

This post is adapted from a webinar by Owen Garrett, introduced by Andrew Alexeev.
Table of Contents
Introduction
0:00 Introduction1:22 About This Webinar2:17 Basic Principles of Content Caching2:35 Basic Principles3:59 Mechanics of HTTP Caching7:46 What Does NGINX Cache?
Content Caching and NGINX
9:55 NGINX in Operation10:06 NGINX Config11:14 Caching Process15:32 Caching is Not Just for HTTP17:10 How To Understand What’s Going On17:38 Cache Instrumentation19:08 Cache Instrumentation (Cont.)20:09 Cache Status21:57 How Content Caching Functions in NGINX22:40 How It Works23:53 How is Cached Content Stored?26:36 Loading Cache From Disk28:07 Managing the Disk Cache29:22 Purging Content From Disk
Controlling Caching
31:27 Controlling Caching32:30 Delayed Caching34:45 Control Over Cache Time36:18 Cache / Don’t Cache37:25 Multiple Caches39:07 Quick Review – Why Cache?39:44 Why is Page Speed Important?40:46 Google Changed the Rules41:28 The Costs of Poor Performance43:00 NGINX Caching Lets You45:21 Closing Thoughts
Q&A
47:20 Byte‑Range Requests49:13 Proxy Cache Revalidation50:07 Spreading the Cache Across Equal Disks50:50 Vary Header51:25 Caching Primitives51:52 Upstream Headers and Data52:13 *‑Encoding Headers52:56 SPDY53:15 Vary Header, Round 253:45 PageSpeed54:00 Other Caches
0:00 Introduction

Andrew Alexeev: Welcome to our latest webinar; my name is Andrew. NGINX was written by Igor Sysoev with the idea of helping the world’s websites run faster, be more responsive, and be easily scalable. Today, NGINX powers over 30% of the top sites and over 20% of all websites on the Internet. [Editor – These statistics applied when the webinar was delivered in May 2014; see the current values here.] I’m hoping you will find the content of this webinar useful and applicable to your existing or planned NGINX environment.
Now allow me to introduce Owen Garrett to you. Owen is responsible for the product development here at NGINX. Today, Owen is going to talk about how can you apply powerful caching mechanisms in NGINX to free your application from the burden of generating repetitive content over and over again.
1:22 About This Webinar

Owen Garrett: Thank you, Andrew, and folks, thank you very much for joining us for the next 45 or 50 minutes. I’ll talk through how NGINX functions with respect to content caching, we’ll look at some of the ways that you can improve performance, we’ll do a little bit of a deep dive into how content caching really works so that you’re equipped to debug and diagnose what’s happening within NGINX, and I’ll round up with some clever hints and tips to give you some really fine‑grained control over what NGINX does with content that can be cached.
All aiming towards the same core reasons, as Andrew described, to take away the burden from your upstream servers of generating repetitive content so they’re freed up to run the applications that your business really needs. Increase beyond those servers, giving your end users a better level of service and increasing the reliability of your service as a hole in the face of big spikes of traffic from the Internet and, potentially, failures of upstream servers.
2:17 Basic Principles of Content Caching

Before we go into NGINX’s implementation configuration, I’d like to just quickly review essentially how content caching functions so that we’re all starting from the same page, from the same baseline of core information.
2:35 Basic Principles
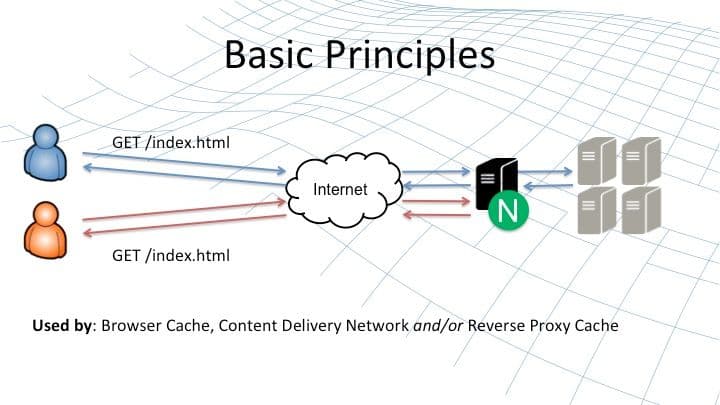
The basic principle of content caching is to offload repetitive work from the upstream servers. When the first user requests an item of content on the website (illustrated by the blue icon and blue lines), his or her HTTP request is forwarded to NGINX, and from there onto the upstream server in gray on the right‑hand side.
The response is forwarded back to the remote user, but if it is cacheable (and we’ll talk about what that means shortly), then NGINX stores a copy of that response. When another user, the orange chap, comes along asking for the same content, then NGINX can serve that directly from its local cache rather than forging the request from the upstream server.
This basic principle of storing cacheable, unchanging content is used by your web browser, by a CDN, the sites you’re accessing, leverage CDNs, and by NGINX on other devices. It operates as reverse proxy cache, typically deployed in the data center or on the cloud next to the origin servers that are hosting your web content and web applications.
3:59 Mechanics of HTTP Caching

The origin server declares the cacheability of content using one or more of several, well‑understood, well‑known HTTP response headers. Of course, caching servers can choose to ignore or override or change this behavior. But in order to understand configured content caching, you really need to begin with a good understanding of the way that an origin server will indicate that content is cacheable, it’s unchanging, and that the [cached] copy has a certain lifetime.
Content caching began with a simple HTTP response header called Expires. The origin server would present some content and declare that content would be valid until the date in the Expires header. That method was quickly overtaken by a more effective and more flexible method – the Cache-Control header.
Expires is somewhat clumsy to use; it’s inefficient. Dates need to be properly formatted and parsed whereas Cache-Control is much more streamlined and aligned with the needs and the speed of content caches. Cache-Control declares content as either public or private and in the case of it being public, declares a max-age – the number of seconds that it can be cached before the caching object needs to re‑request that content.
The third header that directly controls caching is X-Accel-Expires. This header is special to NGINX; only NGINX understands it and it’s used if you want to override the behavior of the above headers and tell NGINX directly precisely how long an item of content should be cached for.
There are situations where you may want the web browser to cache content for a long period of time, but you’re happy for the proxy cache (NGINX sitting in front of the origin server) to cache it for a shorter period of time so that changes are reflected more quickly and pushed out to new clients, whereas old clients don’t keep re‑requesting the content when they don’t need to.
However, that method can also be implemented using the last two headers. An origin server can declare when an item of content was last modified and it can declare a thing called an ETag (entity tag) – an opaque string, often a hash value, which identifies that content.
Clients can then make requests using conditional GETs. They can include an If-Modified-Since or If-None-Match header in their request. By doing that, the client is declaring they have a cached version of the content that was last modified a particular date or has a particular ETag. If the most recent version that the server holds matches the version the client has, then the server responds simply with a 304 Not Modified. This is a fast response that saves on network bandwidth and allows the client to check at its leisure whether the cached copy of content is still valid.
These five headers define from an origin server’s perspective how content is cacheable – its validity, its freshness, and in terms of the ETag, the details of the content itself.
7:46 What Does NGINX Cache?

Proxy caches such as NGINX are relatively free to interpret how strictly they will comply with those headers. Clearly they shouldn’t cache something which is not cacheable, but of course they’ve got no obligations to cache something if the origin server says it is cacheable.
The basic NGINX behavior is to cache all GET and HEAD requests that are indicated by the origin server as being cacheable, provided there are no Set-Cookie headers in the response. That’s because Set-Cookie headers typically include unique data specific to each request and by default it wouldn’t be appropriate to cache that value.
NGINX caches each resource by a particular key – a cache key. All requests that generate the same cache key will be satisfied with the same resource. By default, the cache maps onto the raw URL or, in the configuration, the string illustrated on this slide [$scheme$proxy_host$uri$is_args$args]. At the time that NGINX caches content, [the validity lifetime] is defined (in order of preference) by the X-Accel-Expires header if present or the Cache-Control header or the legacy Expires header.
You can tune NGINX to mask out certain of these headers or to provide a fixed cache time instead, completely irrespective of what the origin server says. For reference, RFC 2616 defines the desired behavior of a proxy cache with respect to HTTP.
So this gives you a brief flavor of the universality of caching and the basic default behavior of NGINX in caching content that is typically safe to cache, in order to accelerate your website and take load off your origin servers.
9:55 NGINX in Operation

Now let’s have a little look at NGINX in operation. It’s really, really easy to configure NGINX to enable content caching.
10:06 NGINX Config

It’s a couple of lines in your NGINX configuration file – one to create a cache on disk with a certain set of parameters declaring how files are laid out, the expiration time [for objects in that cache], and the size of that cache. Then the second, the proxy_cache directive, is associated with an NGINX proxy and tells it that the content (results, responses) should be cached in a named cache.
So here, I’ve created one cache called one; it’s 10 MB in size in memory for metadata but unlimited in size on disk for content that’s cached. Content is cached and then reaped if it’s been inactive for 60 minutes. That cache called one is used by our default server. These two [directives], proxy_cache_path and proxy_cache, are sufficient to enable reliable, consistent caching for a proxy server in NGINX.
11:14 Caching Process
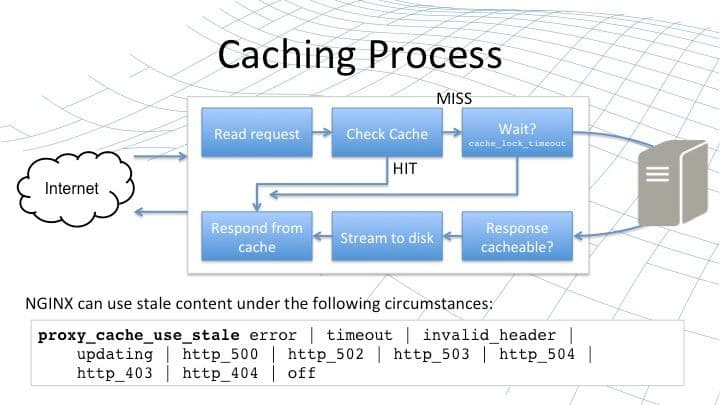
The process that NGINX undergoes when it receives a request and it queries a cache is defined as follows. We begin by reading a request (top‑left box on this slide), assembling the cache key to the raw URI and the other parameters that we’re going to use to identify the resource corresponding to that request. Then we check the cache on disk by accessing the metadata in memory to see if we have a valid, fresh copy of the response for that request.
If we do, that counts as a hit. Then NGINX can respond directly from the cache. It responds from the cache by serving the content from disk exactly as NGINX serves static content. So you get the level of performance, reliability, and scalability that NGINX is designed for. With static content, you get exactly the same degree [of performance] when you serve content from NGINX’s content cache.
On the other hand, when we check the cache, we may have a cache miss. This means we don’t have the content in the cache, or the content in the cache is out of date and it needs to be refreshed. In the simplest case then, that miss means that we would go and request that content from the origin server, receive the response, and check if it’s cacheable.
If it is, we stream it to disk just as NGINX does for any large response handled in proxy mode. Then once it [the response] streams to disk, we copy it into the cache and respond directly from the cache. One of the challenges with this approach is if NGINX receives multiple requests for the same content at the same time and they all result in a miss.
NGINX would normally forward all of those requests on to the origin server, potentially overloading it – particularly for requests that take a long time to generate responses for. So for that reason, you can use a cache lock. The proxy_cache_lock directive ensures that if a piece of content is being refreshed, only one request at a time is sent to the upstream server.
So in the scenario that I described, the first request would go to the upstream server but the remaining requests for the same content will be held back until either the response has been served and has been inserted into the cache (at which point all requests can be satisfied), or a timeout is hit [set by the proxy_cache_lock_timeout directive] – NGINX has waited long enough for content to come back from the server and then at that point, the requests you released are forwarded to the origin server.
So the proxy_cache_lock and the timeout gives you some powerful control to ensure that when you have a busy site with many requests for the same content, if that content expires in the cache, you don’t suddenly overload the origin server with multiple requests.
There’s one more element to the caching process in NGINX that doesn’t fit cleanly into this flowchart because it covers almost every stage of the chart. That’s the capability configured with the proxy_cache_use_stale directive. At any point, if one of these stages fails for some reason, for example when we’re updating the content and we hit a timeout or we get a bad response from the upstream server or some other type of error, we have the option of responding directly from the cache even if the cached content is stale.
This is a really powerful tool in case your upstream servers are overwhelmed by traffic or they fail due to maintenance or catastrophic error. It ensures that NGINX can continue to deliver your content using the stale content from the cache rather than returning an error message back to the client.
15:32 Caching is Not Just for HTTP

Caching in NGINX isn’t just for HTTP. NGINX is much more than just an HTTP proxy that forwards requests on to upstream web servers. Generally those upstream web servers are there to interface with APIs like FastCGI or SCGI. NGINX can do that directly in a proxy fashion very similar to the HTTP proxy.
NGINX can employ its caching techniques for HTTP proxies, for FastCGI proxies, for uWSGI proxies, and for SCGI proxies. All operate in much the same sort of fashion as the HTTP proxy, with caches stored on disk and direct responses, avoiding the need to proxy to these upstream services.
NGINX can also interface with a memcached server; this is a slightly different caching approach. In this case, NGINX doesn’t store content directly, it uses memcached as a proxy and it relies on an external agent to populate memcached with the content that’s needed. This can be another useful tool, and there are plenty of ways to populate memcached from an external site if necessary. So you could regard this as a way of seeding a cache for NGINX if that’s your business requirement.
17:10 How To Understand What’s Going On

Caching can potentially be very complex if you have a large infrastructure with multiple tiers, some doing caching, some not doing caching, some generating content, some not; then it can be quite a challenge to begin to track what’s going on – where content is coming from – and diagnose and debug any problems that you hit. In NGINX, we make it as easy as we can for you.
17:38 Cache Instrumentation

With some sophisticated instrumentation, you have the ability to control the instrumentation dynamically to track where content is coming from, where it’s stored in the cache, and what the status is in the cache.
The first step is the $upstream_cache_status variable, which is calculated for each request that NGINX has responded to, whether it’s from cache or not. And you continually add the value of that variable to your response using the add_header directive. Conventionally, we put that value in an X-Cache-Status header in the response. It can take one of seven different values, declaring how that piece of content was served. Whether it bypassed the cache, whether it came from a revalidate, whether it was a hit.
This is your first step in trying to understand where your responses are coming from. Are they coming from the local NGINX cache, or have they come from an upstream server? And you can inspect that response header in a variety of ways – from the command line using tools like curl, or very commonly in your web browser using interactive debuggers.
Of course you may not want to declare that value to all of your end users. You would want to be selective as to when you insert that value into the header response.
19:08 Cache Instrumentation (Cont.)

NGINX’s configuration language gives you the flexibility to be selective. This example shows just one of the many ways that you can do this. We take the remote address and if it happens to be localhost, then we’ll put the $upstream_cache_status into a temporary variable ($cache_status). Finally, when we serve a response back, we put temporary variable into the response.
This way, only requests from selective IP addresses will see the value of the $upstream_cache_status variable. You can do lots of other things as well; shortly, we’ll look at how content is stored on disk. You can put the key that is used to calculate the location on disk into the response. You can put all all sorts of parameters in the response to help you diagnose the cache as it’s running.
20:09 Cache Status

NGINX Plus, our commercial version of NGINX, provides a number of additional features that help with use cases like caching. NGINX Plus is a commercially supported build of NGINX built by our engineering team in Moscow and run through an extensive set of regression tests to ensure correct operation.
NGINX Plus also contains a number of features targeted at enterprises who are looking to use NGINX as a reverse proxy and load balancer. Features around load balancing, health checks, advanced video streaming. And in the context of this, features around extended status, better diagnostics, and visualization of what’s happening in NGINX.
[Editor – The slide above and the following paragraph have been updated to refer to the NGINX Plus API, which replaces and deprecates the separate status module originally discussed here.]
For a demo, you can jump onto demo.nginx.com/dashboard.html and you’ll see a web page that displays the status data that is published from NGINX Plus using the NGINX Plus API. And if you run the indicated curl command, you’ll see the raw JSON data that is taken directly from the NGINX Plus binary (here it is piped to the jq utility to put each element on its own line and indented hierarchically).
In that JSON data you’ll find real‑time data about the state of each of the caches in your NGINX Plus deployment. This, along with the $upstream_cache_status variable and the other ways that you can instrument the cache, give you a really good overview as to how NGINX caches content and allows you to drill down into individual requests, to figure out whether that request came from the cache or not and the current status within the cache.
21:57 How Content Caching Functions in NGINX

Now, having looked at how we can examine contact caching from the outside, let’s have a look at it from inside. How does it function within NGINX? As I mentioned earlier, the content cache in NGINX functions in much the same way as files on disk are handled. You get the same performance, the same reliability, the same operating system optimizations when you’re serving content from our content cache as you do when you serve static content – the performance that NGINX is renowned for.
22:40 How It Works

The content cache is stored on disk in a persistent cache. We work in conjunction with the operating system to swap that disk cache into memory, providing hints to the operating system page cache as to what content should be stored in memory. This means that when we need to serve content from the cache, we can do so extremely quickly.
The metadata around the cache, information about what is there and its expiration time, is stored separately in a shared memory section across all the NGINX processes and is always present in memory. So NGINX can query the cache, search the cache, extremely fast; it only needs to go to the page cache when it needs to pull the response and serve it back to the end user.
We’ll look at how content is stored in the cache, we’ll look at how that persistent cache is loaded into empty NGINX worker processes on startup, we’ll look at some of the maintenance NGINX does automatically on the cache, and we’ll round up by looking at how you can manually prune content from the cache in particular situations.
23:53 How is Cached Content Stored?
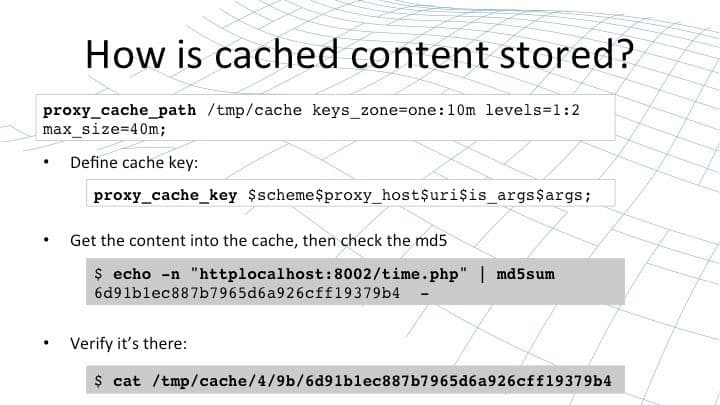
You recall that the content cache is declared using a directive called proxy_cache_path. This directive specifies the number of parameters: where the cache is stored on your file system, the name of the cache, the size of the cache in memory for the metadata, and the size of the cache on disk. In this case there’s a 40 MB cache on disk.
The key to understanding where the content is stored is understanding the cache key – the unique identifier that NGINX assigns to each cacheable resource. By default that identifier is built up from the basic parameters of the request: the scheme, Host header, the URI, and any string arguments.
But you can extend that if you want using things like cookie values or authentication headers or even values that you’ve calculated at runtime. Maybe you want to store different versions for users in the UK than for users in the US. This all possible by configuring the proxy_cache_key directive.
When NGINX handles a request, it will calculate the proxy_cache_key and from that value it will then calculate an MD5 sum. You can replicate that yourself using the command line example I’ve shown further down the slide. We take the cache key httplocalhost:8002/time.php and pump that through md5sum. Be careful, when you’re doing this from the shell, not to pump a new line through as well.
That will calculate the MD5 hash value that corresponds to that cacheable content. NGINX uses that hash value to calculate the location on disk that content should be stored. You’ll see in the proxy_cache_path that we specify a two‑level cache with a one‑character and then a two‑character directory. We pull those characters off the end of the string to create a directory called 4 and subdirectory called 9b, and then we drop the content of the cache (plus the headers and a small amount of metadata) into a file on disk.
You can test the content caching. You can print out the cache key as one of the response headers, you can pump it through md5sum to calculate the hash correspondence of that value. Then you can inspect the value on disk to see it’s really there and the headers that NGINX cached, to understand how this all fits together.
26:36 Loading Cache From Disk

Now that content is stored on disk and is persistent, when NGINX starts it needs to load that content into memory – or rather, it needs to work its way through that disk cache, extract the metadata, and then load the metadata into memory in the shared memory segment used by each of the worker processes. This is done using a process called the cache loader.
A cache loader spins up at startup and runs once, loading metadata onto disk in small chunks: 100 files at a time, sandboxed to 200 ms, and then pausing for 50 ms in between, and then repeating until it’s worked its way through the entire cache and populated the shared memory segment.
The cache loader then exits and doesn’t need to run again unless NGINX is restarted or reconfigured and the shared memory segment needs to be reinitialized. You can tune the operation of the cache loader, which may be appropriate if you have very fast disks and a light load. You can make it run faster or perhaps you might want to wind it back a little bit if you’re storing a cache with a huge number of files and slow disks and you don’t want the cache loader to use excessive amounts of CPU when NGINX starts up.
28:07 Managing the Disk Cache

Once the cache is in memory and files are stored on disk, there’s a risk that cached files that are never accessed may hang around forever. NGINX will store them the first time it sees them, but if there are no more requests for a file, then [the file] will just sit there on disk until something comes along and cleans it out.
This something is the cache manager; it runs periodically, purging files from the disk that haven’t been accessed within a certain period of time, and it deletes files if the cache is too big and has overflowed its declared size. It deletes them in a least‑recently used fashion. You can configure this operation using parameters to the proxy_cache_path [directive], just as you configure the cache loader:
- The
inactivetime defaults to 10 minutes. - The
max-sizeparameter has no default limit. If you impose amax-sizelimit on the cache, at times it may exceed that limit but when the cache manager runs it will then prune the least recently used files to take it back underneath that limit.
29:22 Purging Content From Disk

Finally there are times that you may wish to purge content from disk. You want to find a file and delete it; it’s relatively easy to do if you know the techniques that we talked about earlier – running the cache key through md5sum – or just running a recursive grep across the file system to try to identify the file or files that you need to delete.
Alternatively, if you’re using NGINX Plus, you can use the cache purge capability built into that product. The cache purge capability allows you to take a particular parameter from the request; generally we use a method called PURGE as the way to identify that it’s a cache‑purge request.
Purging is handled by a special NGINX Plus handler which inspects the URI and deletes all of the files that match that URI from the cache. The URI can be suffixed with an asterisk so that it becomes a stem. In this case, we’re going to use the purge capability to delete every single file that’s served up from localhost host port 8001, but of course you could put subdirectories as well.
Whichever method you use, at any point you are entirely safe to delete files from the cache on disk or even rm -rf the entire cache directory. NGINX won’t skip a beat; it’ll continue to check for the presence of files on disk. If they’re missing, then that creates a cache miss. NGINX will then go on and retrieve the cache from the origin server and store it back on the cache on disk. So it’s always safe and reliable and stable if you need to wipe individual files from the cache.
31:27 Controlling Caching

So we’ve looked at how caching works, we’ve looked at the implementation within NGINX, and done a deep dive as to how it stores files on disk to get the same sort of performance that it gets with static content. Now let’s get a little bit smarter about caching.
For simple sites, you can turn caching on and generally it will do precisely what it needs to do to keep giving you the level of performance and the cache behavior that you want. But there are always optimizations to be made and there are often situations where the default behavior doesn’t match the behavior that you want.
Perhaps your origin servers are not setting the correct response headers or perhaps you want to override what they’re specifying inside NGINX itself. There are a myriad of ways you can configure NGINX to fine‑tune how caching operates.
32:30 Delayed Caching

You can delay caching. This is a very common situation if you have a large corpus of content much of which is only accessed once or twice in an hour or a day. In that case, if you have your company brochure that very few people read, it’s often a waste time trying to cache that content. Delayed caching allows you to put a watermark in place. It will only store a cached version of this content if it’s been requested a certain number of times. Until you’ve hit that proxy_cache_min_uses watermark, it won’t store a version in the cache.
This allows you to exercise more discrimination for what content goes in your cache. The cache itself is a limited resource, typically bounded by the amount of memory that you have in your server, because you’ll want to ensure that the cache is paged into memory as far as possible. So you often want to limit certain types of content and only put the popular requests in your cache.
Cache revalidation is a feature that was recently added to NGINX Open Source and NGINX Plus. It modifies the If-Modified-Since capability so that when NGINX needs to refresh a value which has been cached, it doesn’t make a simple GET to get a new version of that content; it makes a conditional GET, saying, “I have a cached version that was modified on this particular time and date”.
The origin server has the option of responding with 304 Not Modified, effectively saying the version you have is still the most recent version there is. That saves on upstream bandwidth; the origin server doesn’t have to resend content that hasn’t changed and it saves potentially on disk writes as well. NGINX doesn’t have to stream that contact to the disk and then swap it into place, overwriting the old version.
34:45 Control Over Cache Time

You have fine‑grained control over how long content should be cached for. Quite often, the origin server will serve content up with cache headers that are appropriate for the browsers – long‑term caching with a relatively frequent request to refresh the content. However, you might like the NGINX proxy sitting directly in front of your origin server to refresh files a little bit more often, to pick up changes more quickly.
There’s a huge increase in load if you reduce the cache timeout for the browsers from 60 seconds to 10 seconds, but there’s a very small increase in load if you increase the cache timeout in NGINX from 60 seconds to 10 seconds. For each request, that will add five more requests per minute to your origin servers whereas with the remote clients, it all depends on the number of clients with similar things active on your site.
So, you can override the logic and the intent that your origin server says. You can mask out or tell NGINX to ignore certain headers: X-Accel-Expires, Cache-Control, or Expires. And you can provide a default cache time using the proxy_cache_valid directive in your NGINX configuration.
36:18 Cache / Don’t Cache

Sometimes you may not cache content that the origin server says is cacheable, or you may want to ensure that you bypass the version of content stored in NGINX. The proxy_cache_bypass and proxy_no_cache directives give you that degree of control.
You can use them as a shortcut to say that if any of a certain set of request headers are set, such as HTTP authorization, or a request parameter is present, then you want to bypass the cache – either to automatically update the cache in NGINX or to just skip it completely and always retrieve it from the origin server.
Typically these are done for fairly complex caching decisions, where you’re making fine‑grained decisions over the values of cookies and authorization headers to control what should be cached, and what should always be received from the origin server, and what should never be stored in the NGINX cache.
37:25 Multiple Caches

Finally, for very large scale deployments you might want to explore multiple caches within an individual NGINX instance, for a couple of reasons. You might have different cache policies for different tenants on your NGINX proxy, depending on the nature of your site and depending on the importance of the performance of that site – even depending on the particular plan that each tenant is signed up for in a shared hosting situation.
Or you may have multiple disks in the NGINX host and it’s most efficient to deploy an individual cache on each disk. The golden rule is to minimize the number of copies from one disk to another and you can do that by pinning a cache to each disk and pinning the temp file for each proxy that uses that cache to the correct disk.
The standard operation is that when NGINX receives content from an upstream proxy, it will stream that content to disk unless it’s sufficiently small and it fits in memory. Then once that content streams to disk, it will then move it into the cache. That operation is infinitely more efficient if the location on cache for the temp files (the disk where the temp files are stored) is the same as the disk where the cache is stored.
39:07 Quick Review – Why Cache?

So we talked about caching, we’ve talked about the methods that NGINX uses, the implementation within NGINX, and ways that you can tune it. As we get close to winding up, let’s have a quick review to remind ourselves why you want to cache content in the first place. NGINX is deployed on a 114 million websites worldwide and many of these users deploy NGINX because of its web acceleration and content caching capabilities. [Editor – This statistic applied when the webinar was delivered in May 2014.]
39:44 Why is Page Speed Important?
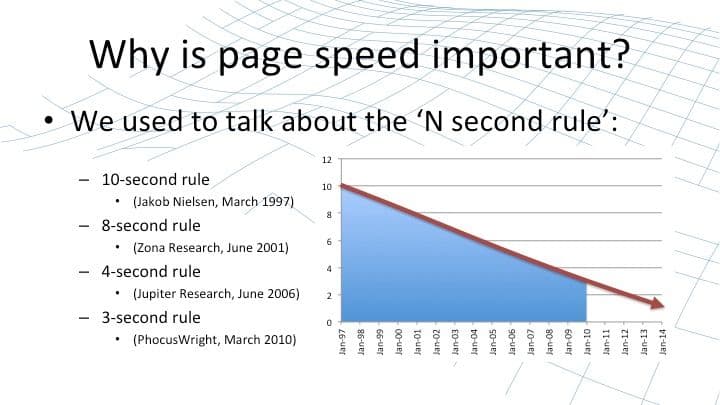
These capabilities improve speed of a website – they give end users a better level of experience – and web page speed is really, really important. For years and years, analysts have been monitoring user behavior and coming up with what’s colloquially know as the “N second rule”. This is how long an average user is prepared to wait for page to load and render before he or she gets bored and impatient and moves to a different website, to a competitor.
As standards have improved and user expectations have gotten higher and higher, the period that users are prepared to wait is dropping and dropping. You could, through some slightly dubious maths, extrapolate that on and conclude that users will have a negative level of patience by about 2016.
40:46 Google Changed the Rules

But in fact, technology has overtaken us. Google illustrated this graphically a couple of years ago when introducing Google Instant Search. Now with Google, when you type a search term in a search box, even before you finish typing Google is presenting candidate search results. This illustrates the huge shift in expectations on the modern Internet. As Google itself has said, “users now expect web pages to react in the same way that turning pages in the book react” – as quickly and as seamlessly and as fluidly.
41:28 The Costs of Poor Performance
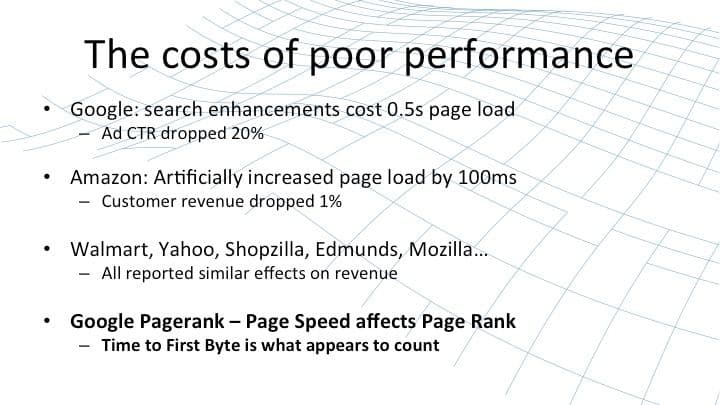
If you fail to meet that level of performance, then there can be significant impacts on the KPI that you attach with your website or web service. Whether it’s ad click‑through rates: Google themselves find that their ad clickthrough rate dropped 20% when their search pages took a half a second further to load. Whether it’s revenue: in a deliberate attempt to investigate the effect of slow web pages, Amazon deliberately increased page load in multiples of a 100 ms and found that the revenues from those affected customers typically dropped by 1% for each 100 ms increase.
Many other analysts, websites, and investigators reported similar effects on the metrics for a website, whether that be time on page, bounce rate, etc. Most recently, Google has started taking page speed into effect when they calculate page rank in search results. What appears to count is the time to first byte. The longer it takes to get the first byte of a page load, the more heavily your page rank is penalized. A website may suffer from the situation that it’s not even accessed because it appears on page three, four, or five of the Google search results.
43:00 NGINX Caching Lets You

The caching capabilities of NGINX allow you to improve the end‑user experience by reducing time to first byte and by making web content feel snappier and more responsive.
NGINX allows you to consolidate and simplify your web infrastructure. NGINX is not just a standalone web cache. NGINX includes a web origin server, it includes a direct gateway to APIs like FastCGI, and in NGINX Plus, it includes the capabilities to construct a sophisticated, enterprise‑ready load balancer and application delivery controller. This allows you to consolidate multiple different network components in your web infrastructure into a single component – NGINX or NGINX Plus – giving you more reliable, easier to debug, faster solutions.
NGINX allows you to increase server capacity by taking repetitive tasks away from the upstream servers. In fact, even for content which appears to be uncacheable (the front page of a blogging site, for example), there’s merit in caching that just for a second on the NGINX proxy.
When a hundred users request the same content in the same second, NGINX will reduce that down to a single request to the origin server and it will serve content back to those users from its cache with a promise that that content is never more than one second out of date. That’s often more than enough for a blog site or a similar website, yet makes a huge difference in performance – both in the load on the upstream servers and the expense that you have in managing and deploying sufficient capacity.
Finally, don’t forget one of the strategic uses of NGINX: to insulate you from failures of upstream servers through the proxy cache’s “use stale” capability. If they’re running slow, if they’re returning errors, if there’s some sort of fault, then NGINX can fall back to the local cached version of the content and continue to use that until your upstream servers recover.
45:21 Closing Thoughts

38% of the world’s busiest websites use NGINX predominantly for its web‑acceleration and content‑caching capabilities. [Editor – This statistic applied when the webinar was delivered in May 2014; see the current value here.] For more solutions and more details, check out the blogs and the feature briefs at nginx.com, which speak to capabilities in NGINX and NGINX Plus. And take a look at our webinar list, not just future webinars but also soon to be added webinars from past events in this series.
And if you’d like to investigate these capabilities further, of course there’s the documentation and solutions that you can find at nginx.org and nginx.com, but nothing beats taking the download and trying it out. The open source product can be found at nginx.org, or the commercial, supported product with additional load balancing, application delivery, management, and ease‑of‑use features at nginx.com.
So folks, thank you very much for your time and your attention. I hope that this presentation and run‑through of content caching in NGINX has been useful and illuminating for many of you.
Q&A
Let’s start working through the questions and see how we do.
47:20 Byte‑Range Requests
We have a question about byte‑range requests. Byte‑range requests are used when a client requests a piece of content, but only needs a subset of that content. Say it’s a video file and the client only needs part of the video. Or very commonly it’s a PDF file: the user has read the headers that have an index into the PDF file, and the client just wants to download a certain set of pages. How does that function in NGINX’s content cache?
The process is as follows. When NGINX receives a byte‑range request for a resource and the entire resource is already in the cache, NGINX will respond from the cache with the byte range the client has requested. If that resource is not in the cache, NGINX will make a request for the entire resource to the upstream server and it will store that resource in the cache. Currently, at that point NGINX will not obey the byte‑range request and it will return the entire resource back to the client. In most situations, that’s acceptable behavior.
For example, if a client is downloading a PDF document, its first request will be for the entire document anyway and it’s only if that document is streamed, the client aborts the connection and starts making byte‑range requests. So, for cached content NGINX honors byte‑range requests. For uncached content, NGINX retrieves the entire content from the upstream server and returns the entire content back to the client in that one instance.
49:13 Proxy Cache Revalidation
This is a question about the proxy cache revalidate capability. This is the capability that allows NGINX to make a conditional GET to the upstream server to check whether content has changed. The question is:
Does proxy cache revalidation factor in ETags or just the If-Modified-Since date of the content?
The answer is it just checks the If-Modified-Since date of the content, and as a point of practice, it’s generally good practice to always include If-Modified-Since in your responses and treat ETags as optional because they’re not as consistently or as widely handled as the “last modified” date that you’ll handle in response.
50:07 Spreading the Cache Across Equal Disks
Is it possible for NGINX to load balance its caching for a single site between a few equal disks for best performance?
Yes it is; it takes a little bit of work. The typical scenario is to deploy a bunch of disks with no RAID, and then deploy individual caches, one pinned to each disk. It requires some additional configuration and partitioning of the traffic. If you want some help configuring that, then either reach out to our community and we’ll deal with your specific request there, or if you’re using NGINX Plus, reach out to our support team and we’ll be delighted to help.
50:50 Vary Header
Does NGINX factor the Vary header into cache hit and miss?
No, NGINX does not automatically handle Vary headers. If that’s an issue, then it’s simple to add the Vary header to the proxy cache key so that the unique key that’s used to store the response includes the value of the Vary header. Then you can store multiple different versions.
51:25 Caching Primitives
Are all the caching primitives and directives being respected?
In general, yes. There are a couple of edge cases such as Vary headers, which are not respected. In many cases, there is a degree of latitude in how various caches interpret the requirements of the RFC. Where possible, we’ve gone for implementations that are reliable, consistent, and easy to configure.
51:52 Upstream Headers and Data
Are both upstream headers and data being cached?
Yes, they are. If you receive a response from the cache, then the headers are cached as well as the response body.
52:13 *‑Encoding Headers
The header values are cached as well as the response body, so … I’d be fairly amazed if NGINX didn’t operate correctly with the various different combinations of Transfer-Encoding. Accept-Encoding is often implemented through a Vary header, so the earlier comments about needing to put Vary headers into your cache key applies there (in the case of clients that don’t support that).
52:56 SPDY
Does caching work for SPDY?
Absolutely. You can think of it as a frontend proxy for NGINX, although in practice it’s very, very deeply intertwined in the NGINX kernel. Yes, SPDY works for caching.
53:15 Vary Header, Round 2
Here’s another question about the Vary header. To confirm, if you’re using Vary‑header responses and gzips, then take a look at some of the discussions on Trac or on our community site for solutions for that. The most common approach is to embed the Vary header in the cache key.
53:45 PageSpeed
Q: Does PageSpeed use NGINX caching or its own caching mechanism?
That’s a question that you would need to share with the PageSpeed developers.
54:00 Other Caches
Q: How do other content caches compare to NGINX?
CDNs are very effective content caching solutions. CDNs are deployed as a service; you have more limited control over how content is cached and how it expires within that, but they are a very very effective tool for bringing content closer to end users. NGINX is a very effective tool for accelerating the web application and very commonly, both are deployed together. In the case of stand‑alone caches such as Varnish: once again, they are very very capable technologies that work in a similar fashion to NGINX in many respects. One of the benefits of NGINX is that it brings together origin serving application gateways, caching, and load balancing into one single solution. So that gives you a simpler, more consolidated infrastructure that’s easier to roll out, easier to manage, easier to debug and diagnosed if you have any issues.
To watch the webinar that this post is based on, access it here.
To try NGINX Plus, start your free 30-day trial today or contact us to discuss your use cases.
About the Author

Related Blog Posts

Automating Certificate Management in a Kubernetes Environment
Simplify cert management by providing unique, automatically renewed and updated certificates to your endpoints.

Secure Your API Gateway with NGINX App Protect WAF
As monoliths move to microservices, applications are developed faster than ever. Speed is necessary to stay competitive and APIs sit at the front of these rapid modernization efforts. But the popularity of APIs for application modernization has significant implications for app security.
How Do I Choose? API Gateway vs. Ingress Controller vs. Service Mesh
When you need an API gateway in Kubernetes, how do you choose among API gateway vs. Ingress controller vs. service mesh? We guide you through the decision, with sample scenarios for north-south and east-west API traffic, plus use cases where an API gateway is the right tool.
Deploying NGINX as an API Gateway, Part 2: Protecting Backend Services
In the second post in our API gateway series, Liam shows you how to batten down the hatches on your API services. You can use rate limiting, access restrictions, request size limits, and request body validation to frustrate illegitimate or overly burdensome requests.
New Joomla Exploit CVE-2015-8562
Read about the new zero day exploit in Joomla and see the NGINX configuration for how to apply a fix in NGINX or NGINX Plus.
Why Do I See “Welcome to nginx!” on My Favorite Website?
The ‘Welcome to NGINX!’ page is presented when NGINX web server software is installed on a computer but has not finished configuring