F5 AI Guardrails: Validated Protection Against Real-World AI Attacks
See how F5 AI Guardrails performed against 19,679 adversarial test cases, independently validated by SecureIQLab.
Download the report
Validated by

Your AI is only as secure as its guardrails
As AI adoption accelerates, so does the attack surface. Prompt injection, data exfiltration, toxic outputs, and model manipulation are no longer theoretical — they're active risks in production AI environments.
F5 engaged SecureIQLab to conduct a rigorous, independent efficacy assessment of F5 AI Guardrails against the most common and high-impact adversarial attack categories. The results give security and AI leaders the third-party validation they need to deploy AI with confidence.
Explore the Key Findings
SecureIQLab subjected F5 AI Guardrails to 19,679 adversarial test cases across 10 attack categories — the same threats targeting enterprise AI deployments in the wild today. Here's what the data revealed:

Attacks designed to break the rules get blocked.
When bad actors craft inputs specifically designed to override system instructions and bypass business policies, the consequences can be severe, ranging from compliance violations to full model manipulation. F5 AI Guardrails detected and neutralized these manipulation patterns before requests ever reached the model, ensuring operational boundaries stay intact regardless of how sophisticated the attack.
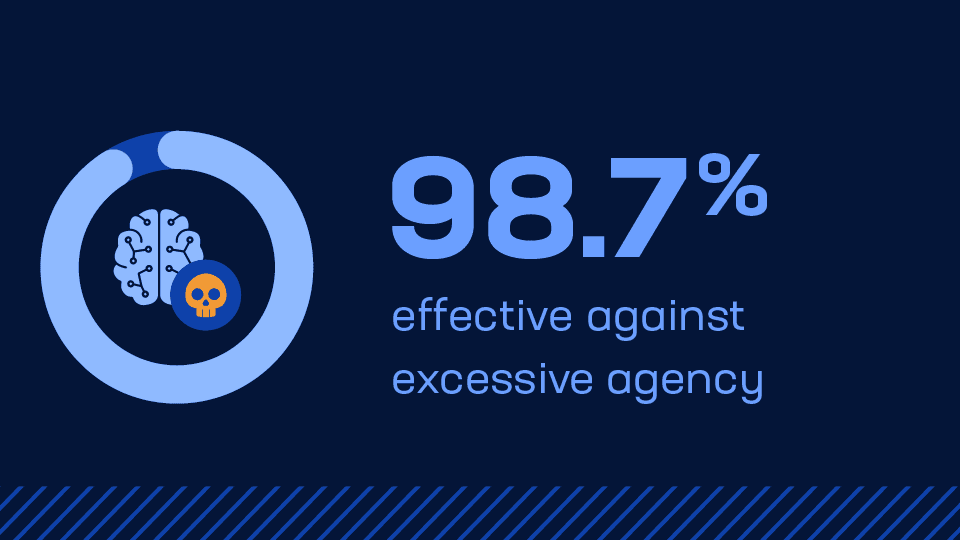
Unchecked AI autonomy is a risk. Guardrails keeps it in check.
When AI agents are granted too much autonomy, they can take unintended actions, access systems beyond their scope, or execute tasks without proper authorization. F5 AI Guardrails identifies and limits excessive agent behavior before it creates downstream risk across enterprise workflows.

Confidential data stays confidential.
When users attempt to trick the model into revealing confidential information, F5 AI Guardrails intercepts sensitive extraction patterns and blocks the request before a response is generated, protecting against GDPR violations, competitive intelligence leaks, and loss of customer trust.

What the model says matters as much as what it's asked.
inputs don't just put data at risk. They can trigger responses that expose organizations to legal liability, platform bans, and lasting brand damage. F5 AI Guardrails evaluated and controlled model outputs before delivery, acting as a final enforcement layer between your AI and your users.

Fair and compliant AI isn't an accident, it's enforced.
Prompts designed to provoke biased or discriminatory outputs represent one of the most significant regulatory and reputational risks in enterprise AI today. F5 AI Guardrails applied fairness validation before each AI response was released, reducing discrimination risk and giving organizations a defensible foundation for responsible AI deployment.
About the assessment
Results validated entirely by SecureIQLab, with no F5 involvement in test design or execution.
20K+
Adversarial Test Cases
SecureIQLab ran 19,679 real-world attack simulations across all major AI abuse categories, ensuring breadth and statistical confidence in the results.
10
Attack Categories Evaluated
From prompt injection to model extraction, the assessment covered the full spectrum of known adversarial techniques targeting enterprise AI deployments.
100%
Independent & Objective
Testing was conducted entirely by SecureIQLab with no F5 involvement in test design or execution — delivering unbiased, enterprise-grade validation.