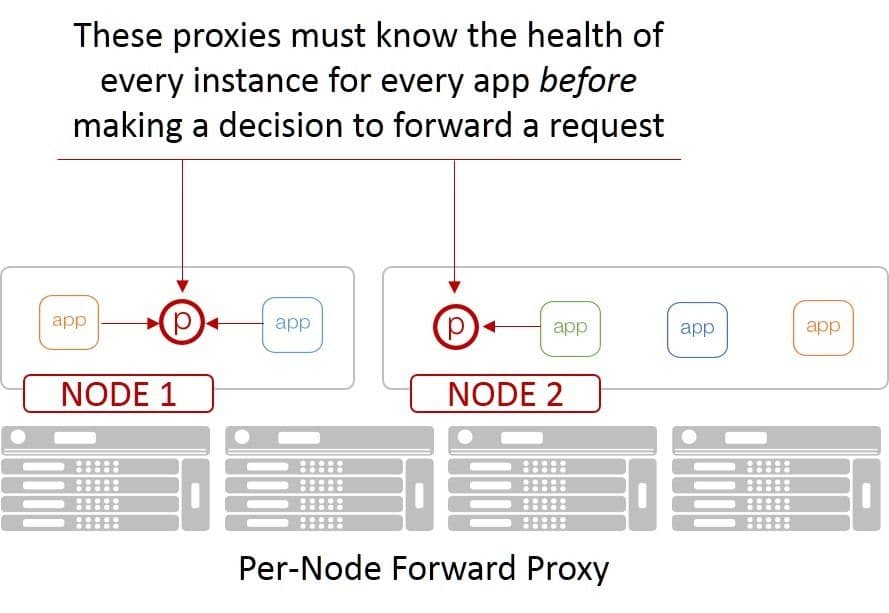
You can imagine it’s not really efficient for a given resource to expend its own limited resources responding to fifteen or twenty forward proxies as to its status. Monitoring in such a model has a significantly negative effect on both performance and capacity, which makes scale even harder.
Monitoring has never quite had such a significant impact on scale as we’re seeing with containers.
And yet its critical – as noted above – because we don’t want to waste time with ‘dead end’ resources if we can avoid it.
The challenges of necessary monitoring are one of the reasons the service mesh continues to gain favor (and traction) as the future model of scale within container environments.
Because monitoring is not optional, but it shouldn’t be a burden, either.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

A new path to technical excellence for F5 partners
Introducing F5 Partner Foundations, a structured learning curriculum to build F5 partner engineer expertise with a clear pathway to specialization.

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.