The guidelines known as the twelve‑factor app were first published more than ten years ago. Since then, nearly all its mandated practices have become the de facto standard way to write and deploy web apps. And while they have remained applicable in the face of changes to the way apps are organized and deployed, in some cases additional nuance is required to understand how the practices apply to microservices patterns for developing and deploying apps.
This blog focuses on Factor 3, Store config in the environment, which states:
- Configuration is everything that varies between deployment environments (which the twelve‑factor app calls deploys).
- Configuration must be strictly separated from the app’s code – otherwise how can it vary across deploys?
- Configuration data is stored in environment variables.
As you move into microservices, you can still honor these guidelines, but not always in a way that maps exactly to a literal interpretation of the twelve‑factor app. Some guidelines, such as providing configuration data as environment variables, carry over nicely. Other common microservices practices, while respecting the core principles of the twelve‑factor app, are more like extensions of it. In this post we’ll look at three core concepts of configuration management for microservices through the lens of Factor 3:
- Clearly Defining Your Service Configuration
- How Configuration Is Provided to a Service
- Making a Service Available as Configuration
Key Microservices Terminology and Concepts
Before jumping into the discussion of adapting Factor 3 for microservices, it’s helpful to understand some key terms and concepts.
- Monolithic app architecture – A traditional architectural model that separates app functions into component modules, but includes all modules in a single codebase.
- Microservices app architecture – An architectural model that builds a large, complex app from multiple small components which each perform a well‑scoped set of operations (such as authentication, notification, or payment processing). “Microservice” is also the name for the small components themselves. In practice, some “microservices” may actually be quite large.
- Service – A general term for a single application or microservice in a system.
- System – In the context of this blog, the full set of microservices and supporting infrastructure that come together to create the complete functionality provided by the organization.
- Artifact – An object created by a test and build pipeline. It can take many forms, such as a Docker image containing an app’s code.
- Deployment – A running “instance” of an artifact, which runs in an environment such as staging, integration, or production.
Microservices versus Monoliths
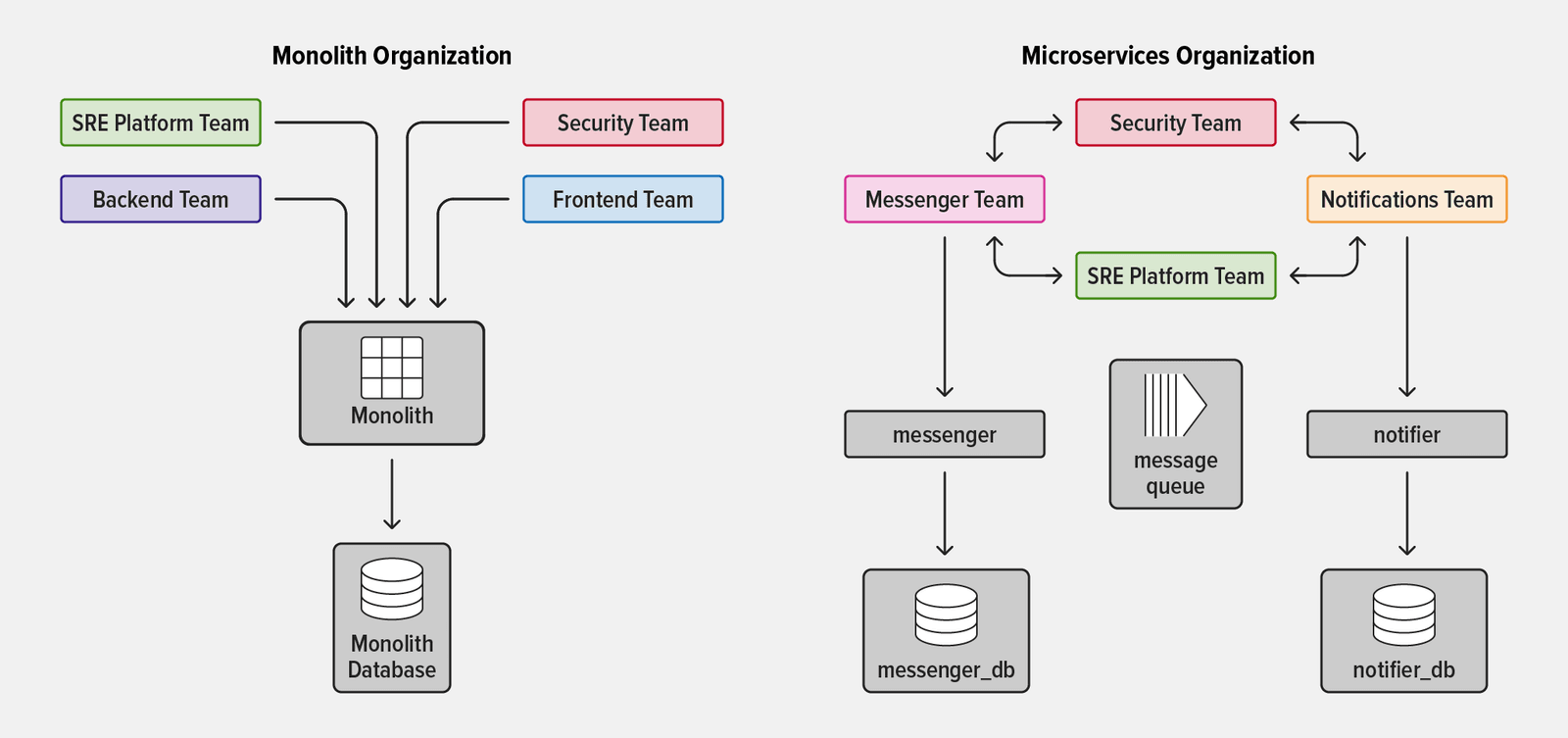
With a monolithic application, all teams in the organization work on the same application and surrounding infrastructure. Although monolithic apps generally appear simpler than microservices on paper, there are several common reasons why organizations decide to move to microservices:
- Team autonomy – It can be tricky to define ownership of functionality and subsystems in a monolith. As organizations grow and mature, responsibility for app functionality is often distributed across more and more teams. The creates dependencies between teams because the team that owns a piece of functionality doesn’t own all the related subsystems in the monolith.
- Decreasing the “blast radius” – When a large application is developed and deployed as one single unit, an error in one subsystem can degrade the functionality of the entire app.
- Scaling functionality independently – Even if just a single module in a monolithic app is under heavy load, the organization must deploy many instances of the entire app to avoid system failure or degradation.
Of course, microservices come with their own challenges – including increased complexity, less observability, and the need for new security models – but many organizations, especially large or fast‑growing ones, decide the challenges are worth it to give their teams more autonomy and flexibility in creating reliable, stable foundations for the experiences they provide to their customers.
Changes Required for Microservices Architectures
When you refactor a monolithic app into microservices, your services must:
- Accept configuration changes in a predictable way
- Make itself known to the wider system in a predictable way
- Be well documented
For a monolithic app, little inconsistencies in processes and dependence on shared assumptions are not critical. With a lot of separate microservices, however, those inconsistencies and assumptions can introduce a lot of pain and chaos. Many of the changes you need to make with microservices are technical necessities, but a surprising number concern how teams work internally and interact with other teams.
Notable organizational changes with a microservices architecture include:
- Instead of working together on the same codebase, teams become totally separate, with each team wholly responsible for one or more services. In the most common implementation of microservices, teams are also reorganized to be “cross‑functional”, meaning that they have members with all the competencies required to complete the team’s goals with minimal dependencies on other teams.
- Platform teams (responsible for the overall health of the system) must now coordinate multiple services owned by different teams instead of dealing with a single application.
- Tooling teams must remain able to provide tooling and guidance to the various service‑owner teams to help them accomplish their goals quickly, while still keeping the system stable.
Clearly Defining Your Service Configuration
One area of microservices architecture where we need to extend Factor 3 concerns the need to clearly define certain vital information about a service, including its configuration, and to assume a minimum of shared context with other services. Factor 3 doesn’t address this directly, but it’s especially important with large numbers of separate microservices contributing to application functionality.
As a service owner in a microservices architecture, your team owns services that play specific roles in the system as a whole. Other teams whose services interact with yours need to access your service’s repository to read code and documentation as well as make contributions.
Further, it’s an unfortunate reality in the software development field that team membership changes often, not only because developers join and leave the company, but also because of internal reorganization. Also, responsibility for a given service is also often transferred between teams.
In view of these realities, your codebase and documentation need to be extremely clear and consistent, which is achieved by:
- Clearly defining the purpose of each configuration option
- Clearly defining the expected format of the configuration value
- Clearly defining how the application expects configuration values to be provided
- Recording this information in a limited number of files
Many application frameworks provide a means for defining required configuration. For example, the convict NPM package for Node.js applications uses a complete configuration “schema” stored in a single file. It acts as the source of truth for all the configuration a Node.js app requires to run.
A robust and easily discoverable schema makes it easy for members of both your team and others to interact confidently with your service.
How Configuration Is Provided to a Service
Having clearly defined what configuration values your application needs, you also need to honor the important distinction between the two primary sources from which a deployed microservices application pulls its configuration:
- Deployment scripts which explicitly define configuration settings and accompany the application source code
- Outside sources queried at deployment time
Deployment scripts are a common code‑organization pattern in microservices architectures. As they’re new since the original publication of the twelve‑factor app, they necessarily represent an extension of it.
Pattern: Deployment and Infrastructure Configuration Next to the Application
In recent years, it has become common to have a folder called infrastructure (or some variant of that name) in the same repository as your application code. It usually contains:
- Infrastructure as code (Terraform is a common example) that describes the infrastructure on which the service depends, such a database
- Configuration for your container orchestration system, such as Helm charts and Kubernetes manifests
- Any other files related to the deployment of the application
At first glance, this might seem like a violation of the prescription by Factor 3 that configuration is strictly separated from code.
In fact, its placement next to your application means an infrastructure folder actually respects the rule while enabling valuable process improvements that are critical for teams that work in microservices environments.
The benefits of this pattern include:
- The team that owns the service also owns the service deployment and the deployment of service‑specific infrastructure (such as databases).
- The owning team can make sure changes to any of these elements go through its development process (code review, CI).
- The team can easily change how its service and supporting infrastructure are deployed without depending on outside teams to do work for them.
Notice that the benefits provided by this pattern reinforce individual team autonomy, while also ensuring that additional rigor is applied to the deployment and configuration process.
Which Type of Configuration Goes Where?
In practice, you use the deployment scripts stored in your infrastructure folder to manage both configuration defined explicitly in the scripts themselves and the retrieval of configuration from outside sources at deploy time, by having the deployment script for a service:
- Define certain configuration values directly
- Define where the process executing the deployment script can look for the desired configuration values in outside sources
Configuration values that are specific to a certain deployment of your service and fully under your team’s control of your team can be specified directly in the files in the infrastructure folder. An example might be something like a limit on the length of time a database query initiated by the app is allowed to run. This value may be changed by modifying the deployment file and redeploying the application.
One benefit of this scheme is that changes to such configuration necessarily go through code review and automated testing, lessening the likelihood that a misconfigured value causes an outage. Changes to values that go through code review and the values of configuration keys at any given time are discoverable in the history of your source‑control tooling.
Values that are necessary for the application to run but are not under your team’s control must be provided by the environment in which the application is deployed. An example is the hostname and port at which the service connects to another microservice on which it depends.
Because that service is not owned by your team, you cannot make assumptions about the values like the port number. Such values can change at any time and need to be registered with some central configuration storage when they are changed – whether that change is done manually or by some automatic process. They can then be queried by applications that depend on them.
We can summarize these guidelines in two best practices for microservices configuration.
A Microservices Configuration Don’t: Rely on Hardcoded or Mutually Agreed Values
It might seem simplest to hardcode certain values in your deployment scripts, for example the location of a service that your service interacts with. In practice, hardcoding of that type of configuration is dangerous, especially in modern environments where service locations commonly change often. And it’s particularly dangerous if you don’t own the second service.
You might think that you can rely on your own diligence to keep a service location updated in your scripts, or worse, that you can rely on the owning team to inform you when the location changes. Diligence often slips in times of stress, and depending on human rigor puts your system at risk of failing without warning.
A Microservices Configuration Do: Have the Service Ask “Where Is My Database?”
Whether location information is hardcoded or not, your application must not depend on critical infrastructure being at a certain location. Instead, a newly deployed service needs to ask some common source within the system questions like “where is my database?” and receive an accurate answer about the current location of that external resource. Having every service register itself with the system as it deploys makes things much simpler.
Making a Service Available as Configuration
Just as the system needs to provide answers to the questions “where is my database?” and “where is ‘service X’ on which I’m depending?”, a service must be exposed to the system in such a way that other services can easily find and talk to it without knowing anything about how it is deployed.
A key configuration practice in microservices architectures is service discovery: the registration of new service information and dynamic updating of that information as accessed by other services. After explaining why service discovery is necessary for microservices, let’s explore an example of how to accomplish it with NGINX Open Source and Consul.
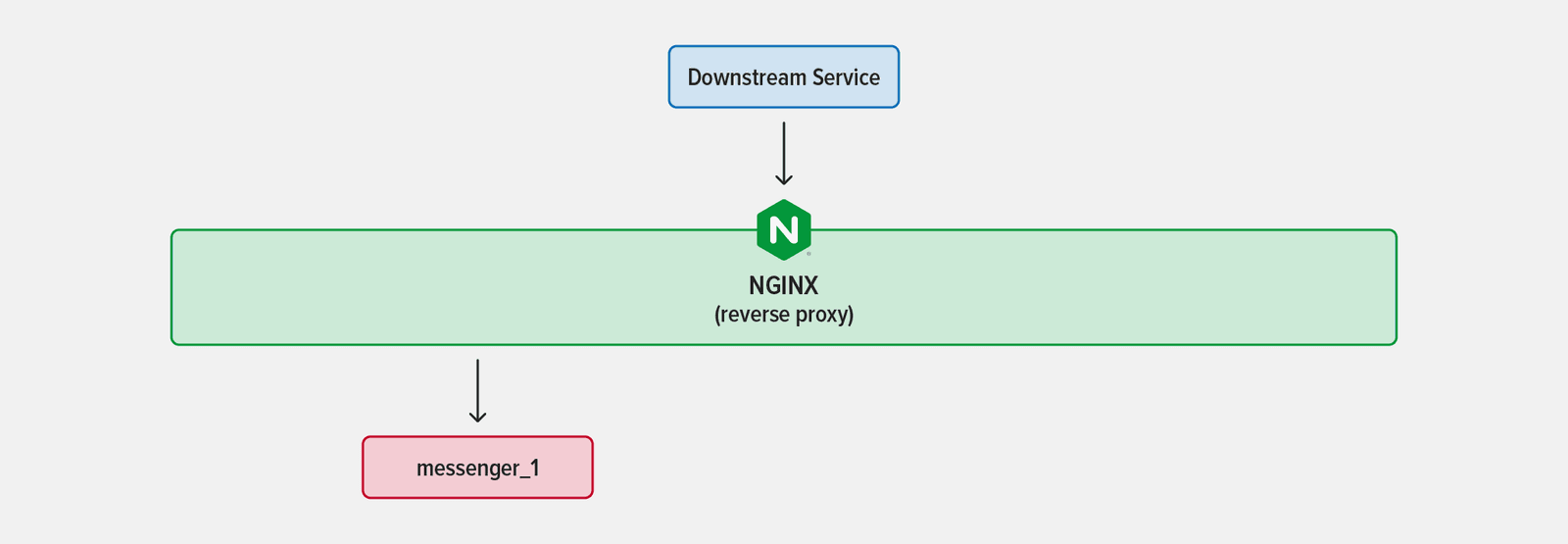
It’s common practice to have multiple instances (deployments) of a service running at once. This enables not only the handling of additional traffic, but also the updating of a service without downtime by launching a new deployment. Acting as reverse proxy and load balancer, tools like NGINX process incoming traffic and route it to the most appropriate instance. This is a nice pattern, because services that depend on your service send requests only to NGINX and don’t need to know anything about your deployments.
As an example, say you have a single instance of a service called messenger running behind NGINX acting as a reverse proxy.
Now what if your app becomes popular? That’s considered good news, but then you notice that because of the increased traffic the messenger instance is consuming a lot of CPU and taking longer to process requests, while the database seems to be doing just fine. This indicates that you might be able to solve the problem by deploying another instance of the messenger service.
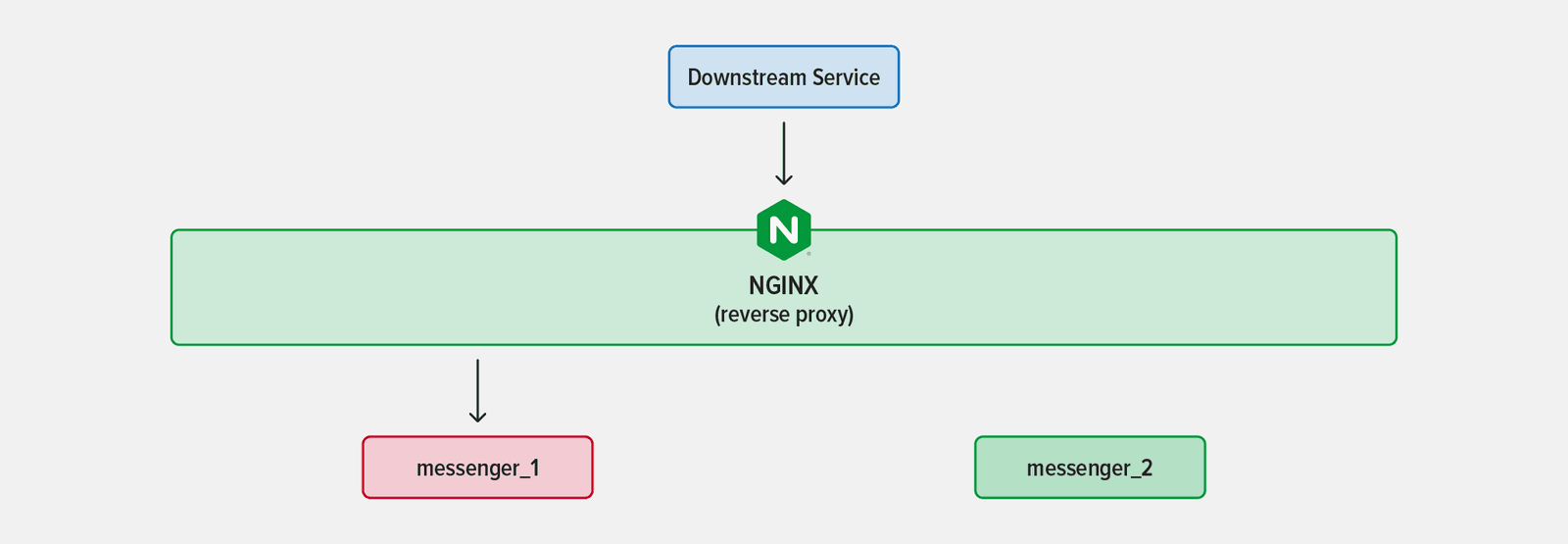
When you deploy the second instance of the messenger service, how does NGINX know that it’s live and start sending traffic to it? Manually adding new instances to your NGINX configuration is one approach, but it quickly becomes unmanageable as more services scale up and down.
A common solution is to track the services in a system with a highly available service registry like Consul. New service instances register with Consul as they deploy. Consul monitors the instances’ status by periodically sending them health checks. When an instance fails health checks, it’s removed from the list of available services.
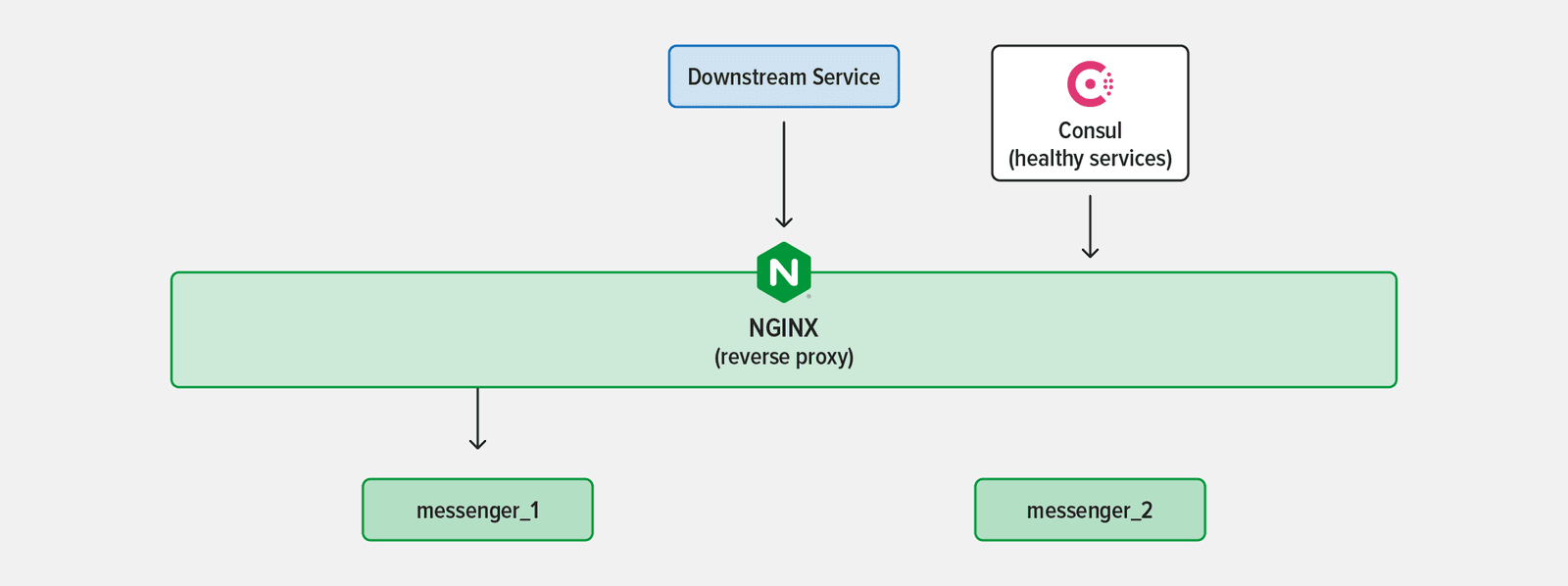
NGINX can query a registry like Consul using a variety of methods and adjust its routing accordingly. Recall that when acting as a reverse proxy or load balancer NGINX routes traffic to “upstream” servers. Consider this simple configuration:
# Define an upstream group called "messenger_service"
upstream messenger_service {
server 172.18.0.7:4000;
server 172.18.0.8:4000;
}
server {
listen 80;
location /api {
# Proxy HTTP traffic with paths starting with '/api' to the
# 'upstream' block above. The default load-balancing algorithm,
# Round-Robin, alternates requests between the two servers
# in the block.
proxy_pass http://messenger_service;
proxy_set_header X-Forwarded-For $remote_addr;
}
}
By default, NGINX needs to know the precise IP address and port of each messenger instance to route traffic to it. In this case, that’s port 4000 on both 172.18.0.7 and 172.18.0.8.
This is where Consul and Consul template come in. Consul template runs in the same container as NGINX and communicates with the Consul client which maintains the service registry.
When registry information changes, Consul template generates a new version of the NGINX configuration file with the correct IP addresses and ports, writes it to the NGINX configuration directory, and tells NGINX to reload its configuration. There is no downtime when NGINX reloads its configuration, and the new instance starts receiving traffic as soon as the reload completes.
With a reverse proxy such as NGINX in this kind of situation, there’s a single touch point to register with the system as the place for other services to access. Your team has the flexibility to manage individual service instances without having to worry about other services losing access to the service as a whole.
Get Hands-On with NGINX and Microservices March
Microservices admittedly increase complexity, both in technical terms for your services and organizational terms for your relationships with other teams. To enjoy the benefits of a microservices architecture it is important to critically reexamine practices designed for monoliths to make sure that they are still providing the same benefits when applied to a very different environment. In this blog, we explored how Factor 3 of the twelve‑factor app still provides value in a microservices context but can benefit from small changes to how it is concretely applied.
To learn more about applying the twelve‑factor app to microservices architectures, check out Unit 1 of Microservices March 2023 (coming soon on the blog). Register for free to get access to a webinar on this topic and a hands‑on lab.

About the Author
Related Blog Posts

Automating Certificate Management in a Kubernetes Environment
Simplify cert management by providing unique, automatically renewed and updated certificates to your endpoints.

Secure Your API Gateway with NGINX App Protect WAF
As monoliths move to microservices, applications are developed faster than ever. Speed is necessary to stay competitive and APIs sit at the front of these rapid modernization efforts. But the popularity of APIs for application modernization has significant implications for app security.
How Do I Choose? API Gateway vs. Ingress Controller vs. Service Mesh
When you need an API gateway in Kubernetes, how do you choose among API gateway vs. Ingress controller vs. service mesh? We guide you through the decision, with sample scenarios for north-south and east-west API traffic, plus use cases where an API gateway is the right tool.
Deploying NGINX as an API Gateway, Part 2: Protecting Backend Services
In the second post in our API gateway series, Liam shows you how to batten down the hatches on your API services. You can use rate limiting, access restrictions, request size limits, and request body validation to frustrate illegitimate or overly burdensome requests.
New Joomla Exploit CVE-2015-8562
Read about the new zero day exploit in Joomla and see the NGINX configuration for how to apply a fix in NGINX or NGINX Plus.
Why Do I See “Welcome to nginx!” on My Favorite Website?
The ‘Welcome to NGINX!’ page is presented when NGINX web server software is installed on a computer but has not finished configuring