
I have expounded before why it is that application security is a stack. I say this again because sometimes we need a reminder that modern applications are never deployed alone. They aren’t.

Every modern application is deployed on some sort of platform. That could be Apache or IIS. It could be an Oracle or IBM application server. Could be node.js with Express or Python with all the necessary libraries. Just as we rely on operating systems and virtualization/containers to provide networking for us, applications rely on platforms and libraries to handle things like TCP and HTTP.
Additionally, developers use libraries for functionality. Reinventing the wheel is a waste of time, and so developers turn to open source and other avenues for JSON parsers, file management, authentication and authorization and database support. UI layout and management, too. Today most developers turn to libraries to provide these functions, so they can focus on what adds value: business logic and services.
A 2017 inspection of applications by Contrast Labs found that “third-party software libraries represent 79% of an application’s code.” For Java, the average was 107 different libraries. For .NET? 19. Anecdotally, I’m using at least five different libraries with node.js.
But what ought to raise your eyebrows is what they discovered about the state of security with respect to this split.
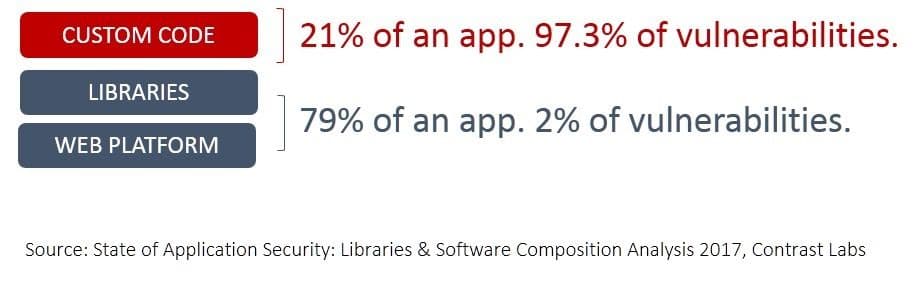
Even though 79% of an app is comprised of libraries, it only accounts for 2% of known vulnerabilities (that’s CVEs). Custom code represents pretty much the rest, with 97.3% of vulnerabilities.
This disproportionate sourcing-security risk between libraries and vulnerabilities might explain why a SANS survey found “even though 23% of respondents rely heavily on third-party software products and services (COTS, cloud-based services and open source software), they are not taking enough responsibility for ensuring the security of third-party solutions. Only 23% of security programs include COTS.”
Hmmph. Well then, that might explain the poor response rate to vulnerability resolution as reported by Kenna Security. Back in 2015, Kenna Security reported on research conducted on a sample of 50,000 organizations with 250 million vulnerabilities and over one billion (BILLION) breach events and found two very interesting points with respect to vulnerability remediation:
- On average, it takes businesses 100-120 days to remediate vulnerabilities.
- At 40-60 days, the probability that a CVE will be exploited reaches over 90 percent.
- The gap between being likely exploited and closing a vulnerability is around 60 days.
In other words, most organizations aren’t addressing those 2% of vulnerabilities fast enough to avoid being compromised by one. Perhaps because they’re located in libraries that aren’t included in the organization's security program.
Regardless of why that is, it needs to be priority one. And let me explain why.
Back in the day, attackers had to:
- Find out about the vulnerability
- Seek out a victim site
- Attempt to execute an exploit
This was manual and time-consuming. Unless you were a high-profile target, no one was going to waste their time on you.
Today, vulnerabilities are shared at the speed of the Internet (which is the speed of light, in case you were wondering. Optic backbone, you know) and target discovery is automated. Scripts and bots are capable of seeking out and marking sites for compromise much faster (and cheaper) than people. It’s the same way Death Star-sized botnets get built out of unsecured IoT devices. Automation isn’t just improving the productivity of the good guys.
These are non-targeted attacks. Attacks of opportunity, if you will, that aren’t planned. You might not have data that’s valuable or interesting, but you do have resources. And resources can be used to find other victims and perpetrate other attacks and, well, you know how this ends.
Non-targeted attacks are especially common after the publication of a CVE. That’s because your custom code is unique; while there are plenty of vulnerabilities in it, it takes time and effort to find them. Exploiting a CVE that exists in a commonly used library or platform is easy peasy, lemon squeezy. The opportunity is too good to pass up, because the return on investment is high, high, high. The Verizon DBIR in 2015 noted that “70% of attacks exploited known vulnerabilities that had patches available.”
That’s why patching – either through actual software updates or virtually through the use of a web application firewall – should be Priority One upon the disclosure of a new CVE in any of the 79% of libraries that make up your application. If that CVE is related to the platform (think Apache Killer), it better be Priority “Drop Everything”, because fingerprinting web and app servers is even easier than scanning for vulnerabilities in libraries.
The truth is that if you aren’t high-profile enough to be targeted, you’re still at risk. You’re probably using the same stack as high-profile organizations, and that means non-targeted attacks are likely to find you. If you think they won’t, consider that I can go on over to the CVE database and find all published CVEs related to node.js. Then I zip on over to builtwith.com and search out websites built with Express – a node.js framework. Not only do I discover the site knows of “230,116 live websites using Express and an additional 263,872 sites that used Express historically” but also conveniently provides a link to download them.
It’s not quite the shodan.io of web apps, but it’s not much harder to put two and two together and come up with successful exploit.
So don’t make the mistake of thinking that because you aren’t “big enough” that a CVE in a library or web platform can be ignored.
That’s how folks end up trending on Twitter. And not in a good way.
Be safe. Prioritize responses to CVEs that affect your entire app stack. From top to bottom.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.
F5 joins the Dell AI Ecosystem Program to help enterprises operationalize AI
F5 joins the Dell AI Ecosystem Program to help enterprises deploy production AI with greater performance, security, and control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.