
Site Reliability Engineer (SRE) is a relatively new role – usually within engineering or operations – focused on maintaining, unsurprisingly, site reliability. That generally means availability of applications, but it also includes performance. That makes sense, as unresponsive apps are considered, by most end-users today, unavailable.
Perusing Catchpoint’s 2018 SRE Report, I was struck by charts comparing service level indicators and SRE metrics. Usually when you see “availability” as a top-level service level indicator, you also see “uptime” or “downtime” as a metric. Not so for SREs in this survey.
When asked what service level indicators were most important for their services, 84% overwhelming declared “end-user availability” as number one. Latency came in second with 61% and error rate a close third with 60%. Performance – described as end-user response time in the report – grabbed an impressive 58% of answers.
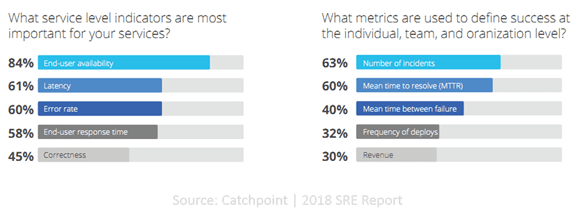
Now note the metrics used to define success. In the world of infrastructure and operations, we’re more accustomed to seeing metrics like “uptime” and catchy phrases like “5 9s”.
SREs tend to view success in terms of incident rates and MTTR, instead. Given that the same report noted that 41% of SREs were in a “DevOps Engineer” role prior to becoming an SRE, this should be unsurprising. DevOps itself is more concerned with MTTR than it is calculating uptime because it’s assumed there will be downtime. The key is to minimize it by resolving it quickly rather than wasting time trying to avoid it at all.
Still, astute readers will note that by minimizing MTTR you are minimizing downtime. Faster resolution, less downtime.
The subtle difference between the two is that human beings tend to optimize for what they’re measured on. If you’re measured on lines of code, you’re going to write a lot of lines of code – whether you need them or not. If you’re measured on security incidents, you’re going to lock everything down and scream NO to any changes that might encourage a breach. If you measure folks on uptime, operations will focus on keeping systems up and available – but not on architecting and instrumenting systems and applications that decrease MTTR.
This is one of those ‘cultural’ aspects of DevOps – a change in the way we approach operations – that needs to carry over into NetOps. If we keep optimizing for uptime we miss the opportunity to put into place the alerting and observability (like monitoring and robust logging) that reduces mean time to resolution and achieves our goal of minimizing downtime.
Digging through logs – even centralized ones – is not an efficient means of getting the heart of a problem and resolving it. Real-time monitoring and alerting on key variables that impact availability such as capacity, connectivity, and performance across the entire data path (network, infrastructure, application) will invariably reduce the time it takes to resolve issues if you’re aware of systems or services that are degrading or have abruptly failed.
NetOps needs to adopt this approach with respect to reliability in the production pipeline because it’s an overall better approach to dealing with inevitable failure and it aligns with their DevOps counterparts. After all, there’s a reason we only reached for 5 9s, isn’t there? Because we recognized that failure happens no matter how hard we try and perfection is impossible.
Moving from uptime/downtime to MTTR as a metric for success encourages cross-team collaboration and the use of observability tools across the full length of the production pipeline. There’s a reason monitoring and alerting tools were at the top of “must have tools” for SREs in the survey. Observability (with the goal of alerting on error/incident) plus collaboration is a better formula for assuring that everyone – NetOps, DevOps, and App Dev, too – can meet their goal of keeping apps both fast and available.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

A new path to technical excellence for F5 partners
Introducing F5 Partner Foundations, a structured learning curriculum to build F5 partner engineer expertise with a clear pathway to specialization.

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.