
There’s a saying in the military: “Amateurs discuss tactics, but professionals study logistics.” That thought may be surprising to some at first glance, when thinking about the brilliance of Lee at Chancellorsville, or Hannibal’s genius through the Punic Wars; however, history notes neither Lee nor Hannibal won their respective wars. The primary reason why was logistics: the ability to keep an army supplied with food, clothes, and weapons, at the right time and in the right place. Despite brilliant tactics, it was logistics that ultimately decided victory. In other words, tactics allow you to make best use of the assets you have on the field, but logistics enable you to be and remain on the field in the first place.
I like the military analogy because I believe it has parallels to how data-driven solutions are often portrayed today. The glamor of the “tactics”—advanced AI techniques such as deep learning, random forest classification, gradient boosting, and so on—regularly overshadow the less sexy “logistics” of the data architecture foundations that enable those advanced techniques.
The first step in a discussion about data architecture is to define what the concept of “data architecture” encompasses. Unsurprisingly, the answer turns out to be nuanced—it is layered and multifaceted. To help ground the discussion, it is useful to start by thinking about it in terms of the journey of collected telemetry data. The diagram below shows a high-level data pipeline, highlighting the touchpoints between the pipeline and the data architecture foundation.
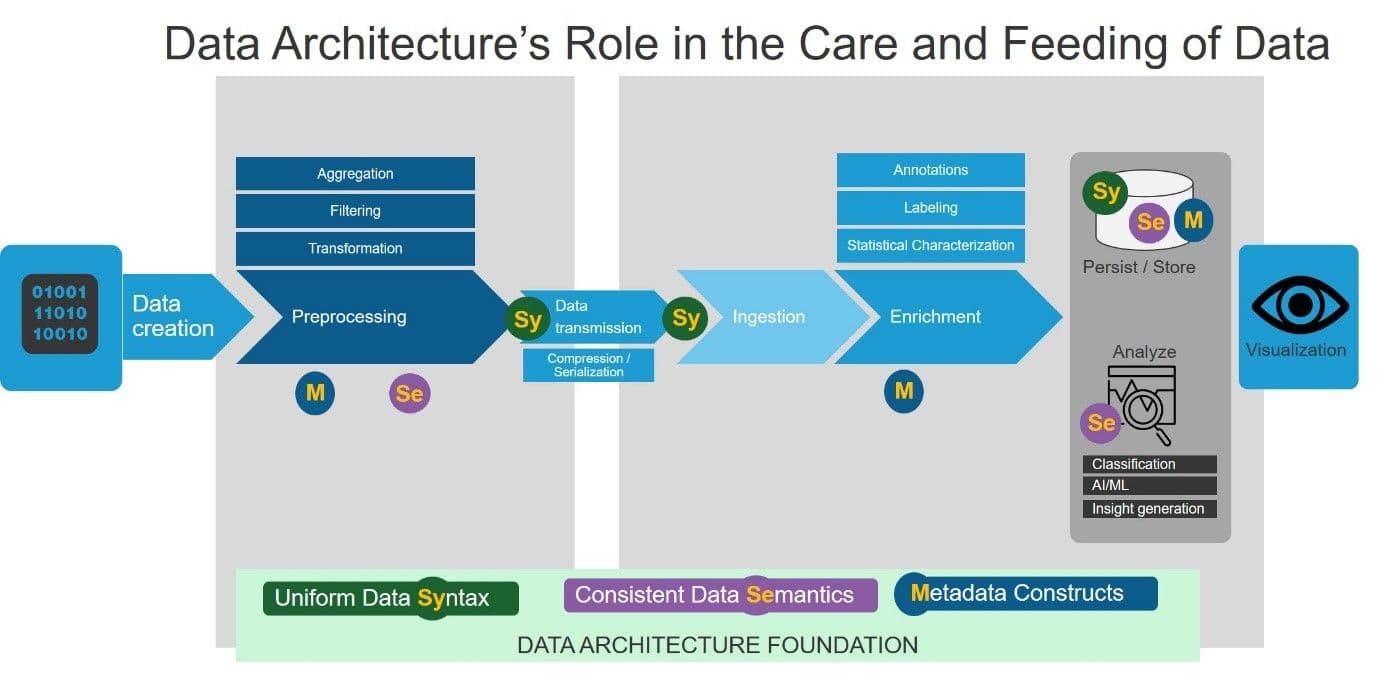
Each data element’s journey begins with its creation, often followed by some amount of preprocessing before being serialized and transmitted to a data collector/aggregator, typically residing in the cloud. Next, the data collector itself may (after deserialization and ingestion) perform some additional processing and enrichment before delivering the data to a persistent data store and/or feeding a data analytics pipeline. Finally, the enriched/analyzed results are made available for human consumption using a visualization platform, and may even be consumed by automated systems in the form of feedback inputs for self-tuning or self-remediating closed loop systems.
With the data pipeline context established, we can now return to the question of understanding what is meant by “data architecture.” The first answer, at the most superficial level, is focused on the data representation and serialization syntax. For example, if a data event contains an object field titled ‘customer,’ the syntactic view determines if that data is represented as a string, or an integer UUID, or something else.
However, if we dig a little deeper, a second answer is about somewhat more than mere syntax; it is the concern of the data’s semantics—having a well-defined and consistent interpretation of the data content. Once again, using the ‘customer’ field as an example, assume the syntactic question has been answered—that in fact the data element has been defined to be a string field. Next, the data architecture must be able to answer the meaning/interpretation question: are the semantics that of an individual person’s name, or is it a company name? If it’s a person’s name, is it <last-name> or <first-name> or both? When combined with uniform syntax, consistent semantics allow the data pipeline to perform functions such as data filtering and aggregation generically and robustly, based on a coherent logical interpretation of the data content. In addition, the data store can also easily perform federated data queries across different data creation pipeline instances, as long as the created data follows a consistent syntax and semantic.
Finally, digging deeper yet, in many cases it is important to have a third capability in the data architecture: a vocabulary to contextualize the telemetry and reason about the data itself—the metadata vocabulary. This is especially important in the context of enterprise data governance requirements, whether for compliance, auditing, or even for internal workflows that require a holistic understanding of the data being managed within a data warehouse. The metadata often comes in the form of annotations on the data, with the annotations following the same sort of syntactic and semantic consistency that the data itself does. For example, metadata fields would likely be used to record the identity of the data source, the timeline of the data processing for any collected data, to comply with legal data retention requirement.
Another way metadata fields can be used in the lexicon of a data description schema is to reason about aspects of the data fields themselves, such as the ordinality of a data element or the privacy sensitivities. Going back to our ‘customer’ data field example one more time, metadata annotations in the data schema might mark the data element as unique, while additional annotations, in the context of a data stream (such as for retail purchase transactions), could mark data elements as being required and singleton—in other words, metadata would be used to say that the customerID field must be unique (usable as a primary database key), and that each purchase event must have one, and exactly one, customerID associated. The utility of the totality of the metadata capabilities, within the context of the data pipeline, is the fact that they can be leveraged to add annotations for data compliance, provide data enrichment lexicon, and enable flexible governance workflows for the data warehouse.
So, in summary, the answer to the question: “What is Data Architecture?” is that it is, at a minimum, about providing a framework that enables consistency, both syntactic and semantic, to the data that is collected. Additionally, a robust data architecture should also encompass a metadata strategy that is powerful enough to not only specify constraints on the data, but also include the ability to reason about the data itself.
When considered an explicit area of focus, and well executed, a data architecture is therefore a lot like a good military logistics infrastructure. Just as in the military context, it provides a foundation that multiplies the efficiency and robustness of all the components of the systems that are built upon it, allowing those more visible systems to be brought to bear to maximum effect. In the context of a data processing system, the data architecture foundation provides the basis for more flexible and powerful models for data governance, easier data sharing across data sources using a robust data warehouse, and a more responsive approach towards ingesting new data feeds for business agility.
About the Author
Related Blog Posts

Multicloud chaos ends at the Equinix Edge with F5 Distributed Cloud CE
Simplify multicloud security with Equinix and F5 Distributed Cloud CE. Centralize your perimeter, reduce costs, and enhance performance with edge-driven WAAP.

At the Intersection of Operational Data and Generative AI
Help your organization understand the impact of generative AI (GenAI) on its operational data practices, and learn how to better align GenAI technology adoption timelines with existing budgets, practices, and cultures.
Using AI for IT Automation Security
Learn how artificial intelligence and machine learning aid in mitigating cybersecurity threats to your IT automation processes.
Most Exciting Tech Trend in 2022: IT/OT Convergence
The line between operation and digital systems continues to blur as homes and businesses increase their reliance on connected devices, accelerating the convergence of IT and OT. While this trend of integration brings excitement, it also presents its own challenges and concerns to be considered.
Adaptive Applications are Data-Driven
There's a big difference between knowing something's wrong and knowing what to do about it. Only after monitoring the right elements can we discern the health of a user experience, deriving from the analysis of those measurements the relationships and patterns that can be inferred. Ultimately, the automation that will give rise to truly adaptive applications is based on measurements and our understanding of them.
Inserting App Services into Shifting App Architectures
Application architectures have evolved several times since the early days of computing, and it is no longer optimal to rely solely on a single, known data path to insert application services. Furthermore, because many of the emerging data paths are not as suitable for a proxy-based platform, we must look to the other potential points of insertion possible to scale and secure modern applications.