
Every once in a while, a cool technology reaches an inflection point where real business needs intersect with that technology's strong points. This makes the technology not only plausible but practical. Berkeley Packet Filter (BPF) recently reached this point among Linux developers. BPF is an extremely efficient intercept and processing point on a Linux host that promises to expand to Windows servers sooner than later. The range of available data is vast, directly adding to full stack visibility for Site Reliability Engineering (SRE) operations tasks. It also naturally aligns with solving challenges related to security and traffic management. The range of hooks is equally vast, providing an attractive array of useful trigger points for BPF applications that appeal to observability, security, and network specialists. BPF is the right technology to enable observability without breaking the bank. And it all starts with observability.
The fundamental design of BPF makes it just about as efficient a method for compute work as possible ($ per watt). Even better, the toolchains produce the bytecode for you, so you can focus on your desired result and not low level assembly language-type programming. How? These two design characteristics cause BPF to shine:
Instruction set design
The software design of BPF was purposely modeled after that of the emerging modern CPU architectures. In fact, processor terminology is used because it accurately describes BPF elements and use. BPF has registers and instructions. They are designed for direct consumption by CPUs. BPF, based on the BSD Packet Filter design (1992), is a redesigned packet capture filter machine better suited to current day register-based CPU architectures. This design received a natural boost in 2014 when “Enhanced Berkeley Packet Filter” or eBPF was released in v3.18 of the Linux kernel. eBPF was an important distinction from Classic Berkeley Packet Filter (cBPF) in the early days after its release. Today the distinction is less crucial given all supported versions of the kernel contain the 2014 enhancements. They are worth noting: Wider registers (from 32-bit to 64-bit means more work gets done per cache line/clock cycle), more registers (from 2 to 10 means more 1-to-1 mapping between modern CPU registers and kernel ABIs), and a handful of additional instruction set enhancements that make BPF programs safer and more useful.
Link Layer
BPF consists of a network tap and a packet filter. The tap operates at the data link layer as packets come off the wire to a given network interface. It copies packets for the filter to interrogate. This insertion point gives it full visibility into the network path of the Linux host. For ingress traffic this means before the host processor starts working on it, and for egress traffic it means just before it hits the wire to leave the host. This diagram shows BPF intersecting the ingress packet path at the Data Link Layer.
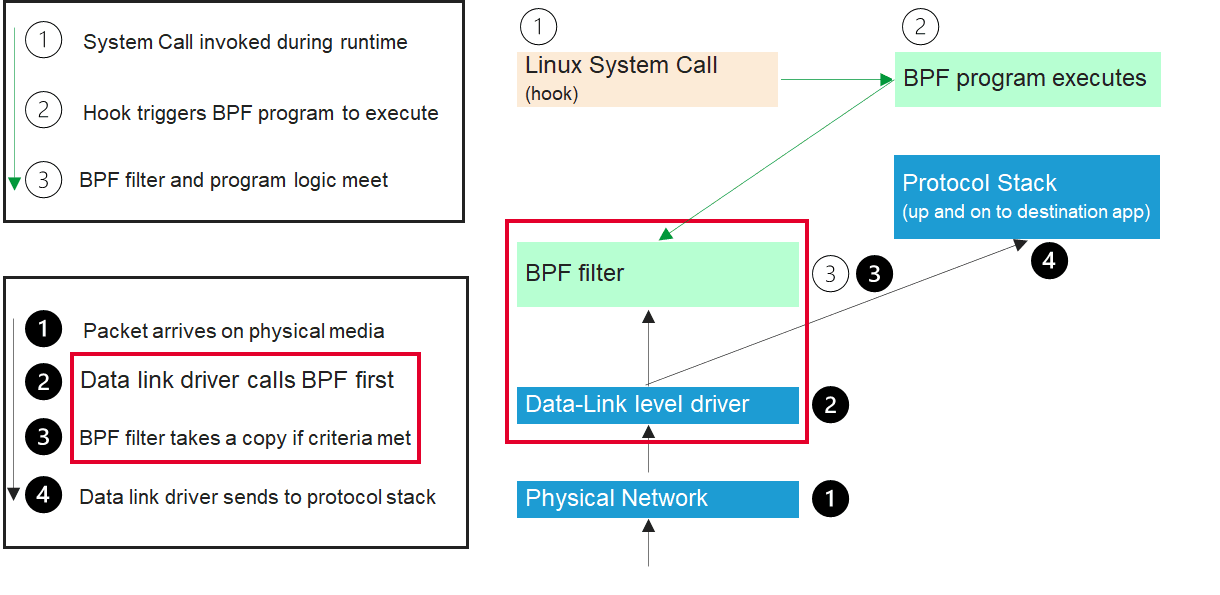
The range of available data is vast, directly adding to full stack visibility for SRE operations tasks. In this example, we focus on some of the most commonly used fields from the IPv4 header.

Using this data, policies can be defined to customize packet filtering. The following policy filters for TCP packets destined for a specific destination IP address.
Leveraging eBPF for observability has a BOGO (buy one, get one) benefit: The observed data can be used for other purposes beyond observing. For example, traffic routing or security.
Referring back to the data set we shared earlier, pieces of that data set used for observing the traffic ingress path of a Linux host are useful for other things. For example, source IP, destination IP, destination host, and port are useful for both ingress traffic routing and also for limiting access.
Regardless of use, everything starts with the packet copy by the BPF tap. Once the copy is taken, data can be put into memory (see more on BPF Maps) and then exported as a telemetry stream as well as leveraged simultaneously by other BPF programs that specify policy and filtering actions. This is where the branching from observability to traffic management and security occurs. To capitalize on the extreme efficiency of BPF a clear picture of what data is needed and how that data is used is the starting point. In the next post in this series, my colleague, Muhammad Waseem Sarwar, will explore options for BPF programming at various locations in the Linux network stack.
About the Author
Related Blog Posts

Multicloud chaos ends at the Equinix Edge with F5 Distributed Cloud CE
Simplify multicloud security with Equinix and F5 Distributed Cloud CE. Centralize your perimeter, reduce costs, and enhance performance with edge-driven WAAP.

At the Intersection of Operational Data and Generative AI
Help your organization understand the impact of generative AI (GenAI) on its operational data practices, and learn how to better align GenAI technology adoption timelines with existing budgets, practices, and cultures.
Using AI for IT Automation Security
Learn how artificial intelligence and machine learning aid in mitigating cybersecurity threats to your IT automation processes.
Most Exciting Tech Trend in 2022: IT/OT Convergence
The line between operation and digital systems continues to blur as homes and businesses increase their reliance on connected devices, accelerating the convergence of IT and OT. While this trend of integration brings excitement, it also presents its own challenges and concerns to be considered.
Adaptive Applications are Data-Driven
There's a big difference between knowing something's wrong and knowing what to do about it. Only after monitoring the right elements can we discern the health of a user experience, deriving from the analysis of those measurements the relationships and patterns that can be inferred. Ultimately, the automation that will give rise to truly adaptive applications is based on measurements and our understanding of them.
Inserting App Services into Shifting App Architectures
Application architectures have evolved several times since the early days of computing, and it is no longer optimal to rely solely on a single, known data path to insert application services. Furthermore, because many of the emerging data paths are not as suitable for a proxy-based platform, we must look to the other potential points of insertion possible to scale and secure modern applications.