
Red Hat OpenShift Container Platform (OCP) is one of the most popular managed Kubernetes platforms, and like its competitors, OCP includes default traffic management tooling to help users get started quickly. The OCP Router – based on HAProxy – is the default entry point for OCP clusters. It can load balance HTTP and WebSocket traffic, supports TLS termination and TLS between the Router and application instances, and can load balance TLS connections in a passthrough mode.
Customers often ask us, “Why should I use NGINX Ingress Controller in OpenShift when the Router is available for free?” In Why You Need an Enterprise‑Grade Ingress Controller on OpenShift, guest blogger Max Mortillaro of GigaOm shares some qualitative reasons you might want to use NGINX Ingress Controller: advanced traffic management, ease of use, JWT validation, and WAF integration. But it’s also important to answer that question from a quantitative viewpoint, which is why we performance tested the Router and the NGINX Plus-based NGINX Ingress Controller ( nginxinc/kubernetes-ingress) in the OCP environment, in a dynamic deployment in which we scaled the number of upstream (backend) servers up and down during the test.
When we conduct performance tests, we look at two factors to assess how the tools perform:
- Factor 1: Latency Results for Dynamic DeploymentsWe find that the most effective metric for measuring end user experience in a dynamic deployment is the latency percentile distribution. The more latency added by a system, the more the user experience is affected. We’ve also found that to get a true picture of user experience, latencies at upper percentiles in the distribution need to be included; for a detailed explanation, see the Performance Results section of NGINX and HAProxy: Testing User Experience in the Cloud on our blog.
- Factor 2: Timeouts and ErrorsWhen a system under test causes latency in a dynamic deployment, it’s typically because the system has trouble handling dynamic reloads, experiencing timeouts or errors.
Performance Testing Results
Let’s get right to the interesting part and review the results. Details about the testing topology and method follow.
As discussed above, we consider two factors when assessing performance: latency and timeouts/errors.
Factor 1: Latency Percentile Distribution
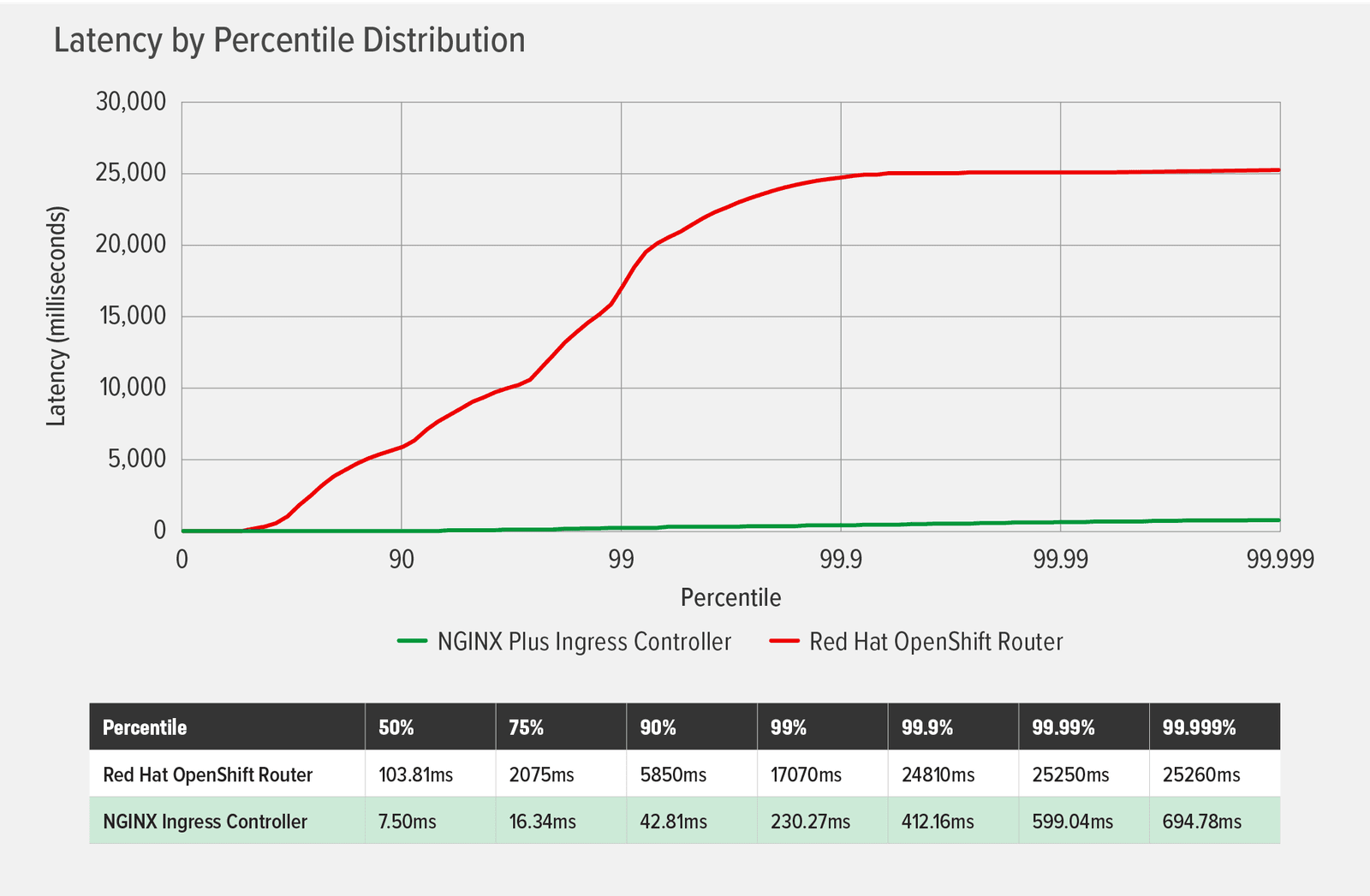
As the following chart illustrates, NGINX Ingress Controller added negligible latency throughout the test, reaching a maximum of less than 700ms at the 99.999th percentile. In contrast, the OCP Router added latency at fairly low percentiles, and latency increased exponentially until it plateaued at a bit more than 25,000ms (25 seconds) at the 99.99th percentile. This demonstrates that, when under load while changes in the cluster environment are applied frequently, the Router can cause a poor user experience.
Factor 2: Timeouts and Errors
The latency observed above can be attributed to timeouts and errors: the OCP Router produced 260 connection timeouts and 85 read‑socket errors, while NGINX Ingress Controller produced none. As we’ve seen with other performance tests (see Performance Testing NGINX Ingress Controllers in a Dynamic Kubernetes Cloud Environment), the Router’s timeouts and errors are caused by the way HAproxy handles dynamic reloads. The NGINX Plus-based NGINX Ingress Controller doesn’t cause timeouts or errors because it uses the NGINX Plus API to dynamically update the NGINX configuration when endpoints change.
Testing Setup and Methodology
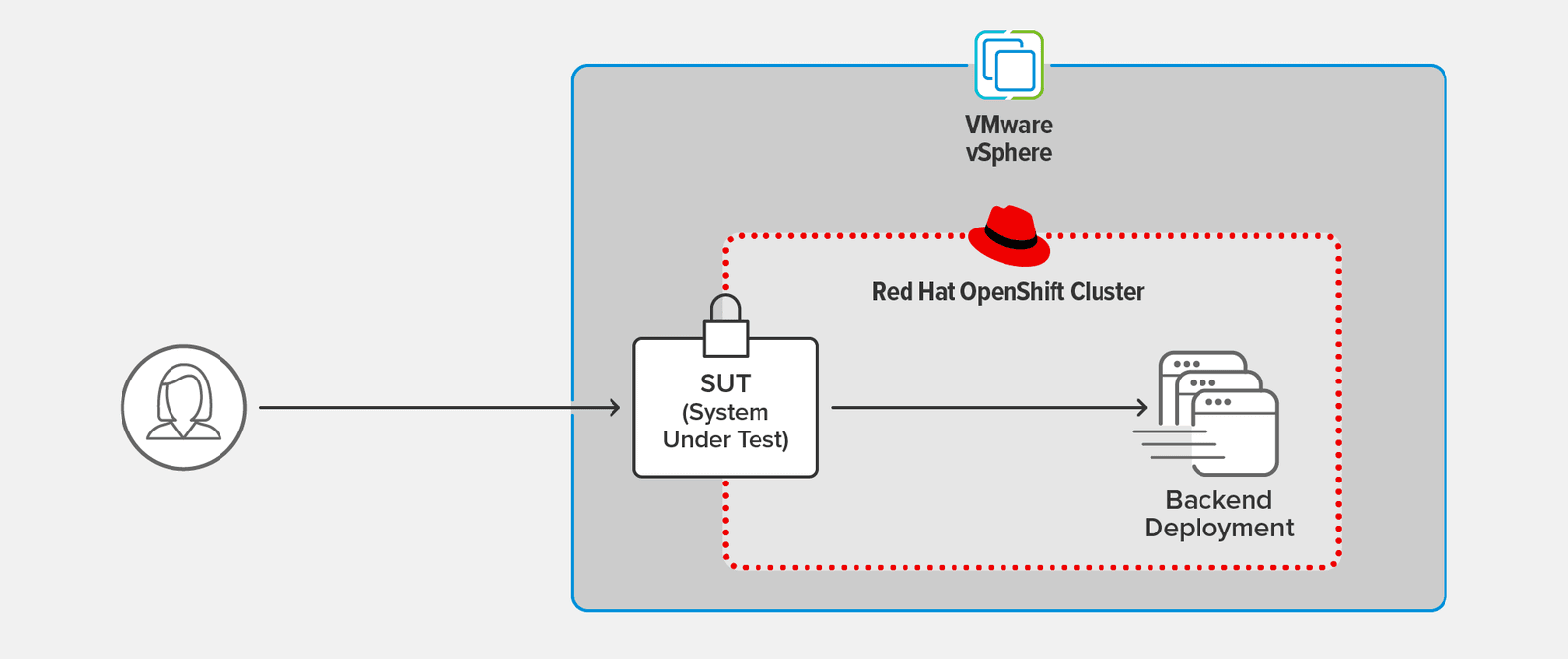
Testing Topology
We ran the same tests on both the NGINX Ingress Controller and the OpenShift Router as the system under test (SUT). The SUT terminated TLS 1.3 connections from the client and forwarded the client request over a separate connection to the backend deployment.
The client was hosted on a separate machine running CentOS 7, located on the same LAN as the OpenShift cluster.
The SUT and backend deployment ran in an OCP cluster hosted on VMware vSphere 6.7.0.45100.
For TLS encryption, we used RSA with a 2048-bit key size and Perfect Forward Secrecy.
Each response from the backend application consisted of about 1 KB of basic server metadata, along with the 200 OK HTTP status code.
Testing Methodology
Client Deployment
Using wrk2 (version 4.0.0), we ran the following script on the client machine, running the test for 60 seconds (set with the -d option) at a constant throughput of 1000 requests per second (RPS, set with the -R option):
./wrk -t 2 -c 50 -d 60s -R 1000 -L https://ingress-url:443/SUT Software Used
- OpenShift Platform version 4.8, which includes the HAProxy‑based Router by default
- NGINX Ingress Controller Version 1.11.0 (NGINX Plus R22)
Backend Deployment
We conducted test runs with a dynamic deployment of the backend application, using the following script to scale the number of backend replicas up and down periodically. This emulates a dynamic OpenShift environment and measures how effectively the NGINX Ingress Controller or OCP Router adapts to endpoint changes.
while [ 1 -eq 1 ]
do
oc scale deployment nginx-backend --replicas=4
sleep 10
oc scale deployment nginx-backend --replicas=2
sleep 10
doneConclusion
Most companies adopting microservices methodologies are pushing new developments through their CI/CD pipelines at higher frequencies than ever. For this reason, it is crucial that you leverage a data plane that grows with these new methodologies in capability and performance, without disrupting the end‑user experience. Delivering optimal end‑user experience involves consistently delivering low latency for all client connections, under all circumstances.
Based on the performance results, the NGINX Ingress Controller delivers the optimal end‑user experience in containerized environments where the need to iterate and improve development is high.
To get started, download a free trial of the NGINX Ingress Controller and find out how to deploy using the NGINX Ingress Operator.
About the Author

Related Blog Posts

Automating Certificate Management in a Kubernetes Environment
Simplify cert management by providing unique, automatically renewed and updated certificates to your endpoints.

Secure Your API Gateway with NGINX App Protect WAF
As monoliths move to microservices, applications are developed faster than ever. Speed is necessary to stay competitive and APIs sit at the front of these rapid modernization efforts. But the popularity of APIs for application modernization has significant implications for app security.
How Do I Choose? API Gateway vs. Ingress Controller vs. Service Mesh
When you need an API gateway in Kubernetes, how do you choose among API gateway vs. Ingress controller vs. service mesh? We guide you through the decision, with sample scenarios for north-south and east-west API traffic, plus use cases where an API gateway is the right tool.
Deploying NGINX as an API Gateway, Part 2: Protecting Backend Services
In the second post in our API gateway series, Liam shows you how to batten down the hatches on your API services. You can use rate limiting, access restrictions, request size limits, and request body validation to frustrate illegitimate or overly burdensome requests.
New Joomla Exploit CVE-2015-8562
Read about the new zero day exploit in Joomla and see the NGINX configuration for how to apply a fix in NGINX or NGINX Plus.
Why Do I See “Welcome to nginx!” on My Favorite Website?
The ‘Welcome to NGINX!’ page is presented when NGINX web server software is installed on a computer but has not finished configuring