
The solutions team at Volterra designs and maintains many potential use cases of the Volterra platform to demonstrate its potential value. These use cases are often made into instructional guides that customers use to get first hands-on experience with Volterra.
The solutions team wanted a quicker, automated method of deploying our use cases on demand internally with as little human input required as possible. Our deployments covered a hybrid multi-cloud environment using both IaaS platforms (AWS, Azure and GCP) and private data center environments (VMware vSphere and Vagrant KVM). We wanted to simplify the management of these environments by providing a single tool that could create deployments in any environment without the need for individual users to create additional access accounts or manage additional user credentials for each virtualization platform or IaaS provider. This tool also needed to scale to support multiple concurrent users and deployments.
In summation, the central problem we wished to solve was to create an automated solutions use case deployment tool, capable of scaling and handling concurrent deployments into hybrid multi-cloud environments with as little user input as possible.
The Altered-Carbon Project (AC)

To this end we created a project called Altered-Carbon, often shortened to AC. The AC project is a dynamic GitLab pipeline capable of creating over 20 different Volterra solution use cases. Through pipeline automation, we created single command “push button deployments” allowing users to easily deploy multiple use case clusters on demand or through scheduled daily cron jobs.
For reference, in AC we refer to each deployment as a STACK and each unique use case as a SLEEVE.
Project Development
We began the development of the AC project by automating the use case hello-cloud into the first SLEEVE. The hello-cloud use case creates a Volterra site in AWS and Azure, then combines these sites into a Volterra VK8s (virtual Kubernetes) cluster and deploys a 10 pod application across both sites using the VK8s. We began the process by creating additional terraform templates and shell scripts utilizing the Volterra API in order to create a fully automated workflow GitLab that CI/CD pipelines could manage. Then we set to work on making this deployment methodology reusable and scalable.
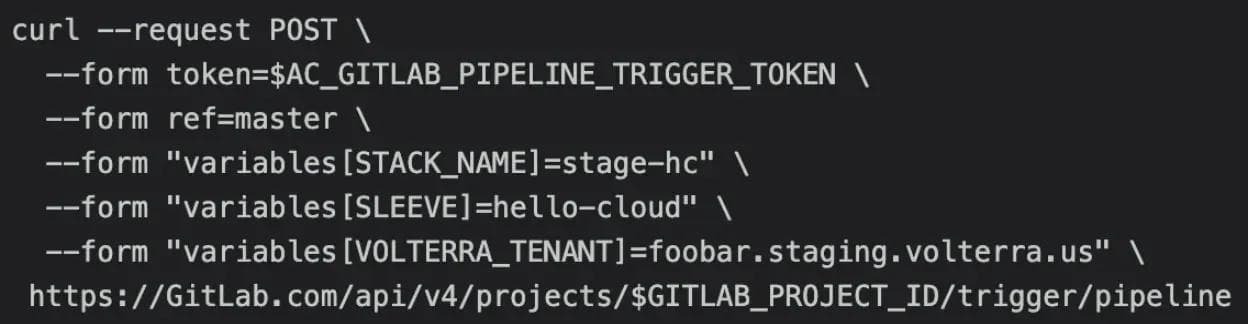
Adding unique naming conventions was the next issue we tackled in our design. To allow for multiple deployments of the use case on a single Volterra tenant environment, we needed to ensure our resources created in each STACK had unique names and would not try to create resources with names duplicating other STACKs in the same Volterra tenant environment. To solve possible naming convention conflicts we began to incorporate the idea of unique user-provided environmental variables in pipeline triggers that would become central to the project. The environmental variable STACK_NAME was introduced and used by terraform to include a user-defined string in the names of all resources associated with a specific STACK. Instead of triggering on commit, the AC pipelines jobs trigger conditions were set to only run when triggered by a GitLab users API call using a GitLab Project CI Trigger Token allowing the pipeline to be controlled by human input or external API calls. By using API calls similar to the following example, it allowed users to accomplish our goal of creating multiple deployments without resource conflicts with a single command.

Then we endeavored to create additional deployment options from this model. The AWS and Azure site deployments of hello-cloud were also individual use cases we wished to deploy independently with AC. This caused us to run into our first major issue with GitLab. In GitLab CI/CD pipelines, all jobs in a projects pipeline are connected. This was counterintuitive, as many jobs needed in our hello-cloud deployment would not be needed in our AWS or Azure site deployments. We essentially wanted one GitLab Project CI pipeline to contain multiple independent pipelines that could be triggered on demand with separate sets of CI jobs when they were required.
To solve this issue, we introduced the environmental variable SLEEVE into the pipeline structure that incorporated GitLab CI/CD only/except options. This allowed CI jobs triggered on any pipeline to be limited based on the value of the SLEEVE provided in the pipeline trigger. Finally, we had our initial 3 SLEEVE options: simple-aws, simple-azure and hello-cloud. Each SLEEVE would define what use case a user wished to deploy (thus controlling the CI jobs in a triggered pipeline) and a STACK_NAME to name the resources created by any triggered pipeline. The following command structure incorporating both environmental variables served as the most basic AC command that is still used today:
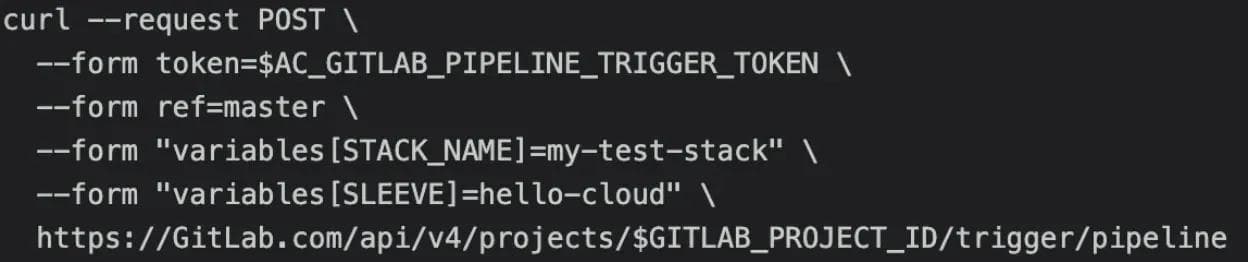
The following image shows a visualization of how changing the SLEEVE environmental variable will change the jobs triggered in each run of the AC pipeline.
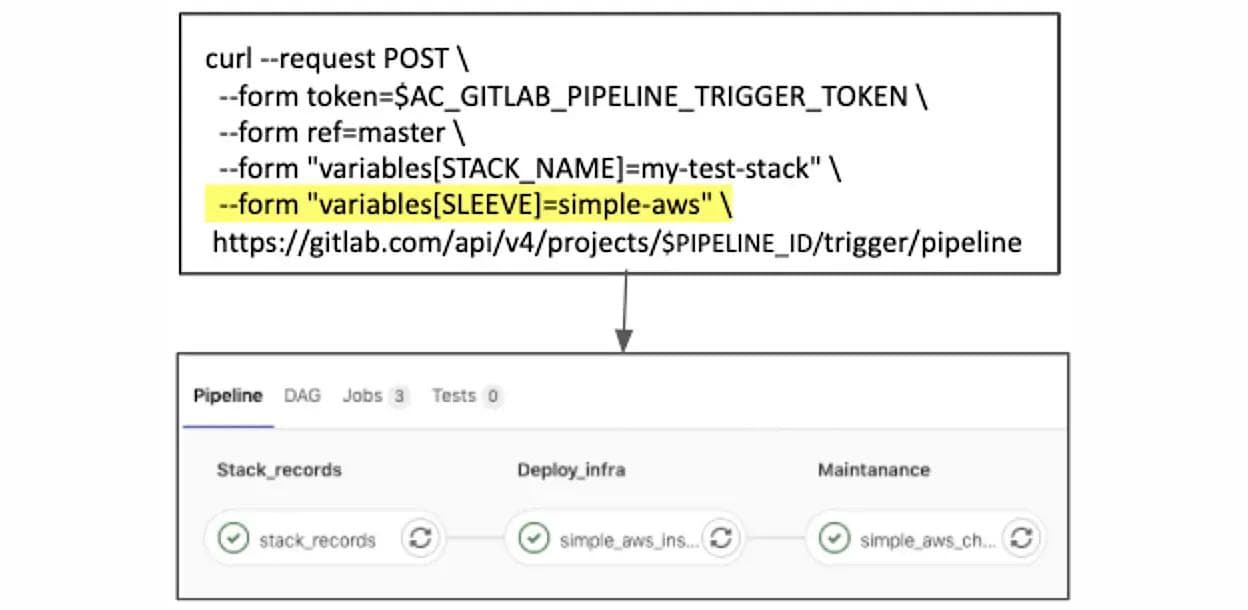
SLEEVE “simple-aws” pipeline:
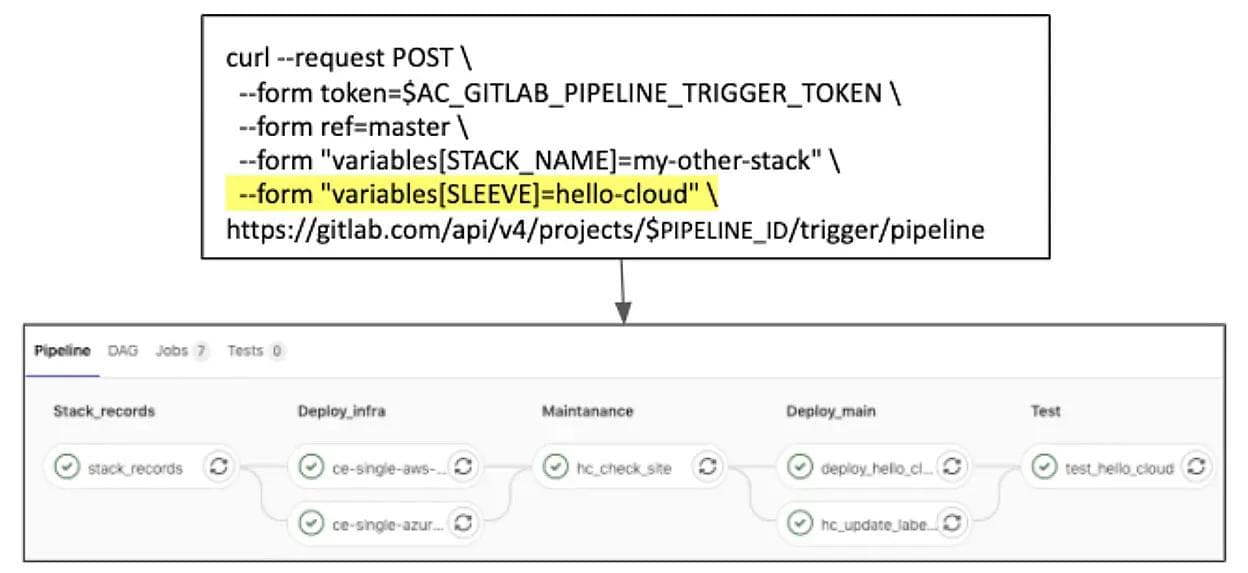
SLEEVE “hello-cloud” pipeline:
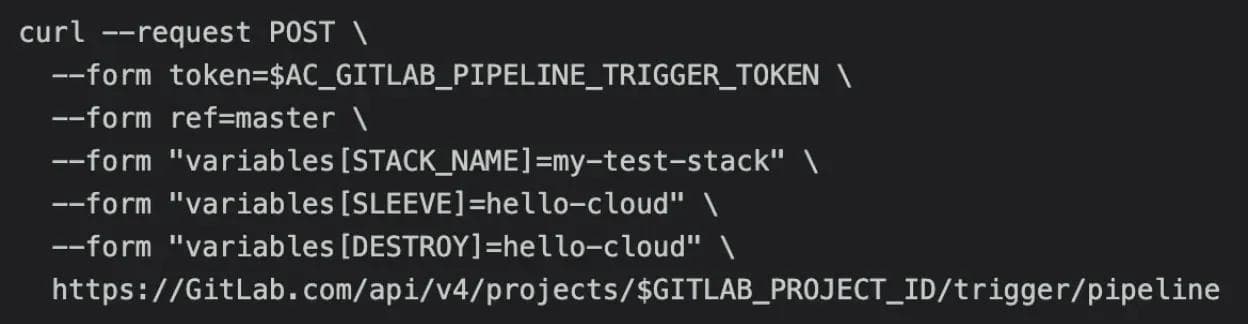
We also introduced additional jobs that would be triggered if the environmental variable DESTROY was provided in any pipeline trigger. This would provide a reverse option to remove the resources created by AC. The following is an example of that would remove the resources of an existing STACK:
Other environmental variables were stored in GitLab with default values that could be overridden by adding values into the trigger command. For example, the API URL of our Volterra tenant environments was stored in the VOLTERRATENANT environmental variable. If a user added the VOLTERRATENANT environmental variable to their API command, this would override the default value and redirect the deployment to the desired location. This proved to be very important to our internal testing ability as the solutions team manages dozens of Volterra tenant environments and needs the ability to switch between them based on the task at hand:
These optional environment variables could be used to add a greater level of control onto deployments when needed, but allowed a more simplistic default deployment option for users who did not want to manage this additional overhead. It also allowed us to easily switch between deployments on staging and production environments which would prove essential for our largest AC consumer.
Solutions Use Case: Nightly Regression Testing
As mentioned before, each SLEEVE in AC represented a Volterra use case that would often be customers’ first interaction with the product. Ensuring these use cases were functional and bug-free was key to providing a strong first impression of the product. Before AC was created, testing the use cases to confirm that they were functional and up to date with the latest Volterra software and API versions was a time consuming task. The manual portions required of each use case created a limitation on regression testing, which was not undertaken often enough and was prone to human error.
However with AC automation, daily scheduled jobs could be used to trigger a deployment of any specific use case with a SLEEVE and then remove the resources created after the deployment had either completed or failed to deploy. This was used on both staging and production environments to test if recent changes in either had affected the use case deployment or caused bugs in the Volterra software. We would then be able to update bugs found in our use case guides or catch Volterra software bugs quickly and submit resolution tickets.
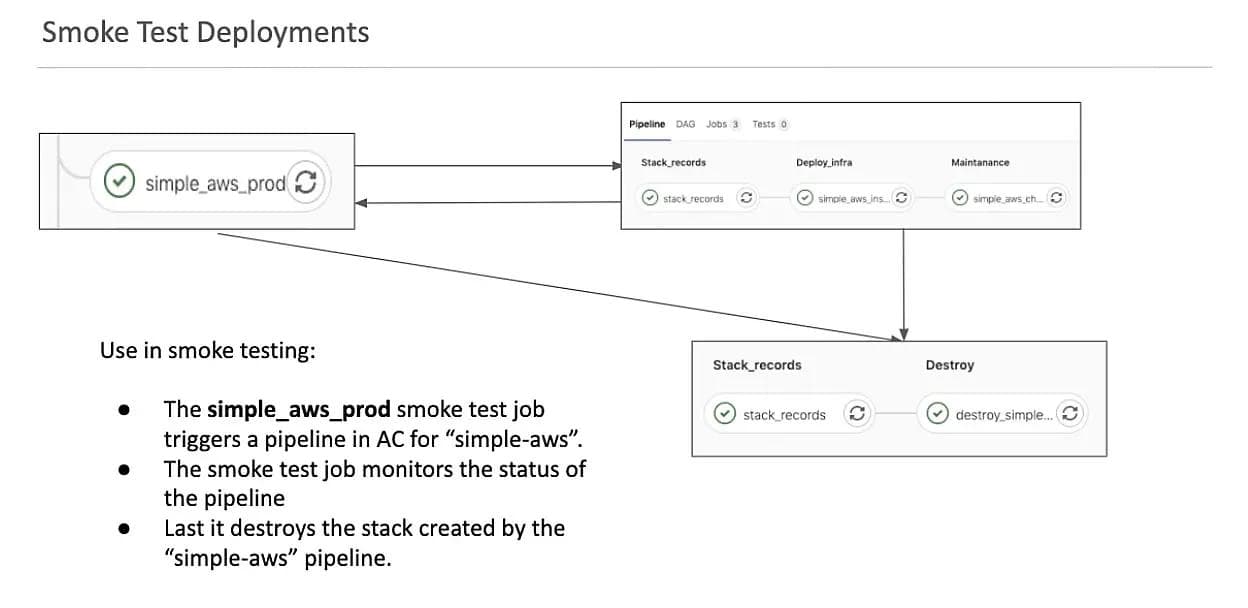
We created a separate repository and pipeline with scheduled jobs that would use the GitLab API trigger commands to concurrently generate multiple stacks using different SLEEVEs. Each smoke test job would start by triggering the creation of a stack with an independent AC pipeline. The smoke test job would then get the pipeline ID from the stdout of the pipeline trigger call and the GitLab API to monitor the status of the pipeline it triggered. When the pipeline completed (either with a success or failure) it would then run the destroy pipeline on the same STACK it created to remove the resources after the test.
The following image details this process and shows the jobs it triggers in AC for its creation and destruction commands:
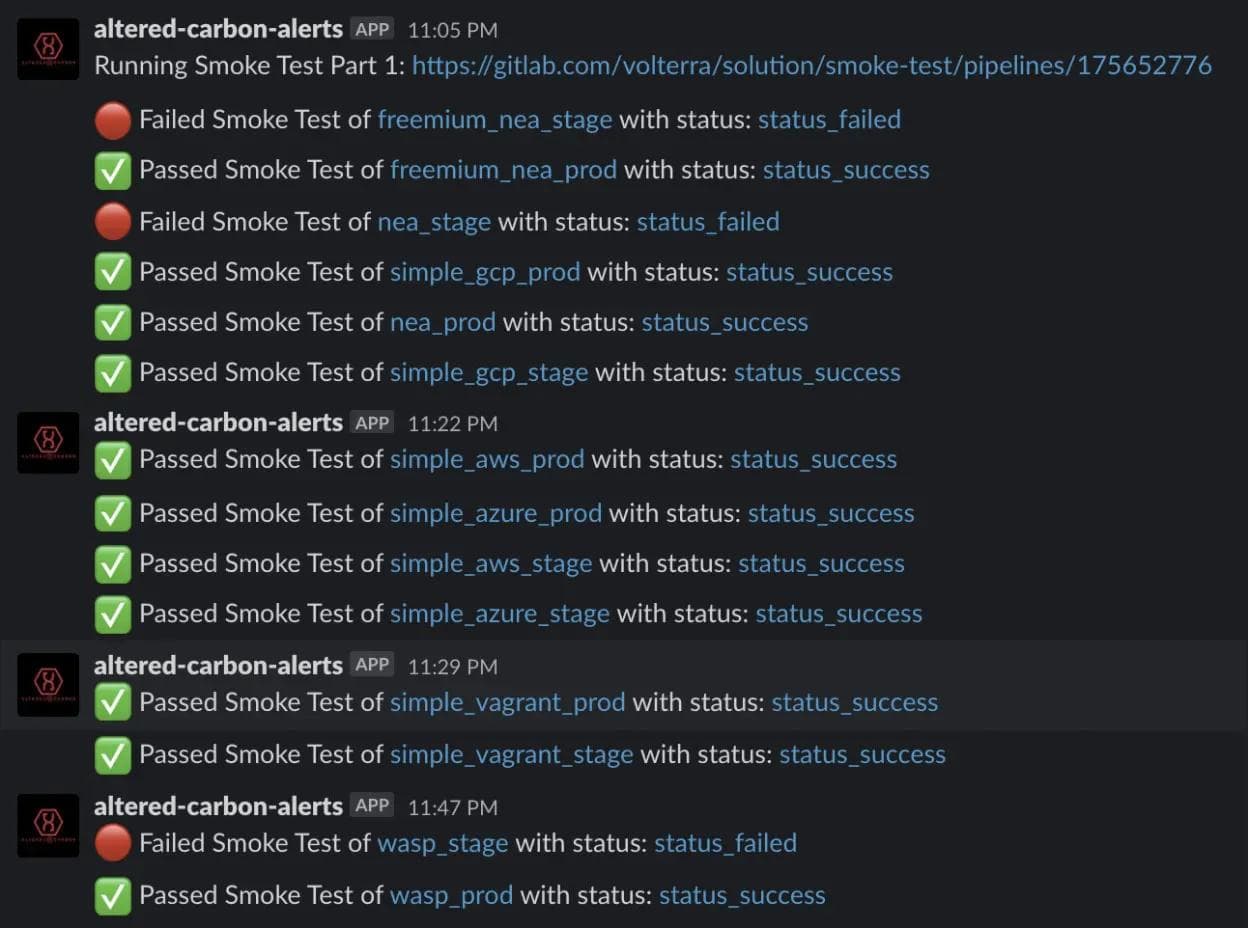
When a smoke test pipeline failed, we were able to provide the environmental variables that could be used in an AC trigger to reproduce the issue. This could be provided in our technical issue tickets allowing our developers to easily recreate the failed deployments. Then as more SLEEVES were completed, we added more and more jobs to the CI pipelines allowing more test coverage. To further improve the visibility of these tests we added a Slack integration and had the smoke test jobs send the success or failure message of each pipeline run with links and details to the corresponding CI web pages in both the Altered-Carbon and Smoke-Test projects.
Stack Record Keeping and Pipeline Web URL Navigation
The complexity of the project increased as AC evolved, added additional users from the solutions team and created more and more stacks. This began to create fundamental problems when navigating the GitLab Pipeline web UI. We were using GitLab pipelines in a very untraditional way, which rendered the GitLab pipeline web UI difficult to use in tracing individual pipeline runs that related to the STACKs we were creating.
GitLab pipelines that manage deployments through GitOps workflows seem best suited when it is used against a static defined set of clusters. In this case, each run of a GitLab pipeline would affect the same clusters and resources every time. The deployment history of these clusters in this case is the pipeline history visualized in the GitLab web UI. However, AC is dynamic and handles a constantly changing set of resources where each pipeline run can utilize a totally different set of jobs, managing different STACKs of resources, in different virtualization providers. This differentiation created by the SLEEVE and STACK conventions meant that it is very difficult to determine which pipeline corresponds to which stack. For example, we can take a look at the GitLab CI/CD pipeline web UI for AC:
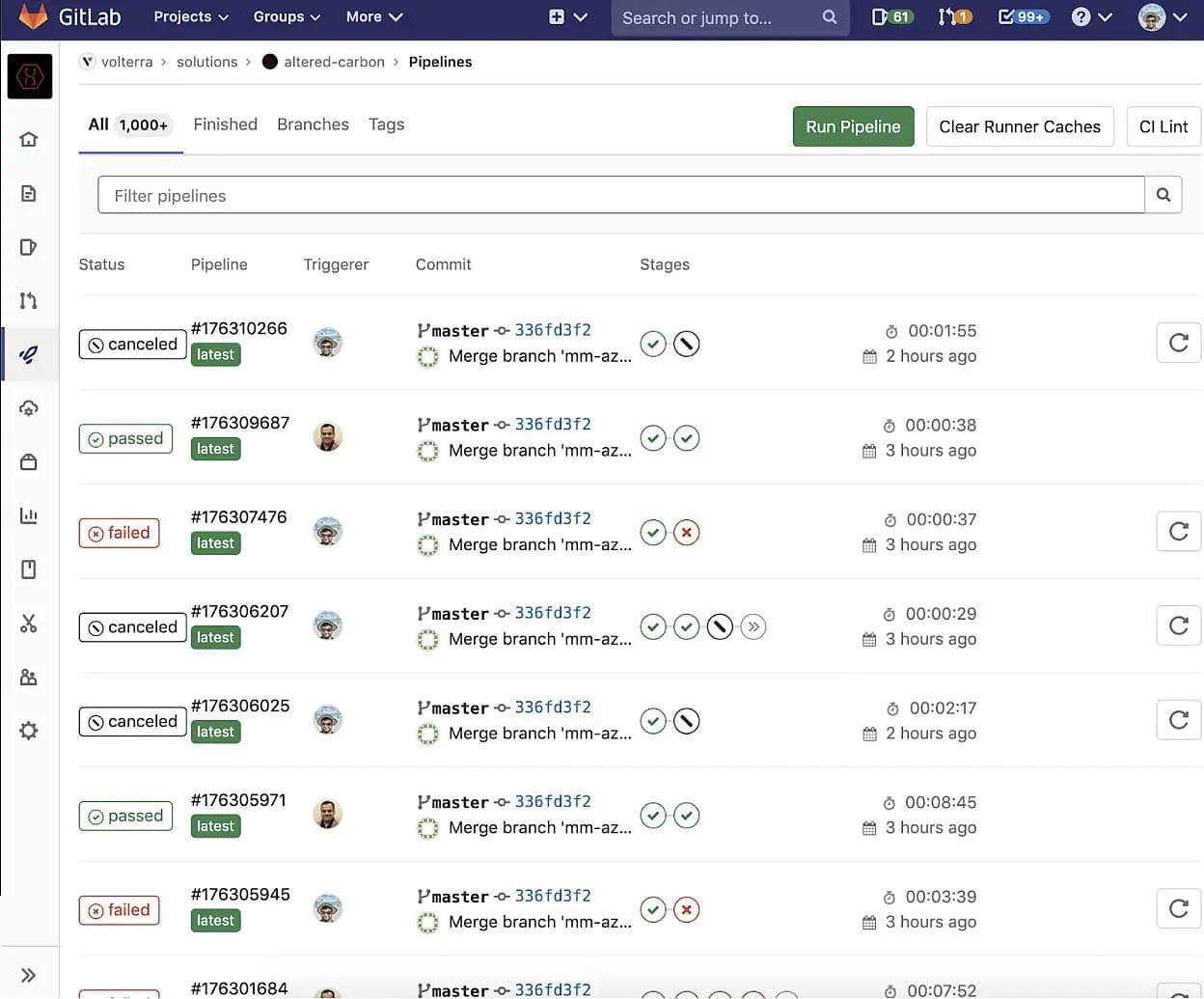
From this view, we cannot determine which STACK or SLEEVE any single pipeline is changing without viewing each and every pipeline individually. When this is running hundreds of pipelines a day it can be tedious to find the specific pipeline run that either created or destroyed any one STACK in particular or locate specific details about said STACK. To solve this problem early on in the AC development, we added a simple record keeping system. A job would run before any pipeline called stack-records. This job would collect details on the stack upon creation and generate a json file that would be uploaded to our S3 storage bucket used to store our tfstate backups. Below we see an example of a stack record:
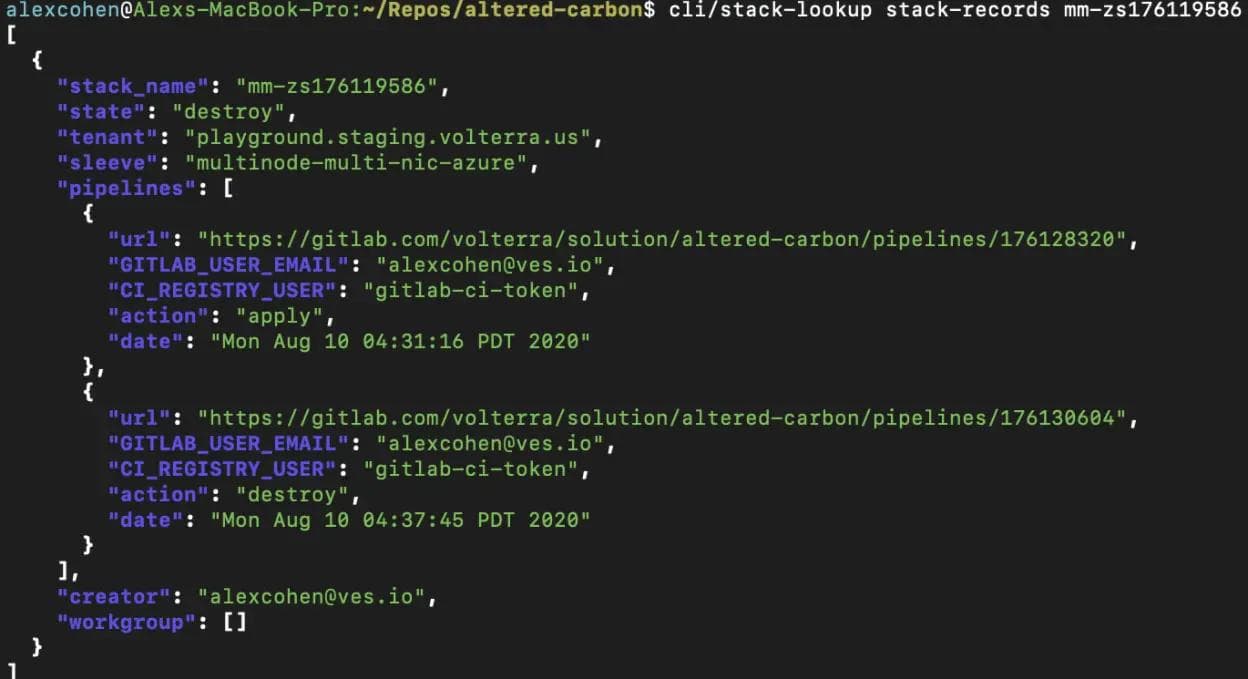
The stack-record.json files include details of each stack such as:
- Which Volterra tenant environment was used.
- What SLEEVE was used.
- If the STACK was either currently running in the “apply” state or if its resources were removed with the “destroy” state.
- Which GitLab user created the stack.
- A workgroup listing other users with access to change a STACK.
- And most importantly, a pipelines array that would include the web url of each pipeline run that ran against the stack, who triggered the pipeline, if the pipeline either applied or destroyed a stack and when the pipeline was triggered.
This provided a recorded history of all pipeline URLs associated with any one stack and a simple CLI script that can access these files via S3 API calls was created to simplify the process further. Our users consuming AC could use these documents to track the history of stacks and view when these stacks were changed by viewing the stack records.
Stack records also allowed us to implement certain levels of user control and error catching over the pipelines we deploy. For instance, a change made to the Volterra Software after the creation of AC forced us to begin limiting site cluster names (a value derived from the STACKNAME value) used in Volterra site creation to a limit of 17 characters. So we added a check onto the stack records job that would cause pipelines to fail before running any deployment steps if the STACKNAME violated the character limit. Other custom controls were added such as the addition of user permission levels in AC that limit which users have access to change specific stacks controlled by AC.
- Admin level permissions where the top two developers of AC have the ability to create or destroy any stack for debugging purposes. -The owner or creator level is for a GitLab user who initially creates a STACK. Their GitLab email value is recorded in the stack records as the creator and has the ability to create or destroy a stack.
- Then we have workgroup level permissions, the GitLab user email can be added into the stack record workgroup array granting users other than the creator the ability to apply or destroy a STACK.
- A user without any of these permission levels will not be able to change a stack. If such a user attempts to change a stack they have no permission over then the stack-records job will fail before any resources are deployed.
Internal Use and Current Test Coverage
Today AC has become central to the solutions team providing most of our regression testing and automation. We find its main uses are regression smoke testing, scale testing, product billing tests and for simplified deployments used in product demos.
The automated deployments have found their greatest consumer in our nightly regression tests. Each night we test each of our SLEEVES against a production and staging environment by triggering a deployment and then tearing down the resources created. When changes occur we are quickly able to detect them and submit bug reports to update our guides. Our current test coverage includes:
- Secure Kubernetes Gateway.
- Web Application Security.
- Network Edge Applications that deploy our standard 10 pod “hipster-co” application and a more lightweight single pod application.
- Hello-Cloud.
- CE single node single network interface volterra sites across AWS, GCP, Azure, VSphere and KVM/Vagrant.
- CE single node double network interface volterra sites across AWS, GCP, Azure, VSphere and KVM/Vagrant.
- Scaled CE single node single network interface volterra sites deployments (using GCP, VSphere and KVM), creating a number of ce single node single nic sites to test Volterra scaling abilities.
- CE single node multi network interface volterra sites across AWS, GCP, Azure, VSphere and KVM/Vagrant.
- CE multi node single network interface volterra sites across AWS, GCP, Azure, VSphere and KVM/Vagrant.
- CE multi node multi network interface volterra sites across AWS, GCP, Azure, VSphere and KVM/Vagrant.
We also have specialized scale testing sleeves that automate the process of deploying up to 400 sites at once to test out the scaling capabilities of Volterra software and has been tested using GCP, vSphere and KVM.
The rapid automated deployment of use cases allows solutions team members to focus on other tasks, improving internal efficiency. The solutions team often uses AC to deploy dozens of KVM, GCP and vSphere sites for recording video demos saving us time in creating Volterra sites to use in creating more complex infrastructure, building on top of the automation we have in place. This is also used for daily cron jobs that test the billing features of the Volterra platform by automating deploying AWS, web app security, secure Kubernetes gateway and network edge application use cases on a specialized Volterra tenant that records billing information.
Future Plans and Roadmap
Our use of AC is already yielding very successful results and there are still many more features and improvements to add onto the project in the near future.
The biggest addition to the project is the constant addition of new SLEEVE options to cover additional use case deployments. For each new SLEEVE added, we add a new job to our nightly regression smoke tests providing more coverage for solutions deployment projects. Most previous sleeves focused on single node and single network interface use cases but we have recently expanded our SLEEVE coverage to multi node Volterra site clusters and multi-network interface use cases across AWS, Azure, GCP, VMWare and KVM/Vagrant platforms.
We also seek to improve our stack record system. We will be increasing the level of detail in our AC records and adding improved search functionalities with the incorporation of RDS database stores for our records. The goal is that we will be able to provide faster searches of our AC environment and more selective search functionality such as stack lookups based on stack state, stack creators, etc. Using these records to construct a custom UI to more efficiently visualize deployments created with AC is also on our roadmap.
About the Author
Related Blog Posts

A new path to technical excellence for F5 partners
Introducing F5 Partner Foundations, a structured learning curriculum to build F5 partner engineer expertise with a clear pathway to specialization.

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.