AI data pipelines depend on fast, reliable access to massive datasets. Training and fine-tuning, as well as serving RAG workloads, requires high-performance pipelines to move data across AI model foundry workflows and storage deployments. F5 BIG-IP optimizes S3 data delivery with intelligent load balancing and deep traffic inspection, ensuring scalability, performance, and protection for AI workloads.
Enterprise AI workloads face data bottlenecks
AI models consume vast amounts of data during training, fine-tuning, and retrieval-augmented generation (RAG) workflows. These datasets are often distributed across multicloud and on-premises object storage systems. Without intelligent traffic management in the data path, organizations struggle with unpredictable latency, uneven throughput, and bottlenecks that leave GPUs idle and increase infrastructure costs.
Traditional storage networking approaches compound these challenges. Applications often connect directly to object stores, tightly coupling workloads to a single vendor’s API or region. This rigidity makes it difficult to rebalance pipelines when a cluster slows, when data must move across providers, or when regulatory mandates require storage repatriation. Each change introduces risk of downtime, data inconsistency, and costly application rewrites.
Security further complicates the picture. Sensitive training data and valuable model outputs move through shared, and sometimes untrusted, networks. Without centralized inspection and policy enforcement, organizations cannot reliably prevent dataset poisoning, unauthorized access, or exfiltration. These gaps expose AI initiatives to operational delays, compliance failures, and reputational risk.
Solve AI data delivery challenges with the F5® Application Delivery and Security Platform (ADSP)
The F5 ADSP, featuring F5 BIG-IP, provides a programmable, high-performance control point for S3-compatible data delivery. F5 BIG-IP enables loose coupling by abstracting specific storage backends from applications, allowing workloads to operate seamlessly across clouds and on-premises environments without modification. F5 BIG-IP will continuously monitor storage health and utilize intelligent DNS and load balancing to route traffic to the best-performing endpoints, ensuring pipelines stay resilient and perform predictably under heavy loads or traffic spikes.
Performance at scale is a core design point. F5 BIG-IP software running on purpose-built F5 hardware can process terabits per second of throughput, steering data across storage clusters without overloading individual nodes. Programmable traffic management allows architects to shape, prioritize, and replicate flows, preventing congestion while maximizing GPU utilization. This ensures training jobs, fine-tuning runs efficiently, and RAG queries receive data at the speed and consistency required for efficient execution.
The following diagram illustrates how F5 BIG-IP supports three critical parts of all AI data ingestion workflows (model training, fine-tuning, and RAG.) Each of these workflow components addresses foundational challenges, such as geographically distributed data aggregation, endpoint resilience, and optimized storage delivery. By utilizing capabilities like intelligent DNS routing, programmable traffic management, and advanced security enforcement, F5 ensures that AI pipelines remain scalable, reliable, and secure. This architecture maintains high performance, while protecting against data poisoning or unauthorized access across the entire data movement lifecycle.
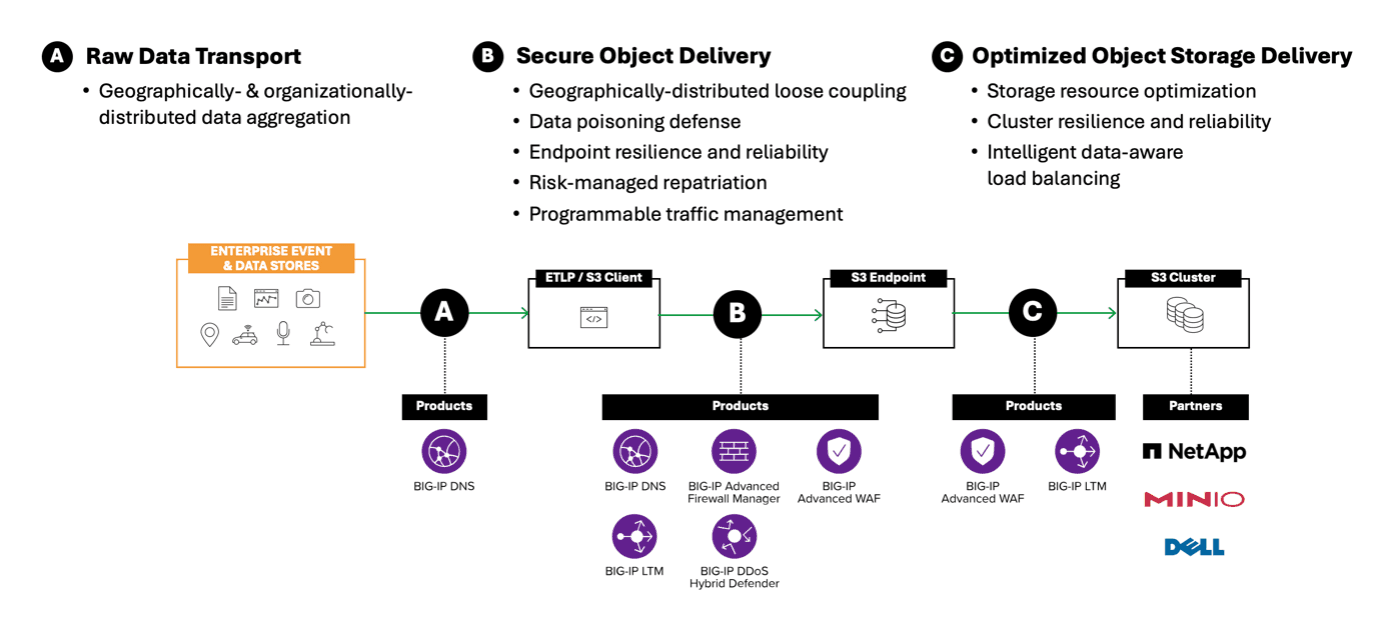
With F5, security is built in, not bolted on. F5 BIG-IP applies centralized inspection across all data ingress and egress points, blocking poisoned or malformed datasets before they contaminate pipelines. Features such as TLS termination, DDoS mitigation, and layer 7 API protection extend beyond storage vendor controls, giving organizations the governance and auditability needed for compliance with frameworks or industry-specific mandates.
It is critical to manage data flows for AI apps and prevent network congestion at high scale, particularly within core networks and across multiple locations. Scaling up to 6 Tbps in a single chassis, F5 can handle the demands of modern AI workloads, which involve increasingly complex and large volumes of data traffic. F5® VELOS® enables secure, resilient, and high-performance load balancing that optimally routes AI data across systems, ensuring rapid processing and uninterrupted availability. This means that data reaches the intended destination swiftly and securely, facilitating overall improved AI application performance.
Optimized AI data pipelines drive real business impact
With F5 BIG-IP deployed in the AI data path, organizations eliminate pipeline fragility and reduce wasted compute. GPUs stay fully utilized, job completion times shrink, and AI teams gain confidence that workloads will scale predictably as data volumes grow. By avoiding unnecessary bottlenecks, enterprises unlock faster time-to-model and improved infrastructure ROI.
Loose coupling of applications and storage means enterprises can adopt new object storage solutions, expand into new regions, or repatriate workloads from public clouds without costly rewrites or downtime. This agility translates directly into cost savings, vendor flexibility, and resilience, which are critical as AI adoption accelerates, and storage strategies evolve.
Finally, consolidating policy enforcement ensures that data integrity and compliance are never afterthoughts. F5 BIG-IP provides the visibility, observability, and enforcement architects need to assure leadership that sensitive data remains protected from end to end. The result is an AI infrastructure that is not only faster and more reliable, but also secure, compliant, and ready for enterprise scale.
KEY BENEFITS
Eliminate pipeline bottlenecks
Ensure GPUs stay fully utilized with consistent, high-performance data delivery, reducing idle compute and job delays.
Increase agility across storage environments
Decouple applications from specific storage backends, enabling seamless movement across clouds, regions, or on-premises without costly rewrites.
Strengthen data security and compliance
Protect sensitive datasets with centralized policy enforcement to block poisoning and unauthorized access while ensuring regulatory alignment.
KEY FEATURES
Enable site resilience and load balancing
Continuously monitor storage health and route traffic to optimal endpoints or sites, providing service resilience and predictable throughput.
Deploy intelligent traffic management
Shape, prioritize, and replicate flows at scale to maximize GPU utilization and prevent congestion in AI training, fine-tuning, and serving RAG workloads.
Ensure integrated security enforcement
Perform TLS termination, distributed denial-of-service (DDoS) mitigation, and layer 7 API protection directly in the data path, safeguarding pipelines on multiple levels.