
This blog post describes how to configure NGINX Open Source and NGINX Plus as a transparent proxy for traffic to upstream servers. It explains how you can use a transparent proxy to spoof the source IP address of packets to implement IP Transparency, and how you can implement a load‑balancing mode called Direct Server Return for UDP traffic.
The information in this post apply to both NGINX Open Source and NGINX Plus. For the sake of brevity, we’ll refer only to NGINX Plus.
Editor – This is the fifth in a series of blog posts that explore the new features in NGINX Plus R10 in depth.
- Authenticating API Clients with JWT and NGINX Plus
- NGINX Plus R10 Harnesses IBM POWER
- Authenticating Users to Existing Applications with OpenID Connect and NGINX Plus
- Using the NGINX JavaScript Module to Progressively Transition Clients to a New Server
- IP Transparency and Direct Server Return with NGINX and NGINX Plus as Transparent Proxy (this post)
Also be sure to check out the on‑demand webinar, What’s New in NGINX Plus R10?
Summary
NGINX Plus operates as a Layer 7 reverse proxy. This allows NGINX Plus to apply a number of optimizations and enhancements to the network requests it manages.
As a consequence, upstream (load‑balanced) servers observe that all traffic originates from an IP address on the NGINX Plus proxy. This is a challenge if the upstream server needs to determine the true origin IP address (the remote client’s), for example, for authentication or logging purposes.
There are effective workarounds for HTTP and HTTPS traffic, using either the X-Forwarded-For HTTP header or the PROXY protocol. This article describes two additional methods, which apply to TCP and UDP traffic:
- IP Transparency ensures that the upstream servers observe that each connection originates from the remote client that initiated it. It is applicable to TCP‑ and UDP‑based protocols.
- Direct Server Return (DSR) further arranges that responses from the upstream servers go directly to the remote clients and bypass the intermediate load balancer. It is applicable to UDP‑based protocols and can be implemented by performing NAT (network address translation) on the origin server or an intermediate router.
Method 1 – IP Transparency Method 2a – DSR (Router NAT) Method 2b – DSR (Origin NAT)Supported protocols TCP‑based and UDP‑based UDP‑based only UDP‑based onlyTraffic routing by upstream servers All egress traffic routed to the NGINX Plus proxy and terminated All egress traffic routed through the intermediate NGINX Plus server All traffic routed normallyPerformance Standard: egress traffic is terminated on the NGINX Plus proxy Better: egress traffic is forwarded by the intermediate NGINX Plus server Best: egress traffic is routed directly to the remote client, bypassing NGINX PlusHealth checks Passive by default; active supported Active required; passive not possible Active required; passive not possibleRequired ConfigurationTCP and UDP on NGINX Plus proxy TCP: works by default
UDP: proxy_responses 1 TCP: not supported
UDP: proxy_responses 0 TCP: not supported
UDP: proxy_responses 0How and where are packets processed? iptables terminates on the NGINX Plus proxy tc nat rewrites on the intermediate NGINX Plus server tc nat rewrites on the upstream serversNetworking configuration on NGINX Plus proxy iptables to capture egress packets IP forwarding and stateless NAT NoneNetworking configuration on upstream server Designate NGINX Plus as default route Designate NGINX Plus as default route Stateless NAT
It is complex to deploy and troubleshoot IP Transparency and DSR. Only implement these configurations if the standard reverse proxy mode of operation is not sufficient for your application or service.
Introduction: Packet Flow in a Standard Layer 7 Reverse Proxy
Unlike a switch or router that simply forwards packets, NGINX Plus operates as a Layer 7 reverse proxy. In this mode of operation, NGINX Plus manages separate client‑side and upstream‑side TCP connections (for HTTP and TCP traffic) or UDP sessions in order to control the communication between the remote client and the selected upstream server.
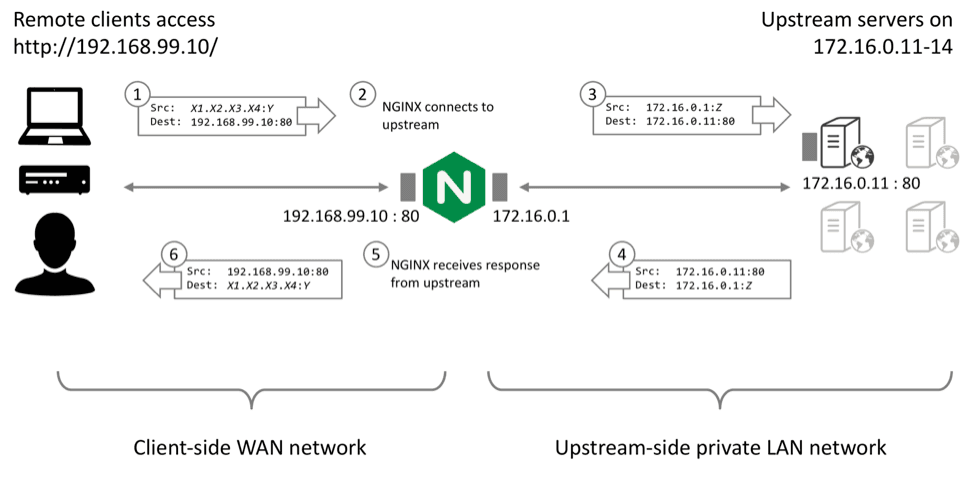
- Remote clients make TCP connections or send UDP datagrams directly to the NGINX Plus reverse proxy at its published IP address and port. NGINX Plus terminates the TCP connection or UDP session and reads the request data within.
- NGINX Plus then makes a new connection (or reuses an existing, idle connection) to the selected (load‑balanced) upstream server.
- When NGINX Plus writes the request to the upstream server, the connection originates from NGINX Plus’s internal IP address.
- When the upstream server responds to the request, it writes data to the NGINX Plus internal IP address.
- NGINX Plus receives the response data on the upstream‑side connection. It may process or modify the response (for example, apply compression to an HTTP response).
- NGINX Plus then writes the response data on the client‑side connection.
A consequence of this standard reverse proxy mode of operation is that the upstream server observes that TCP and UDP traffic originates from the local NGINX Plus proxy.
Benefits and Limitations of the Layer 7 Reverse Proxy Mode
The Layer 7 reverse proxy mode of operation brings significant performance gains and efficiencies for HTTP and TCP traffic (including TCP optimizations, buffering, and HTTP keepalive reuse). It poses a challenge if the upstream server needs to determine the true origin IP address of the connection or session, for purposes such as authentication and access control, rate limiting, and logging.
For some protocols, NGINX Plus can use the X-Forwarded-For HTTP header or the PROXY protocol to provide the origin IP address to upstream servers. This post describes two additional methods, made possible by the transparent parameter to the proxy_bind directive, which was introduced in NGINX Plus Release 10 (R10)<.htmla>.
Method 1: IP Transparency
The intention of IP Transparency is to conceal the presence of the reverse proxy so that the origin server observes that the IP packets originate from the client’s IP address. IP Transparency can be used with TCP‑based and UDP‑based protocols.
Creating an HTTP Reverse Proxy Service on the NGINX Plus Load Balancer
To demonstrate IP Transparency, we first create a load‑balanced cluster of four web servers that respond with some simple connection information.
- Configure a simple HTTP virtual server that load balances traffic across a group of upstream servers:
# in the 'http' context
server {
listen 80;
location / {
proxy_pass http://http_upstreams;
}
}
upstream http_upstreams {
server 172.16.0.11;
server 172.16.0.12;
server 172.16.0.13;
server 172.16.0.14;
}- To confirm that the upstream servers observe that the connections originate from the NGINX Plus load balancer, configure an NGINX Plus web server on each of the four of them (172.16.0.11 through 172.16.01.14) with a simple virtual server that returns information about the connection, such as:
# in the 'http' context
server {
listen 80;
location / {
return 200 "Hello from $hostname. You connected from $remote_addr:$remote_port to $server_addr:$server_portn";
}
}When we test this configuration, the upstreams report that the connections originate from the local NGINX Plus IP address (172.16.0.1):
$ for i in {1..4}; do curl http://192.168.99.10 ; done
Hello from dev1. You connected from 172.16.0.1:42723 to 172.16.0.11:80
Hello from dev2. You connected from 172.16.0.1:39117 to 172.16.0.12:80
Hello from dev3. You connected from 172.16.0.1:54545 to 172.16.0.13:80
Hello from dev4. You connected from 172.16.0.1:57020 to 172.16.0.14:80Configuring NGINX Plus and Your Upstreams for IP Transparency
NGINX Plus R10 and later (and NGINX Open Source 1.11.0 and later) can spoof the source address of upstream traffic. Include the transparent parameter to the proxy_bind directive. Most commonly, you set the source address to that of the remote client:
proxy_bind $remote_addr transparent;This simple step creates a significant challenge, however, because you need to ensure that response (egress) traffic to the remote client is correctly handled. The response traffic must be routed to NGINX Plus, and NGINX Plus must terminate the upstream TCP connection. NGINX Plus then sends the response traffic to the remote client over the client TCP connection.
You need to make several configuration changes, to both the NGINX Plus load balancer and each upstream server:
- On the NGINX Plus load balancer, configure the worker processes to run as
root, so that they can bind upstream sockets to arbitrary addresses. In the main (top‑level) context in /etc/nginx/nginx.conf, include theuserdirective to set the NGINX Plus worker processes’ ID toroot:
# in the 'main' context
# 'user daemon' is the default; change to 'user root' with transparent proxy_bind
user root;- On the NGINX Plus load balancer, ensure that each connection originates from the remote client address. Add the
proxy_binddirective with thetransparentparameter to the configuration for the virtual server:
# in the 'http' context
server {
listen 80;
location / {
proxy_bind $remote_addr transparent;
proxy_pass http://http_upstreams;
}
}- On the NGINX Plus load balancer, configure
iptablesto capture the return packets from the upstream servers and deliver them to NGINX Plus. In this example, we run theiptablesandiprulecommands to capture all TCP traffic on port 80 from the servers represented by the IP range 172.16.0.0/28:
# ip rule add fwmark 1 lookup 100
# ip route add local 0.0.0.0/0 dev lo table 100
# iptables -t mangle -A PREROUTING -p tcp -s 172.16.0.0/28 --sport 80 -j MARK --set-xmark 0x1/0xffffffff- Run the following command to list (
-L) the current configuration from theiptablesmangle table:
# iptables -t mangle -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
MARK tcp -- 172.16.0.0/28 anywhere tcp spt:http MARK set 0x1
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination- On the upstream servers, configure routing so that all return traffic is forwarded to NGINX Plus. On each upstream server, remove any pre‑existing default route and configure the default route to be the IP address of the NGINX Plus load balancer/reverse proxy. Note that this IP address must be on the same subnet as one of the upstream server’s interfaces.
# route del default gw 10.0.2.2
# route add default gw 172.16.0.1- Check that the routing table looks sensible:
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.16.0.1 0.0.0.0 UG 0 0 0 eth2
10.0.2.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
172.16.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eth2
192.168.56.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1- If your upstream servers need to be able to connect to external servers, you also need to configure the new NGINX Plus gateway to forward and masquerade traffic – see Enabling Upstreams to Reach External Servers below.
Testing the IP Transparency Configuration
You can now test the configuration by sending requests to NGINX Plus. Ensure that you are sending requests from a remote IP address that is not directly routable from the upstream servers:
$ for i in {1..4}; do curl http://192.168.99.10 ; done
Hello from dev1. You connected from 192.168.99.1:60729 to 172.16.0.11:80
Hello from dev2. You connected from 192.168.99.1:43070 to 172.16.0.12:80
Hello from dev3. You connected from 192.168.99.1:45749 to 172.16.0.13:80
Hello from dev4. You connected from 192.168.99.1:46609 to 172.16.0.14:80Observe that the connections now appear to originate from the remote client’s IP address (192.168.99.1) rather than from an address local to the NGINX Plus load balancer.
If the configuration does not work, see Troubleshooting below.
Summary: How Does the IP Transparency Configuration Work?
- NGINX Plus receives an HTTP request from a remote client (192.168.99.1).
- NGINX Plus makes a load‑balancing decision, selecting an upstream server (for example, 172.16.0.11) to connect to. Before NGINX Plus connects, it binds its upstream socket to the remote client’s address.
- The upstream server receives the connection, which appears to originate directly from the remote client.
- The upstream server responds, addressing packets to the remote client’s address and routing them through NGINX Plus (the default router).
- The
iptablesrule on the NGINX Plus load balancer marks these packets and the routing delivers them locally. - NGINX Plus reads the response.
- NGINX Plus then sends the response to the remote client.
The net result is that, from the upstream servers’ perspective, connections appear to originate directly from the remote clients.
Method 2: Direct Server Return
Direct Server Return (DSR) is an extension of the IP Transparency concept. In IP Transparency, the upstream server receives packets that appear to originate from the remote client. With DSR, in addition the upsteam server responds directly to the remote client; the return packets bypass the load balancer completely.
DSR can deliver a small performance benefit because it reduces the load on the load balancer, but it does carry a number of limitations:
- The load balancer never sees the return packets, so it cannot detect whether the upstream server is responding or has failed.
- The load balancer cannot inspect a request beyond the first packet before selecting an upstream, so its ability to make load‑balancing decisions (content‑based routing) is very limited.
- The load balancer cannot participate in any form of negotiation or stateful processing, such as SSL/TLS.
- Most other application delivery controller (ADC) features are not possible with DSR, such as caching, HTTP multiplexing, and logging.
DSR is of limited use for TCP protocols, and in any case NGINX Plus’ reverse‑proxy architecture cannot be applied to DSR/TCP.
UDP protocols are much simpler, with none of the connection semantics of TCP. You can configure NGINX Plus to support DSR for UDP protocols such as DNS, and this can deliver performance benefits. Specifically, DSR means NGINX Plus does not need to keep UDP sockets open in expectation of a response packet (which improves scalability), and response packets can bypass NGINX Plus’ Layer 7 processing completely (which reduces latency).
How Does a DSR Configuration Differ from IP Transparency?
There are three differences between an IP Transparency configuration and a DSR configuration for UDP traffic:
- NGINX Plus must spoof both the remote client IP address and port when sending datagrams to upstream servers (
proxy_bindport configuration). - NGINX Plus must not be configured to expect response datagrams from upstream servers (the
proxy_responses0directive). - An additional step is necessary to rewrite the source address of the return datagrams to match the public address of the load balancer.
Additionally, NGINX Plus must be configured to perform active health checks against the upstream servers. NGINX Plus cannot rely on its usual passive checks to verify if a server is healthy because NGINX Plus does not observe the response packets sent by the server.
Creating a Standard UDP Reverse Proxy Service
To demonstrate DSR, first create a load‑balanced cluster of four DNS servers that respond with different IP addresses for lookups of the name www.example.com.
Configure a simple reverse‑proxy configuration that load balances among the DNS servers:
# in the 'stream' context
server {
listen 53 udp;
proxy_responses 1;
proxy_timeout 1s;
proxy_pass dns_upstreams;
}
upstream dns_upstreams {
server 172.16.0.11:53;
server 172.16.0.12:53;
server 172.16.0.13:53;
server 172.16.0.14:53;
}The proxy_responses and proxy_timeout directives implement a basic health check. If an upstream server does not send 1 response within 1 second, NGINX Plus assumes that the server has failed and retries the DNS request.
Configure each DNS server to respond with its own IP address to lookups of www.example.com:
$TTL 604800
@ IN SOA ns1.example.com. admin.example.com. (
2 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
example.com. IN NS ns1.example.com.
ns1 IN A 172.16.0.11
www IN A 172.16.0.11Testing makes it clear that NGINX Plus is load balancing requests among the DNS servers:
$ for i in {1..4} ; do dig +short @192.168.99.10 www.example.com ; done
172.16.0.11
172.16.0.12
172.16.0.13
172.16.0.14Configuring NGINX Plus and Your UDP Upstreams for DSR
NGINX Plus R10 and later (and NGINX Open Source 1.11.2 and later) can spoof both the source address and port of upstream traffic. Include the transparent parameter to the proxy_bind directive:
proxy_bind $remote_addr:$remote_port transparent;This enables the upstream server to observe the full source IP address, so it can construct response datagrams that are sent directly to the remote client.
The upstream server generates response (“egress”) packets with the correct IP destination, but using its local IP address as the source address. The source address needs to be rewritten to the IP address and port of the NGINX Plus load balancer that the client originally connected to.
Two methods are possible:
- Router NAT – Rewrite the egress packets on an intermediate router (such as the NGINX Plus proxy)
- Origin NAT – Rewrite the egress packets as they leave each upstream DNS server
Both methods use the stateless NAT capability that you configure with the tc command. If the upstream servers are directly connected to the Internet (the topology means that return packets are not sent through an intermediate router you can control), then you must select the origin NAT method.
Configuring NGINX Plus for DSR
The response packets are not delivered to NGINX Plus, so you need to disable the health check you configured in Creating a Standard UDP Reverse Proxy Service: modify the proxy_responses directive and disable the proxy_timeout directive. Now NGINX Plus does not wait for responses, and does not conclude that the upstream server has failed when it does not receive them. Disabling this check also allows NGINX Plus to reuse the socket resources immediately.
Also include both the $remote_addr and $remote_port variables in the first parameter to the proxy_bind directive so that NGINX Plus preserves both the original source address and source port in the datagrams sent to the upstream servers:
# in the 'stream' context
server {
listen 53 udp;
proxy_bind $remote_addr:$remote_port transparent;
proxy_responses 0;
#proxy_timeout 1s;
}Router NAT – Rewriting the Egress Packets on an Intermediate Router
You can rewrite egress packets on a single intermediate router. For example, if the upstream servers are located on a private network behind the NGINX Plus load balancer, you can use the load balancer as a default route and rewrite the packets as they are forwarded.
- Configure each upstream server to route all outgoing traffic through the NGINX Plus server:
# route add default gw nginx-ip-address- Configure the NGINX Plus server to forward IP traffic:
# sysctl -w net.ipv4.ip_forward=1- Configure the NGINX Plus server to perform stateless NAT rewriting:
# tc qdisc add dev eth0 root handle 10: htb
# tc filter add dev eth0 parent 10: protocol ip prio 10 u32 match ip src 172.16.0.11 match ip sport 53 action nat egress 172.16.0.11 192.168.99.10
# tc filter add dev eth0 parent 10: protocol ip prio 10 u32 match ip src 172.16.0.12 match ip sport 53 action nat egress 172.16.0.12 192.168.99.10
# tc filter add dev eth0 parent 10: protocol ip prio 10 u32 match ip src 172.16.0.13 match ip sport 53 action nat egress 172.16.0.13 192.168.99.10
# tc filter add dev eth0 parent 10: protocol ip prio 10 u32 match ip src 172.16.0.14 match ip sport 53 action nat egress 172.16.0.14 192.168.99.10- Ensure that you select the appropriate egress interface and appropriate IP addresses of each upstream server.
For more information on stateless NAT, see the tc nat man page. Depending on your configuration, you might be able to reduce the tc filter commands to a single command by using CIDR masks for the src and egress old parameters.
To display the current tc filter configuration, run this command:
# tc filter show dev eth0Origin NAT – Rewriting the Egress Packets on Each Upstream Server
If you are able to configure the networking on the upstream servers, especially if they are directly connected to the Internet, you can use the following configuration. It must be applied to each upstream server.
Configure each upstream server to perform stateless NAT rewriting:
# tc qdisc add dev eth0 root handle 10: htb
# tc filter add dev eth0 parent 10: protocol ip prio 10 u32 match ip src 172.16.0.11 match ip sport 53 action nat egress 172.16.0.11 192.168.99.10Ensure that you select the appropriate interface and IP addresses on each upstream.
Testing the DSR Configuration
To test the configuration, send DNS requests to the NGINX Plus load balancer and verify that they are load balanced across the upstream servers.
DSR has no directly visible effects. You can be confident that it is working if you have used the proxy_responses 0 directive to configure NGINX Plus not to expect response packets, yet your DNS clients receive load‑balanced responses. You can further observe the packet flow using tcpdump, as described in Troubleshooting below.
Summary: How Does the DSR Configuration Work?
- NGINX Plus receives a UDP datagram from a remote client (192.168.99.1:port).
- NGINX Plus makes a load‑balancing decision, selecting an upstream server (for example, 172.16.0.11) to write the datagram contents to. Before NGINX Plus connects, it binds the local side of the upstream socket to the IP address and port of the remote client.
- The upstream server receives the datagram sent by NGINX Plus, which apparently originates directly from the remote client address and port.
- The upstream server responds, sending datagrams back to the remote client. The upstream server sets the source IP address and port of the response datagrams to its own local IP address and port.
- The source IP address (and port if necessary) is rewritten by either the upstream server (the origin NAT configuration) or an intermediate router (the router NAT configuration).
- The remote client receives the datagrams, addressed with the correct 4‑tuple (source and destination IP addresses and ports).
- NGINX Plus does not expect to observe any response datagrams, and closes the upstream socket immediately.
The net result is that response packets bypass the Layer 7 processing in NGINX Plus and go directly to the remote client.
Troubleshooting
If IP Transparency or DSR doesn’t work as expected, use the following suggestions to investigate possible causes:
Run as root
Verify that the NGINX Plus worker processes are configured to run as root. If not, you see an error message in your error log similar to the following when NGINX Plus attempts to bind the socket to a nonlocal address:
setsockopt(IP_TRANSPARENT) failed (1: Operation not permitted) while connecting to upstream, client: 192.168.99.1, server: , request: "GET / HTTP/1.1", upstream: "http://172.16.0.11:80/", host: "192.168.99.10"Test with ping
Verify you can ping clients and servers from the NGINX Plus proxy. The upstream servers cannot ping remote client IP addresses unless you first create the necessary routing configuration and configure the NGINX Plus intermediary to forward packets.
No Overlapping IP Ranges
Ensure that the IP subnets used by the remote clients are not directly connected to the upstream servers. If they are, two problems are likely to arise:
- Linux’s “reverse path filtering” protection might silently reject packets from NGINX Plus because the source IP address is associated with a subnet on a different interface.
- Return packets do not use the default route and instead are sent directly to the locally connected remote client.
Use tcpdump Everywhere
As you build up the configuration and test each intermediate step, run tcpdump continually on each and every server to verify that packets are being sent to and received by the correct endpoints at each stage:
$ sudo tcpdump -i any -n tcp port 80Investigate any unusual behavior using the checks listed below.
Check Routing Tables
Carefully check the routing tables on each server, paying particular attention to the upstream servers:
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.16.0.1 0.0.0.0 UG 0 0 0 eth2
10.0.2.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
172.16.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eth2
192.168.56.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1Are there any unexpected routes? Can you confirm that all packets in the flow will be routed to the correct destination? Recall that in the iptables and Router NAT configurations, all egress packets must be routed through the intermediate NGINX Plus proxy.
Missing Packets
If packets are unexpectedly dropped (tcpdump shows that they are sent by one machine but not received by another), reverse path filtering is a potential silent culprit. To disable reverse path filtering temporarily, run the following command:
# for f in /proc/sys/net/ipv4/conf/*/rp_filter; do echo 0 > $f ; doneEnabling Upstream Servers to Reach External Servers
If your upstream servers reside on a private network and use NGINX Plus (or another server) as their default gateway, you might wish to configure the gateway to allow the upstream servers to reach external (Internet) hosts.
You need to enable IP Forwarding so that the gateway can forward packets from the upstream servers; IP forwarding is generally disabled by default. If the servers do not have routable IP addresses (they use private addresses such as 172.16.0.0/24), you also need to configure IP masquerading on the external interfaces of the gateway server:
# sysctl -w net.ipv4.ip_forward=1
# iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADEVerify that you can ping an external server from your internal upstream server:
root@dev1:~# ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=61 time=6.72 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=61 time=5.49 ms
^CTo display your current forwarding, routing, and iptables nat configuration, run the following three commands:
# sysctl net.ipv4.ip_forward
# route -n
# iptables -t nat -LGetting Assistance from NGINX
The configuration for IP Transparency or Direct Server Return is complex, and other intermediate network devices might impact the deployment by dropping or otherwise rewriting packets. If you need assistance, NGINX’s Professional Services team is ready to help.
Explore IP Transparency and DSR with NGINX Plus for yourself – start your free 30-day trial today or contact us to discuss your use cases.
About the Author

Related Blog Posts

Automating Certificate Management in a Kubernetes Environment
Simplify cert management by providing unique, automatically renewed and updated certificates to your endpoints.

Secure Your API Gateway with NGINX App Protect WAF
As monoliths move to microservices, applications are developed faster than ever. Speed is necessary to stay competitive and APIs sit at the front of these rapid modernization efforts. But the popularity of APIs for application modernization has significant implications for app security.
How Do I Choose? API Gateway vs. Ingress Controller vs. Service Mesh
When you need an API gateway in Kubernetes, how do you choose among API gateway vs. Ingress controller vs. service mesh? We guide you through the decision, with sample scenarios for north-south and east-west API traffic, plus use cases where an API gateway is the right tool.
Deploying NGINX as an API Gateway, Part 2: Protecting Backend Services
In the second post in our API gateway series, Liam shows you how to batten down the hatches on your API services. You can use rate limiting, access restrictions, request size limits, and request body validation to frustrate illegitimate or overly burdensome requests.
New Joomla Exploit CVE-2015-8562
Read about the new zero day exploit in Joomla and see the NGINX configuration for how to apply a fix in NGINX or NGINX Plus.
Why Do I See “Welcome to nginx!” on My Favorite Website?
The ‘Welcome to NGINX!’ page is presented when NGINX web server software is installed on a computer but has not finished configuring