“It’s a perfect storm” may be a common phrase, but it is a useful one in the case of runaway cloud computing costs. Several factors build on one another to spawn this perfect storm:
- The people deploying workloads are not the people paying for them
- It’s easy to consume infrastructure on demand and programmatically
- Easily accessible code repositories make it possible to “borrow” functionality from existing code written by someone else
- CI/CD pipelines and SRE practices help developers integrate and deploy code quickly
Putting it all together, we have a situation where developers are incentivized to deploy new functionality quickly by leveraging existing blocks of code that are usually not streamlined nor optimized for the purpose they serve in the new app. Because time to market is paramount, optimization takes a backseat (very far back). If the non‑optimized code hurts performance, provisioning more powerful infrastructure is just an API call away. Problem solved!
Compounding the problem is the divide – in terms of both mindset and organizational structure – between the people who write the code and the people who pay the bills. As enterprise cloud costs increase, the CFO sweats. But the developers who caused the higher cloud bills are rewarded for their speedy product delivery while being blissfully ignorant of the downstream financial problems they have been incentivized to create.
To solve the problem, F5 NGINX and Opsani have partnered to deliver an optimization solution that gives F5 NGINX Ingress Controller subscribers additional benefits from their existing deployments. NGINX Ingress Controller becomes an optimized solution when the Opsani Servo container is deployed into KubeNest workloads, where it leverages Prometheus to collect rate, errors, and duration (RED) metrics. Opsani uses its autonomous optimization capabilities – powered by machine learning – to continuously optimize the infrastructure to ensure that the right amount of resources is consumed for higher performance and lower cost.
Using Cloud Optimization to Reduce Costs
NGINX users are already familiar with the most basic way to reduce cloud costs: use lightweight tools that add minimal latency while delivering lightning‑fast performance. And of course, in the world of Kubernetes, simple yet powerful tools are a prerequisite to a successful deployment. In this blog, we explain how you can reduce costs and improve performance at the same time by leveraging three tools:
- NGINX Ingress Controller – An Ingress controller based on F5 NGINX Plus that substantially outperforms other NGINX‑based Ingress controllers because it dynamically adjusts to changes in back‑end endpoints without event handlers or configuration reloads.
- Opsani – A unique Continuous Optimization as a Service (COaaS) solution that makes it possible to add CO to your CI/CD pipeline, enabling you to deliver code rapidly and optimize that code for optimal performance at the lowest possible cost.
- Prometheus – A popular open source project for monitoring and alerting. With the NGINX Plus Prometheus module, the NGINX Ingress Controller based on NGINXnbsp;Plus exports hundreds of metrics to a Prometheus server.
One of the most powerful use cases for the NGINX Plus-based version of NGINX Ingress Controller is its ability to improve visibility in Kubernetes with live monitoring (via the NGINX Plus dashboard) and historical data (via Prometheus). In addition, in its role as a front‑end for workloads, NGINX Ingress Controller can collect rate, errors, and duration (RED) metrics and feed them (via Prometheus) to Opsani. Opsani uses machine learning to correlate the metrics with the currently deployed infrastructure and recommend changes that optimize NGINX Ingress Controller, your apps, or the tech stack as a whole. You can even configure Opsani to alert you about latency and performance thresholds set for NGINX Ingress Controller.
A Look at the Numbers – The Results of Our Optimization Testing
Let’s look at an example of the results you can expect from deploying the NGINX Plus-based NGINX Ingress Controller with Opsani and Prometheus. As shown in the screenshot, the Opsani Summary page reports traffic volume (requests per second, or RPS) over time and highlights the benefits of its optimizations compared to baseline settings – here, a 70% savings in Instance Cost Per Hour and 5% better P50 Response Time.

We wondered how these results might stack up against one of the best‑known Ingress controllers – the NGINX Open Source‑based Ingress controller maintained by the Kubernetes community in the GitHub kubernetes/ingress-nginx repo. (Following established NGINX convention, we’ll call it the “community Ingress controller” for the rest of this blog. The NGINX Plus-based version of NGINX Ingress Controller is maintained by the NGINX engineering team in the GitHub nginxinc/kubernetes-ingress repo, along with its sister NGINX Ingress Controller based on NGINX Open Source.)
We tested the performance of the two Ingress controllers in three topologies:
- Topology 1 – Community Ingress controller, deployed using the standard process. Metrics were gathered by adding an Envoy proxy inline with the application under test, in a sidecar container in the application pod.
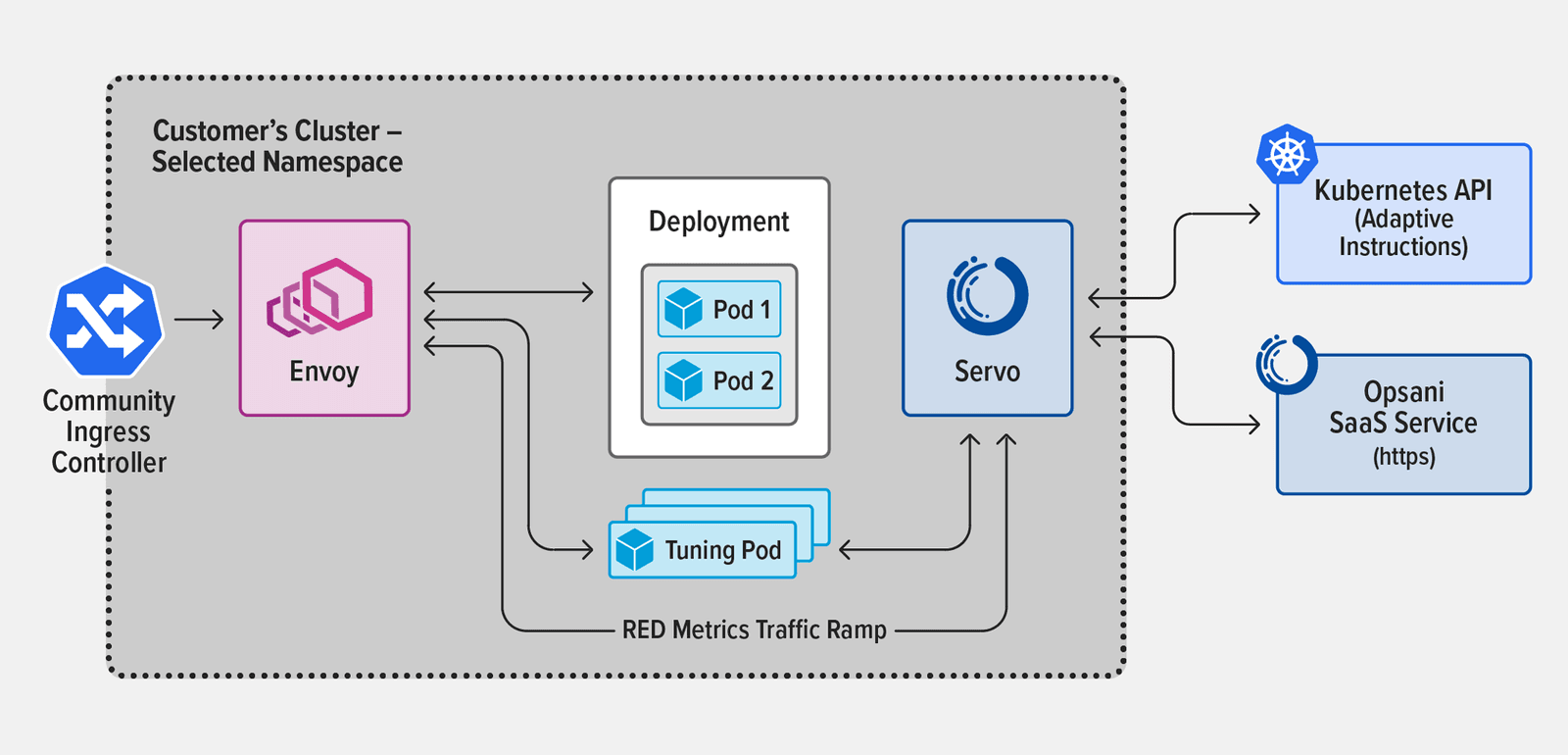
- Topology 2 – NGINX Ingress Controller based on NGINX Plus, deployed using Helm. Metrics were gathered with the same Envoy deployment and configuration as for the community Ingress Controller, to ensure that metrics gathering did not impact the optimization performance process.
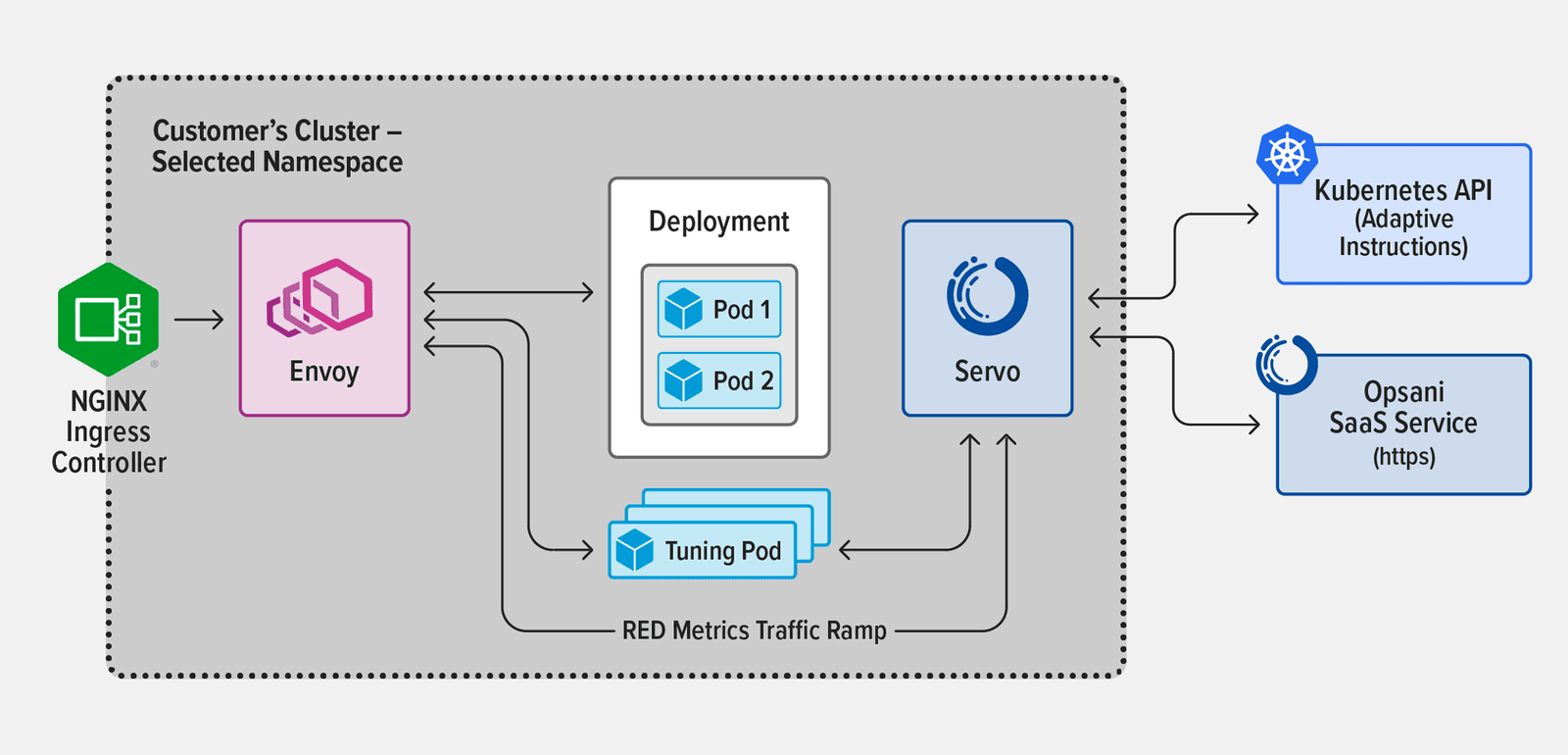
- Topology 3 – NGINX Ingress Controller based on NGINX Plus, also deployed using Helm. Metrics were gathered using Prometheus.
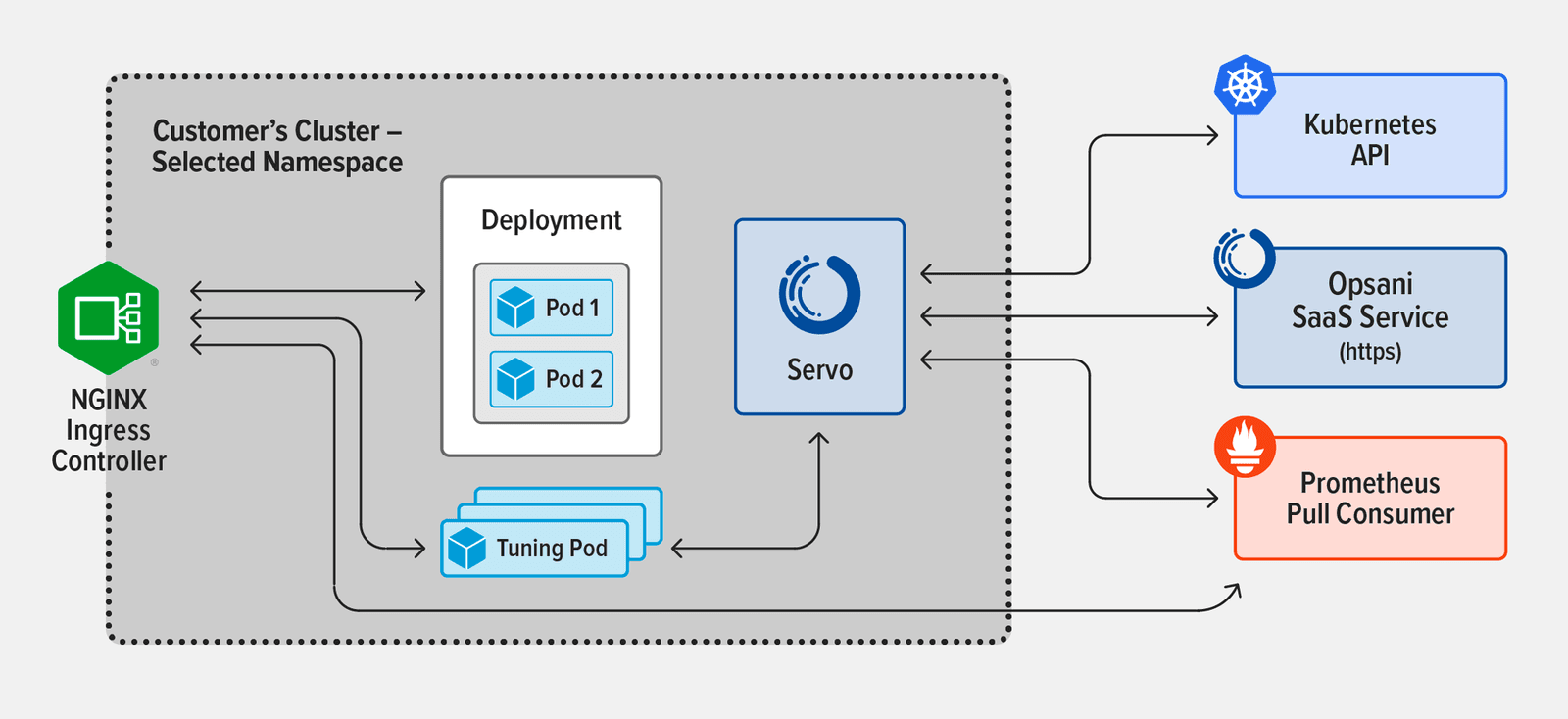
The table summarizes the results of the testing. As you can see, the NGINX Ingress Controller achieves better cost reduction, CPU optimization, and memory optimization than the community Ingress controller. We attribute this to NGINX Ingress Controller’s more efficient load balancing.
The results for P50 response time indicate that Prometheus is the ideal way to collect metrics, because it eliminates the extra hop required by the Envoy sidecar mechanism. Envoy has no effect on P50 response time for the Community Ingress controller, but actually worsens latency by 4% with NGINX Ingress Controller. In contrast, Prometheus improves P50 response time with NGINX Ingress Controller by 5%.
| Topology | Cost Reduction (%) | P50 Response Time (%) | CPU Optimization (%) | Memory Optimization (%) |
|---|---|---|---|---|
| 1 –Community Ingress Controller with Envoy | 44 | 0 | 44 | 44 |
| 2 – NGINX Ingress Controller with Envoy | 70 | 4 | 63 | 81 |
| 3 – Ingress Controller with Prometheus | 70 | -5 | 63 | 81 |
For information on how we ran the tests, see the Appendix.
How Opsani Optimizes NGINX Ingress Controller
Opsani can optimize applications even if they are poorly load balanced in dynamic environments. It can also leverage any type of metrics input, but optimization of connected services is dramatically improved when the input comes from an existing tool that gathers network metrics. To this end, we use a simple deployment process to integrate Opsani with NGINX Ingress Controller.
In environments where NGINX is the Ingress controller – which applies to many applications today – the straightforward switch to using the NGINX Plus-based NGINX Ingress Controller provides a more efficient load‑balancing algorithm without otherwise impacting application functioning. A second benefit is that metrics for the applications load balanced by NGINX Ingress Controller become available as well.
The only additional requirement is to deploy a single Opsani pod with the application under the optimization namespace. The Opsani template for the NGINX Plus-based NGINX Ingress Controller points the metrics endpoint at the Ingress service to capture the application‑specific metrics needed for the optimization. By processing metrics from three or four peak periods, the Opsani engine reaches an optimal level of optimization within just a few hours. To date we have achieved peak load optimization from 30% to 70%.
Get Started with Opsani and NGINX Ingress Controller
Get your free trials of NGINX Ingress Controller and Opsani, then head over to our GitHub repo for scripts and configuration files for NGINX Ingress Controller and Opsani with Prometheus.
Appendix: Testing Methodology
Prerequisites
- The NGINX Plus-based NGINX Ingress Controller is built as a container.
- Kubernetes is configured, and the registry access secret is available to provide access to a secure private Docker registry.
- The NGINX Plus-based NGINX Ingress Controller is deployed via Helm to the ingress namespace.
- An NGINX VirtualServer resource is configured to point to the service to be optimized (usually the frontend service by default). See frontend-virtualserver.yaml in our GitHut repo for an example.
Topology and Configuration
We create three Opsani instances. For Topologies 1 and 2, we use the standard Opsani Dev template available for all Opsani accounts and simply front‑end the application with NGINX Ingress Controller and point to the application service.
For Topology 3, we use the same default template and modifiy the Servo configuration with the ConfigMap defined in opsani-manifests-nginx-plus.yaml in the GitHub repo. As with the standard template, we substitute appropriate values for the following variables in the ConfigMap:
{{ NAMESPACE }}– Target resource namespace{{ DEPLOYMENT }}– Target deployment{{ CONTAINER }}– Target application container name
In addition, we set OPSANI_ACCOUNT_NAME, OPSANI_APPLICATION_NAME, and OPSANI_TOKEN according to the document exposed with the application deployment.
While the default ServoX for Opsani Dev includes a Prometheus instance, we instead deploy the Prometheus instance in the same namespace as NGINX Ingress Controller, to reduce the need for ClusterRole configuration.
We also configure a service to allow the Servo pod to find and query the correct instance. This artifact is covered in opsani-manifests-nginx-plus.yaml.
Once Bank of Anthos is running as the sample web application and the Ingress was verified, we launch the Ingress Prometheus instance. Lastly, we can launch the Opsani optimization by applying the opsani-manifests-nginx-plus.yaml file.
About the Author
Related Blog Posts

Automating Certificate Management in a Kubernetes Environment
Simplify cert management by providing unique, automatically renewed and updated certificates to your endpoints.

Secure Your API Gateway with NGINX App Protect WAF
As monoliths move to microservices, applications are developed faster than ever. Speed is necessary to stay competitive and APIs sit at the front of these rapid modernization efforts. But the popularity of APIs for application modernization has significant implications for app security.
How Do I Choose? API Gateway vs. Ingress Controller vs. Service Mesh
When you need an API gateway in Kubernetes, how do you choose among API gateway vs. Ingress controller vs. service mesh? We guide you through the decision, with sample scenarios for north-south and east-west API traffic, plus use cases where an API gateway is the right tool.
Deploying NGINX as an API Gateway, Part 2: Protecting Backend Services
In the second post in our API gateway series, Liam shows you how to batten down the hatches on your API services. You can use rate limiting, access restrictions, request size limits, and request body validation to frustrate illegitimate or overly burdensome requests.
New Joomla Exploit CVE-2015-8562
Read about the new zero day exploit in Joomla and see the NGINX configuration for how to apply a fix in NGINX or NGINX Plus.
Why Do I See “Welcome to nginx!” on My Favorite Website?
The ‘Welcome to NGINX!’ page is presented when NGINX web server software is installed on a computer but has not finished configuring